[3] Journey of a single token through the LLM Architecture
Mayank Pratap Singh
@Mayank Pratap Singh
![[3] Journey of a single token through the LLM Architecture](/_next/image?url=%2Fimages%2Fblog%2FJourney_of_a_single_token.png&w=1920&q=75)
Table of Contents
- Introduction – Overview of how a token moves through an LLM.
- Token Journey Analogy – Comparing token processing to fuel in an engine.
- Phase 1: Isolation – Separating tokens from their context.
- Phase 2: Token ID Assignment – Assigning a unique ID to each token.
- Phase 3: Token Embeddings – Transforming tokens into numerical vectors.
- Phase 4: Positional Embeddings – Encoding token positions in a sentence.
- Phase 5: Input Embeddings – Merging token and positional embeddings.
- Transformer Block – Processing tokens with attention and feed-forward layers.
- Output Layer – Predicting the next token based on probabilities.
- Conclusion – Summarizing the token’s journey and LLM advancements.
Introduction
In this blog, we will embark on an exciting journey—following a token as it moves through the LLM architecture. By doing so, we’ll uncover the inner workings of these powerful models, from tokenization to embedding, attention mechanisms, and final output generation. This exploration will provide a glimpse into the fascinating process that enables LLMs to understand and generate human-like text.
The Journey of a token (word) through the LLM architecture
 Figure 1: Journey of a fuel in engine (used as an analogy for token journey in LLMs)
Figure 1: Journey of a fuel in engine (used as an analogy for token journey in LLMs)
Imagine you are a drop of fuel entering a powerful engine. As you move through its intricate system, you're transformed—compressed, ignited, and ultimately converted into energy that propels the machine forward. By following your journey, we can understand how the engine works.
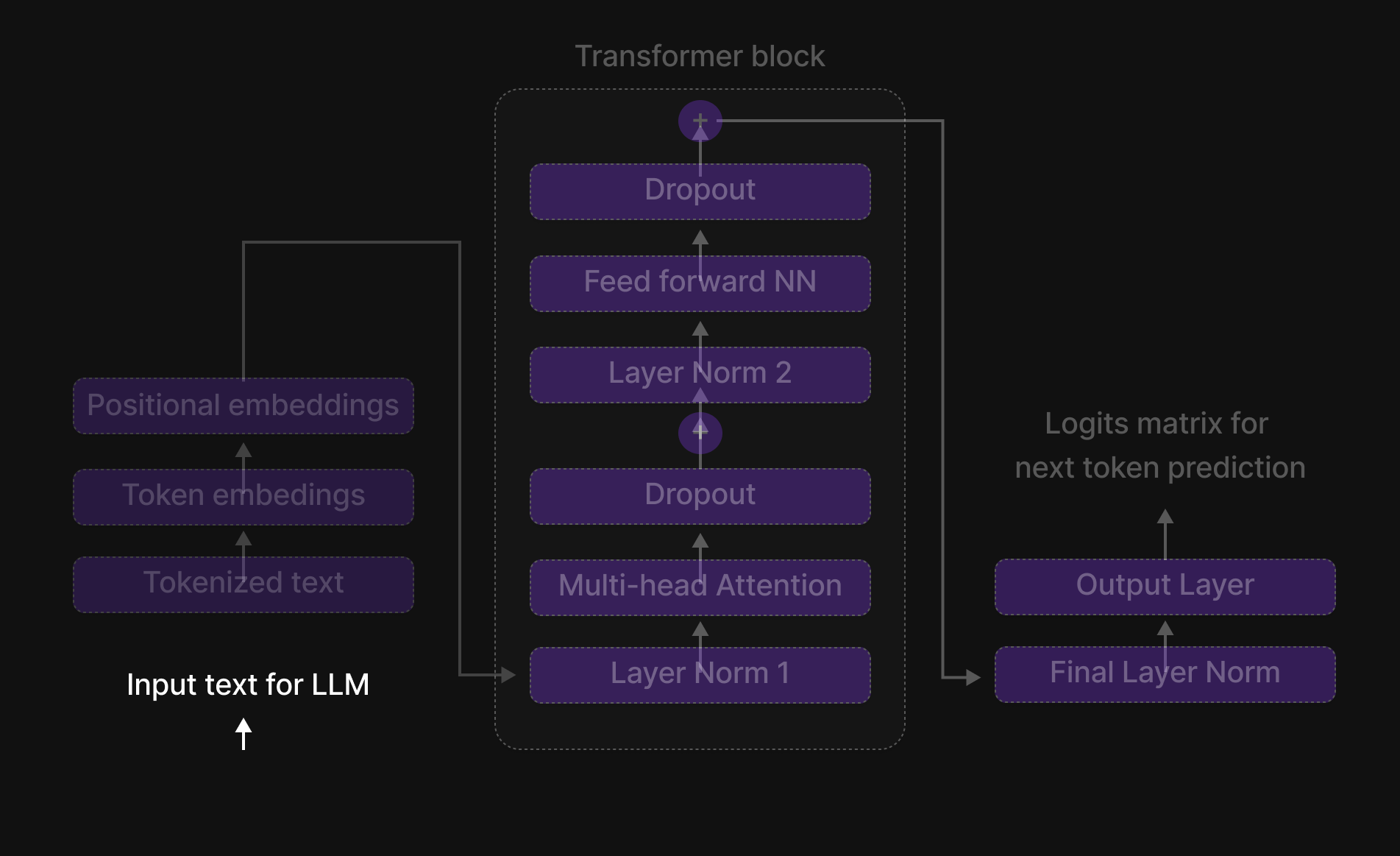 Figure 2: Think yourself as token)
Figure 2: Think yourself as token)
Now, let’s shift this analogy to Large Language Models (LLMs). Instead of fuel, think of yourself as a token—a word or part of a word—entering the LLM’s neural engine. What happens to you inside? How are you processed, refined, and ultimately used to generate meaningful text?
In this story, you are the token, surrounded by other words, waiting to be processed. You are about to be thrown into the vast architecture of an LLM. As we step into your shoes, we will follow your journey through every stage of this complex system—seeing how you evolve, interact, and contribute to the final output.
So we have gone to GPT and ask to generate a random paragraph about “friends”
Friends are the people who bring joy, support, and understanding into our lives. They share in our laughter, stand by us in tough times, and offer a listening ear when needed.A true friend accepts you for who you are, encourages your growth, and adds meaning to your experiences. The bond between friends is built on trust, shared memories, and mutual respect, creating a relationship that enriches both individuals' lives.
"A true friend accepts you"Let's say we are looking at the above sentence, which is a sequence of five words, and we need to predict the next word.
We are specifically focusing on the word friend.
Tokens and words are not the same, but for the sake of simplicity, we will use them interchangeably.
 Figure 4: familiar word neighbours
Figure 4: familiar word neighbours
Imagine you are surrounded by your familiar neighbours—"a," "true," "accepts," and "you." Just like a close-knit group of friends, you have always existed alongside them, forming a meaningful connection within a sentence.
But now, something unexpected happens.
As you enter the LLM processing pipeline, the first step is isolation.
Phase 1: Isolation
Suddenly, you are detached from your neighbours. The model no longer perceives you as part of a full sentence but instead examines you individually.
This marks the first critical stage of input processing, where each token is separated from its context before undergoing further analysis.
Phase 2 : Token ID assignment (Getting your badge)
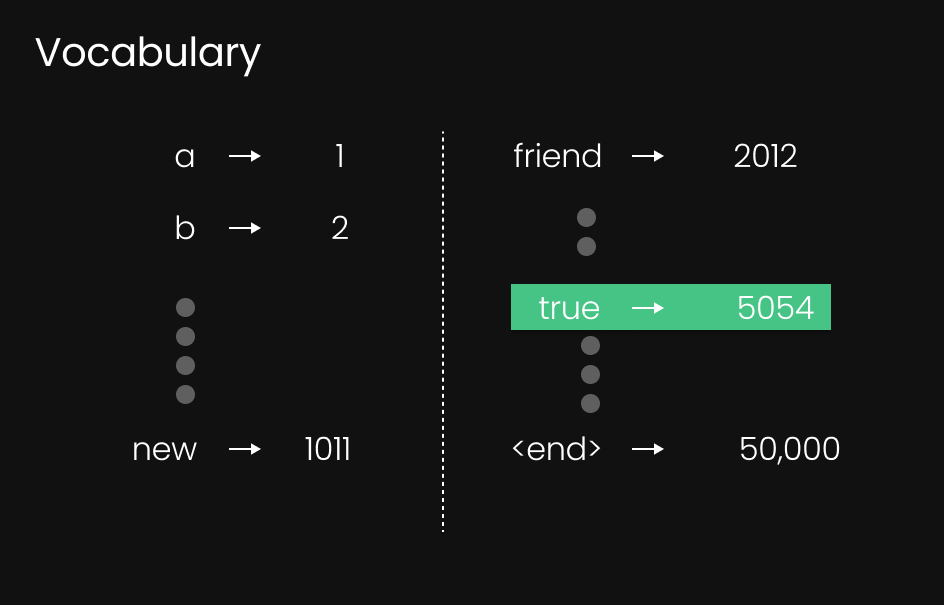
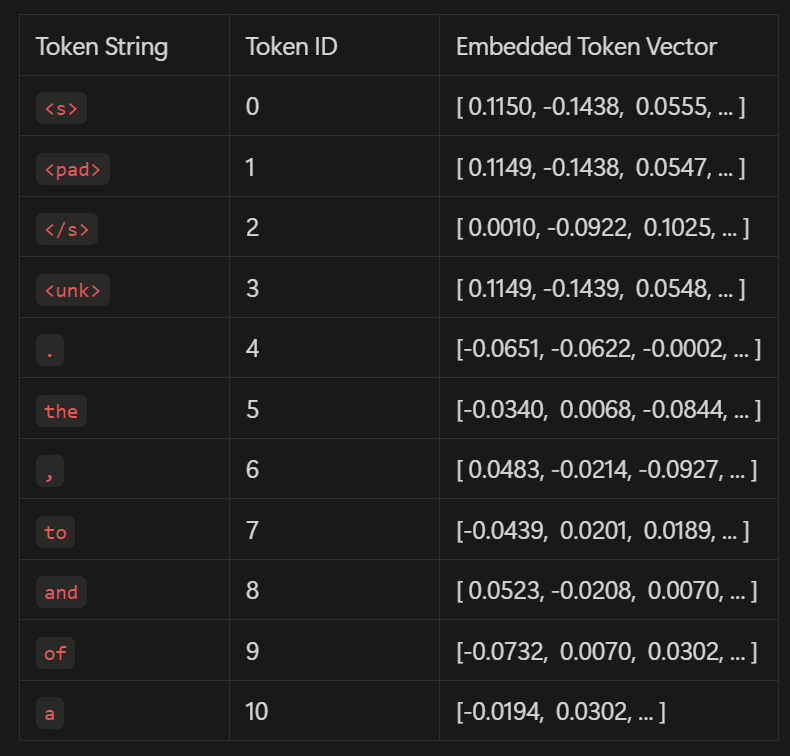 Figure 6: Example of Token ID lookup table
Figure 6: Example of Token ID lookup table
Once a token has been isolated, the next step in the LLM processing pipeline is assigning it a unique identity. Think of it as enrolling in a school, military, or summer camp—each participant receives an ID badge to distinguish them from others. In the same way, every token is assigned a Token ID, which acts as its unique identifier.
The model maintains a book of token IDs, similar to an encyclopedia of all possible tokens. This book contains:
- Characters – Individual letters like A, B, C … up to Z.
- Words – Common full words like "token," "enter," "begin.".
- Subwords – Fragments of words, such as "-ation" or "un-", which can be useful for processing complex vocabulary.
Each token—whether a full word, subword, or character—is given a numerical ID from this book. For instance, the word "friend" may be assigned an ID like 2012, depending on the model’s vocabulary.
Why Token IDs Matter

Tokenization schemes, such as Byte Pair Encoding (BPE), help create and maintain this vocabulary of tokens. Different models have different vocabulary sizes:
- GPT-2 has around 50,000 tokens in its vocabulary.
- GPT-4 might have a much larger vocabulary, possibly 100,000 or more.
The Token ID ensures that each word (or part of a word) is uniquely identified, allowing the LLM to efficiently process and predict text. This step lays the foundation for deeper understanding and generation, as each token moves through the rest of the model’s architecture.
now you have been assigned a badge—a unique Token ID that gives you an identity within the system.
With this roll number, you are now ready to move to the next phase of your journey through the LLM architecture. Phase 3
Phase 3 Token Embeddings Assignment (Entrance Exam)
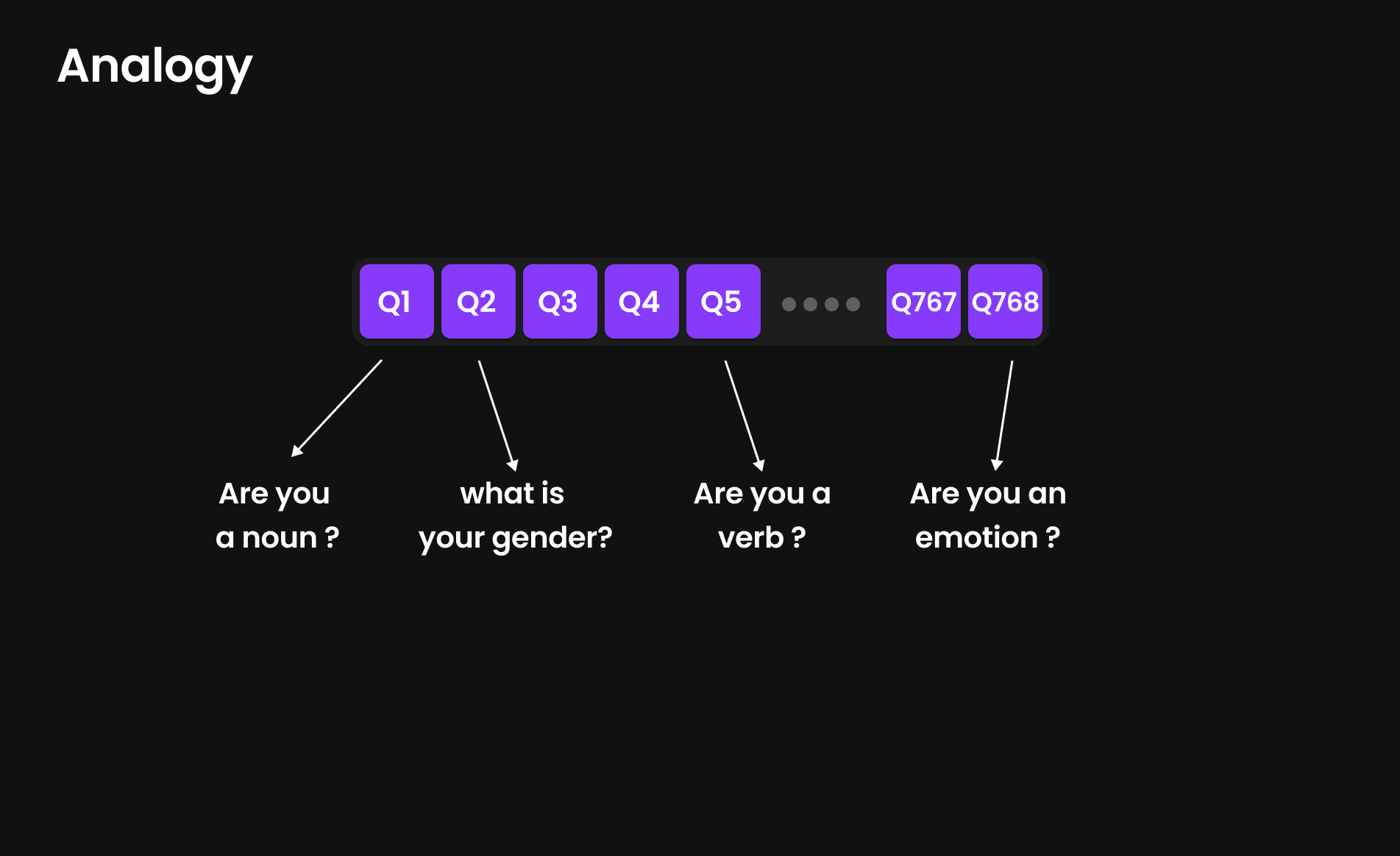
Analogy for Token Embeddings: The Entrance Exam for Tokens
Imagine you are a student taking an entrance exam for a prestigious university. The exam consists of 768 questions, each testing different aspects of your abilities, background, and personality.
Some of the questions might be:
- Are you good at math?
- Do you enjoy sports?
- Are you more analytical or creative?
- Are you fluent in multiple languages?
At the end of the exam, your responses create a detailed profile of who you are, helping the university understand your strengths, weaknesses, and unique traits.
Now, let’s apply this to token embeddings in an LLM.
Every token (word or sub-word) goes through a similar questionnaire, but instead of testing academic skills, the model asks:
- Are you a noun, verb, or adjective?
- Are you related to emotions?
- Do you frequently appear at the start or end of sentences?
- Are you connected to monarchy (e.g., king, queen, princess)?
Each token answers 768 hidden questions, forming a unique vector representation—a numeric fingerprint that encodes its meaning, context, and relationships with other words.
Unlike Token ID Assignment, which simply gives a word a name tag, Token Embeddings give it an identity, helping the model understand its meaning rather than just recognizing it as a word in a dictionary.
Just as an entrance exam helps a university categorize students into different academic fields, token embeddings help the LLM classify and understand words within a broader linguistic structure.

For instance, if a model like GPT-2 Small uses 768 dimensions, then each token will be represented as a vector of 768 numerical values—each value capturing a different aspect of its meaning and relationship with other words.
However, this number of dimensions is not fixed across all LLMs. Different models define their embedding sizes based on their complexity and intended depth of language understanding.
- GPT-2 Small → 768 dimensions
- GPT-2 XL → 1600 dimensions
- Larger models → even higher dimensions
This means that when a token is processed by different LLMs, it may be evaluated on a different number of linguistic and contextual features. A token processed in GPT-2 Small may have 768-dimensional representation, while the same token in a more advanced model could have 1600 or more dimensions, enriching its contextual understanding.
By adjusting embedding dimensions, models balance efficiency and depth of representation, ensuring that tokens capture enough linguistic detail while keeping computational costs manageable.
So, along with your badge (Token ID), you also carry your result—your embedding values
Token embedding is a crucial step in LLMs as it extracts the meaning of each token, enabling the model to understand language beyond just assigning IDs. Each token is analyzed through a set of features (e.g., whether it’s a noun, verb, or related to a specific concept), resulting in a 768-dimensional vector (for GPT-2 Small). This vector acts as the token’s identity, capturing its semantic and contextual properties, which the model uses for language processing and next-token prediction.
Phase 4 : Positional Embedding
Your position among neighbours matters !
While Token Embeddings help capture the meaning of a token, they do not preserve its position in a sentence. However, in language, the order of words is crucial for meaning. This is where Positional Embeddings come into play—they allow the model to differentiate identical words appearing in different places and help it understand sentence structure.
Consider the phrase:
A true friend accepts you.Here, each word has a specific position in the sentence

The word "friend" occurs at position 3. Without positional encoding, the model would treat all instances of "friend" as identical, regardless of where they appear. However, in natural language, word order significantly impacts meaning, so the model needs to encode position information alongside the token embeddings.
Let’s consider another sentence
The dog chased another dog.
In this case, both instances of "dog" refer to different entities. The first "dog" at position 2 is the subject, while the second "dog" at position 5 is the object.

If we only relied on token embeddings, the model would treat both "dog" tokens the same, failing to capture the sentence’s actual meaning. Positional embeddings solve this by assigning different positional values, helping the model distinguish between identical words appearing in different contexts.
How Positional Embeddings Work
Just like token embeddings have 768-dimensional representations, positional embeddings also use 768 dimensions (in GPT-2 Small) to encode positional information. The model processes questions such as:
- Is this token at the beginning of the sentence?
- Is it positioned towards the middle or end?
- Does it encode long-range dependencies?’
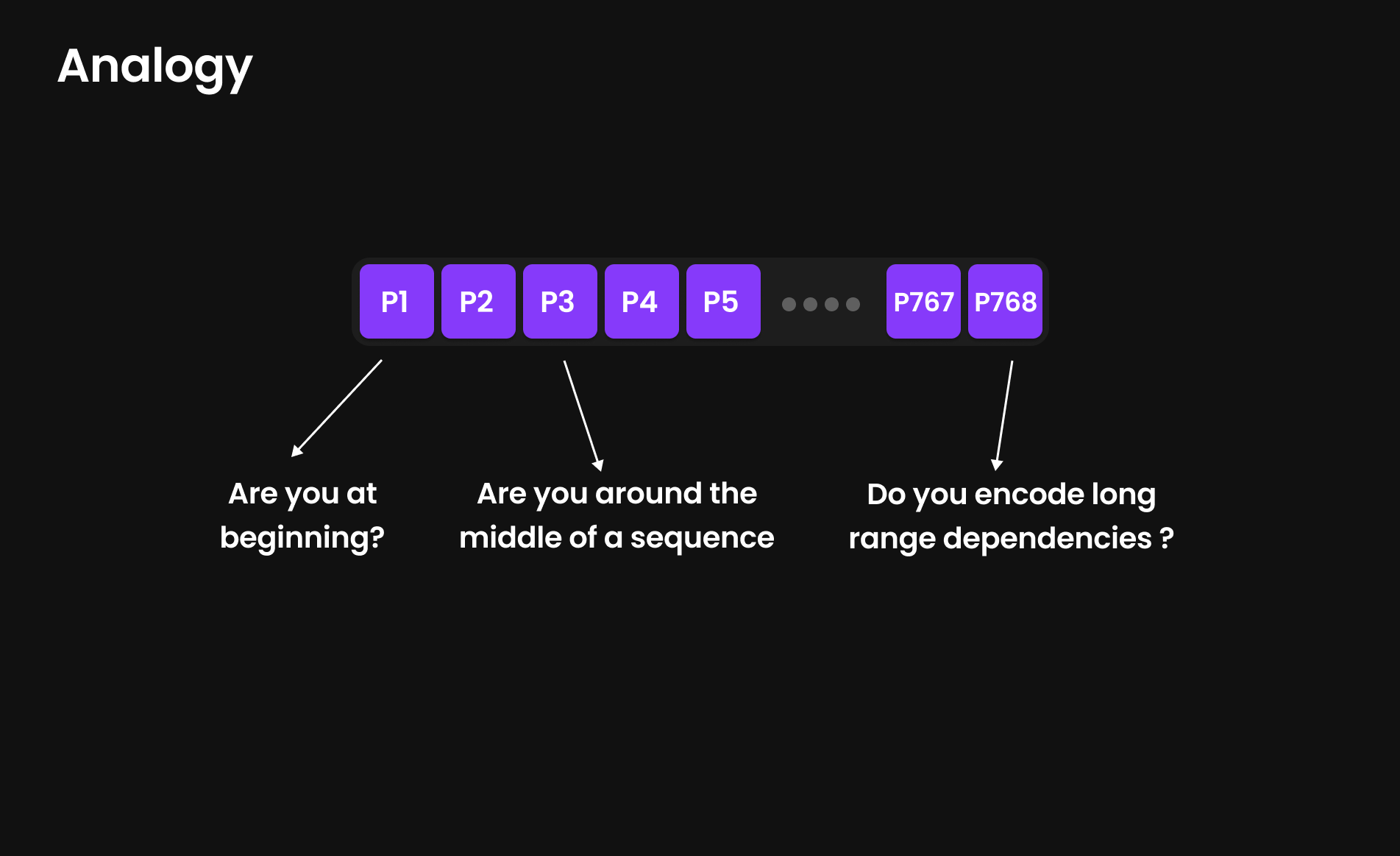
But we don’t know exactly what are these questions, they even not are questions , we use this analogy to simplify the explanation.
Each token is thus assigned two embeddings:
- Token Embedding – Capturing its meaning.
- Positional Embedding – Capturing its placement in the sentence.
By combining both, the model learns not just what words mean but also where they appear, enabling it to understand syntax, grammar, and sentence structure effectively.
Phase 5: Add the results of token + positional Embeddings
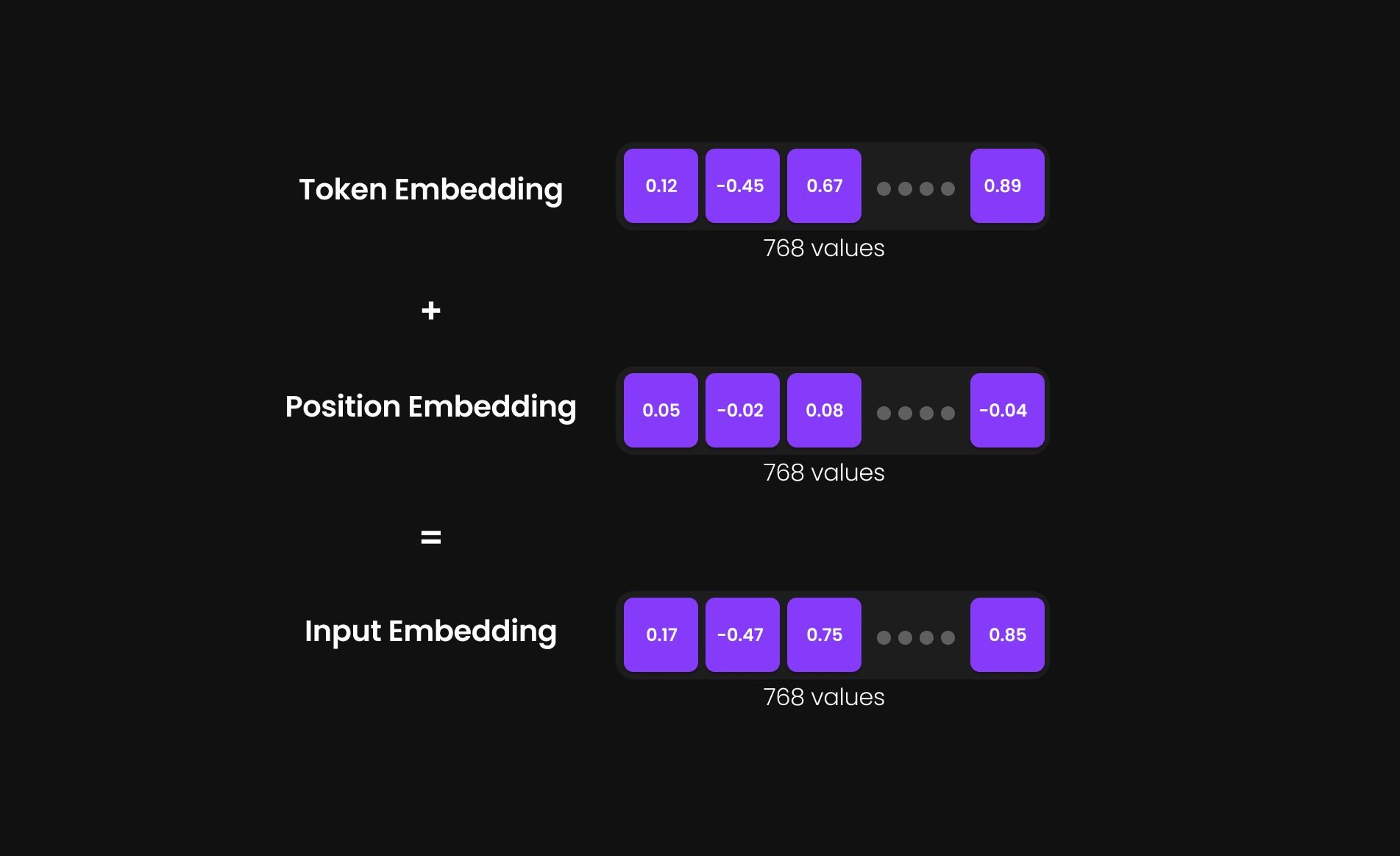
How Input Embeddings Are Formed
Each token now has two separate 768-dimensional vectors (in GPT-2 Small):
- Token Embedding (768-D Vector) – Encodes the meaning of the token.
- Positional Embedding (768-D Vector) – Encodes its position in the sentence.
Instead of carrying both separately, these two vectors are added together to form a single 768-dimensional Input Embedding.
Input Embedding = Token Embedding + Positional Embedding
This merged representation allows the model to process each token as a unique entity with both semantic meaning and positional context.
Finally after going through all the steps there is this one thing that is Input Embedding That distinguishes the word from others
Think of Input Embedding as a custom-made uniform for each token. Every token in a sentence wears a unique uniform, tailored specifically for it.
Why is each uniform different?
- The fabric (Token Embedding): Represents the token’s meaning—whether it’s a noun, verb, or an abstract concept.
- The size and fit (Positional Embedding): Represents its position in the sentence—whether it appears at the beginning, middle, or end.
Since every token has a different meaning and appears in a different position, each one receives a distinct uniform. This uniform, or Input Embedding, is what the token carries as it moves through the LLM processing pipeline, ensuring that the model recognizes both what the word means and where it appears.
The Harry Potter Analogy
Imagine stepping into Hogwarts, the legendary school of magic, but before you can enter, you must first be sorted into a house—Gryffindor, Ravenclaw, Hufflepuff, or Slytherin. Each student receives a house robe, representing their identity and role within the school.
Similarly, in an LLM, every token must first receive its uniform—its Input Embedding—before it can enter the Transformer Block, where the real magic happens. The model does not inherently understand words or their meanings; it only recognizes high-dimensional numerical representations (vectors) assigned to each token.
Once properly suited, tokens are finally ready to board the train to the Transformer Block, where they will interact, influence one another, and ultimately shape the model’s understanding of language—just like young wizards learning the ways of magic at Hogwarts.
Summary of the Input Block
The Input Block is the first stage of an LLM’s processing pipeline, where raw text is transformed into numerical representations that the model can understand. This phase consists of five key steps:
- Tokenization: The input sentence is split into tokens (words or sub-words).
- Token ID Assignment: Each token is assigned a unique ID from the model’s vocabulary.
- Token Embedding: A 768-dimensional vector (for GPT-2 Small) is assigned to capture the token’s semantic meaning.
- Positional Embedding: Another 768-dimensional vector is assigned to encode the token’s position within the sentence.
- Input Embedding Formation: The Token Embedding and Positional Embedding are combined, creating the final Input Embedding, which the model will use for processing.
At this stage, each token has received a distinct identity—akin to a school student wearing a custom uniform. Now, the tokens are ready to enter the Transformer Block, where deeper processing, attention mechanisms, and language modeling take place.
The Heart of the LLM: Introduction to the Transformer Block
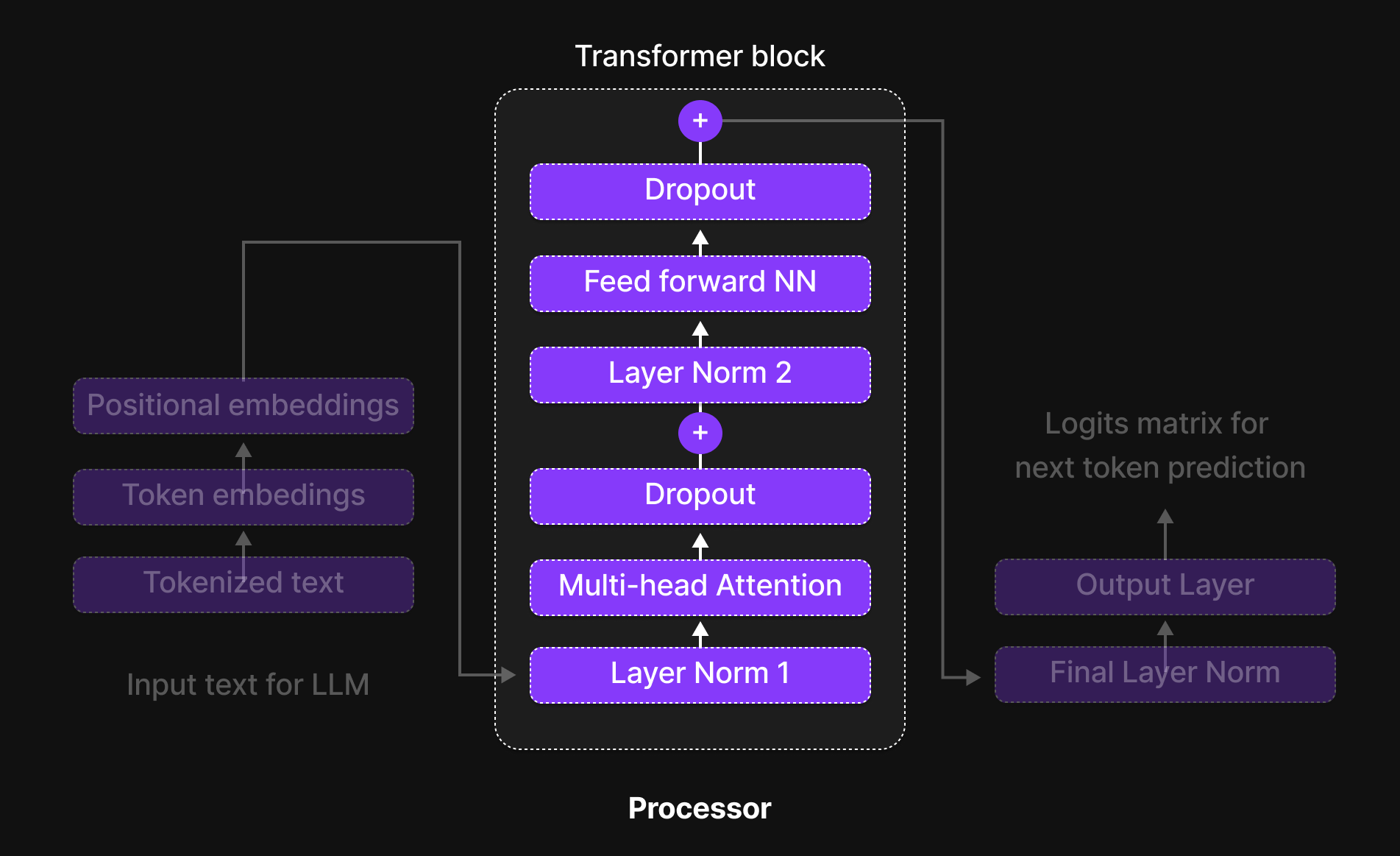 Figure 14: Transformer block
Figure 14: Transformer block
The Transformer Block is where tokens interact, exchange information, and refine their contextual understanding. It is the true brain of the model, allowing it to capture relationships between words, recognize long-range dependencies, and learn intricate language patterns.
Now that our tokens have received their uniforms (input embeddings) and are ready for processing, let's step inside the Transformer Block, where the real magic happens.
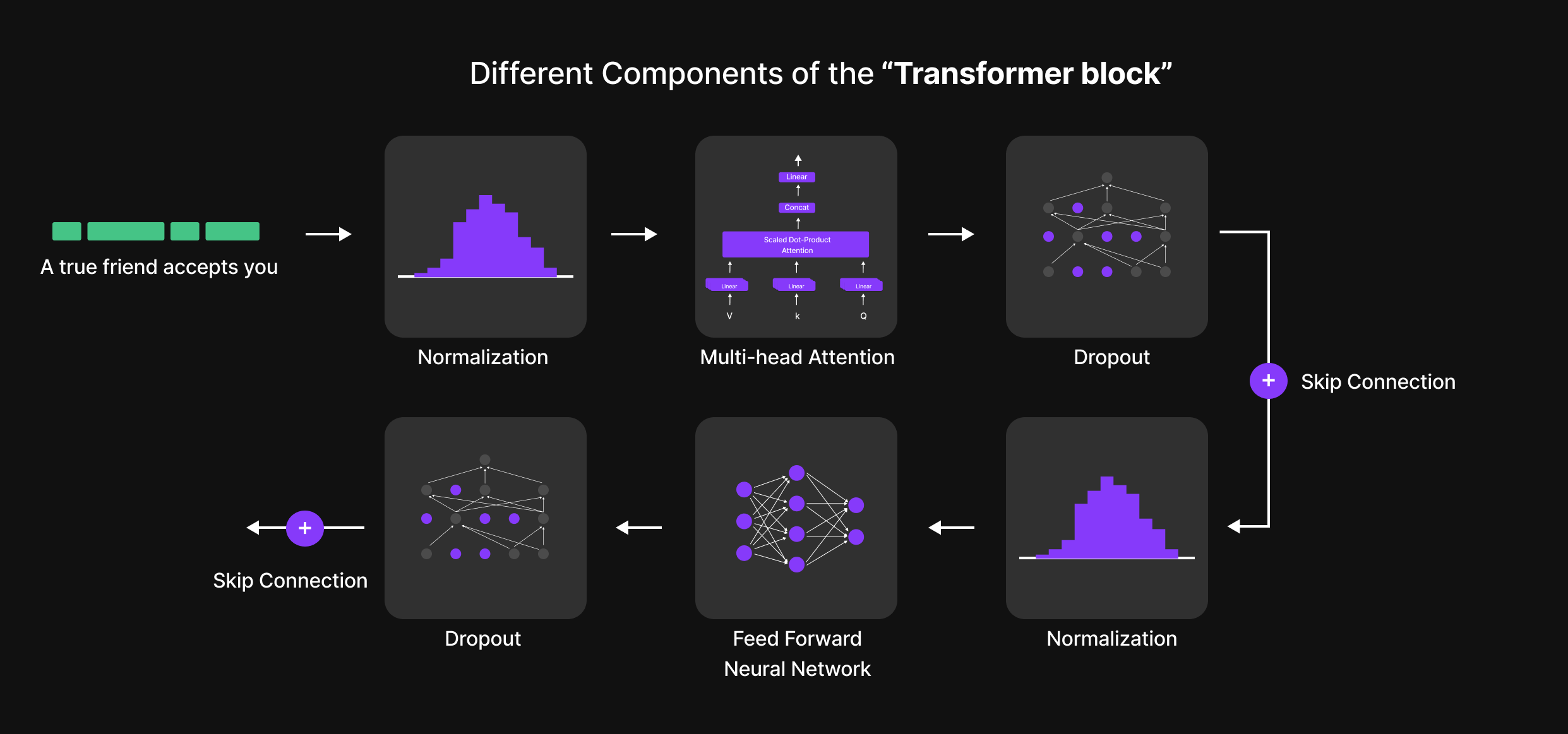
The Six Key Steps of the Transformer Block
Inside the Transformer Block, every token undergoes a structured six-step process that refines its representation and enhances contextual understanding. These steps are:
- Normalization (Layer Normalization)
- Multi-Head Attention
- Dropout (Regularization Step 1)
- Feed-Forward Neural Network (FFN)
- Dropout (Regularization Step 2)
- Normalization (Final Layer Normalization)
Additionally, Skip Connections (residual connections) are used throughout the block to ensure smooth information flow and prevent vanishing gradients.
This structured sequence is repeated across multiple Transformer Blocks, allowing the model to learn complex language patterns and relationships.
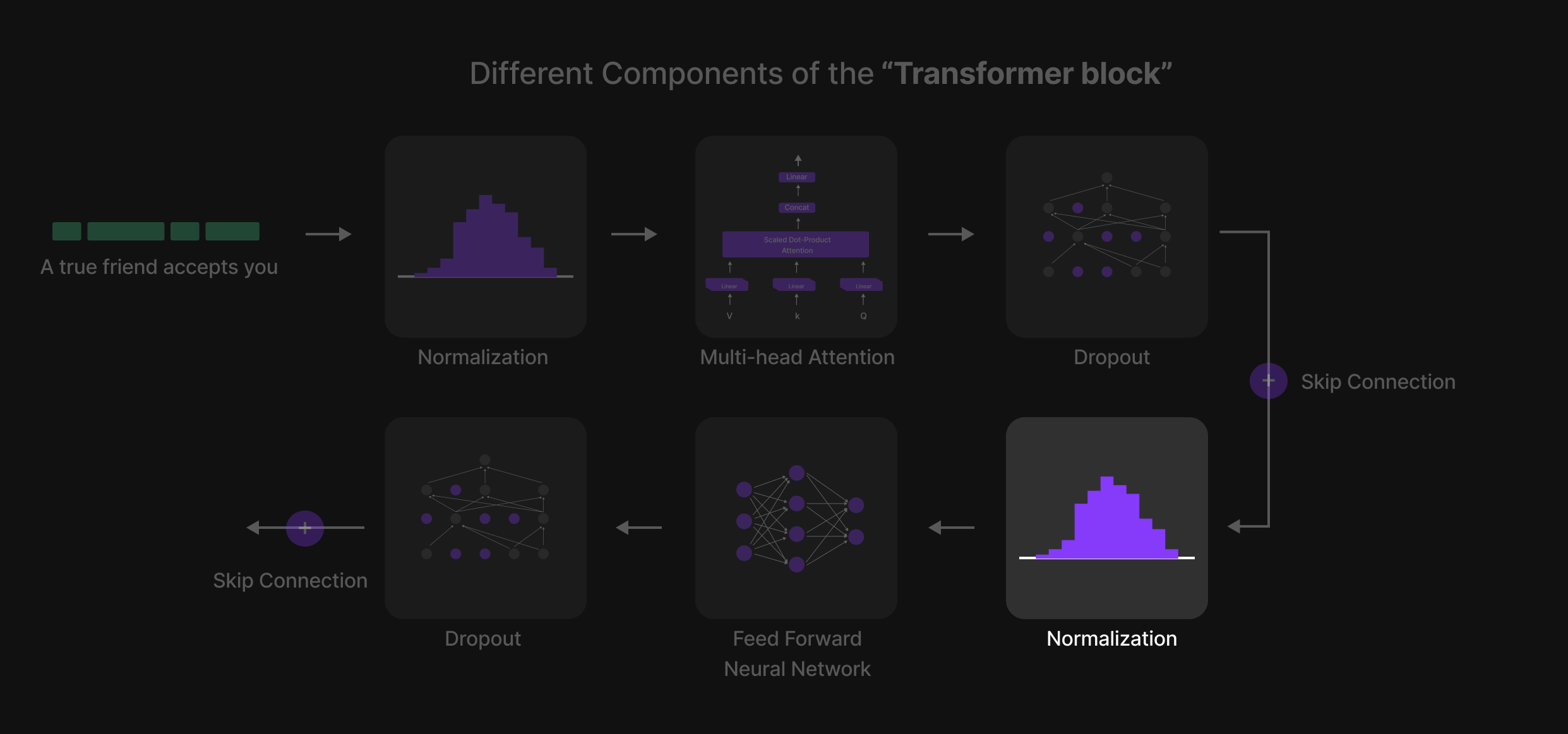
Normalization
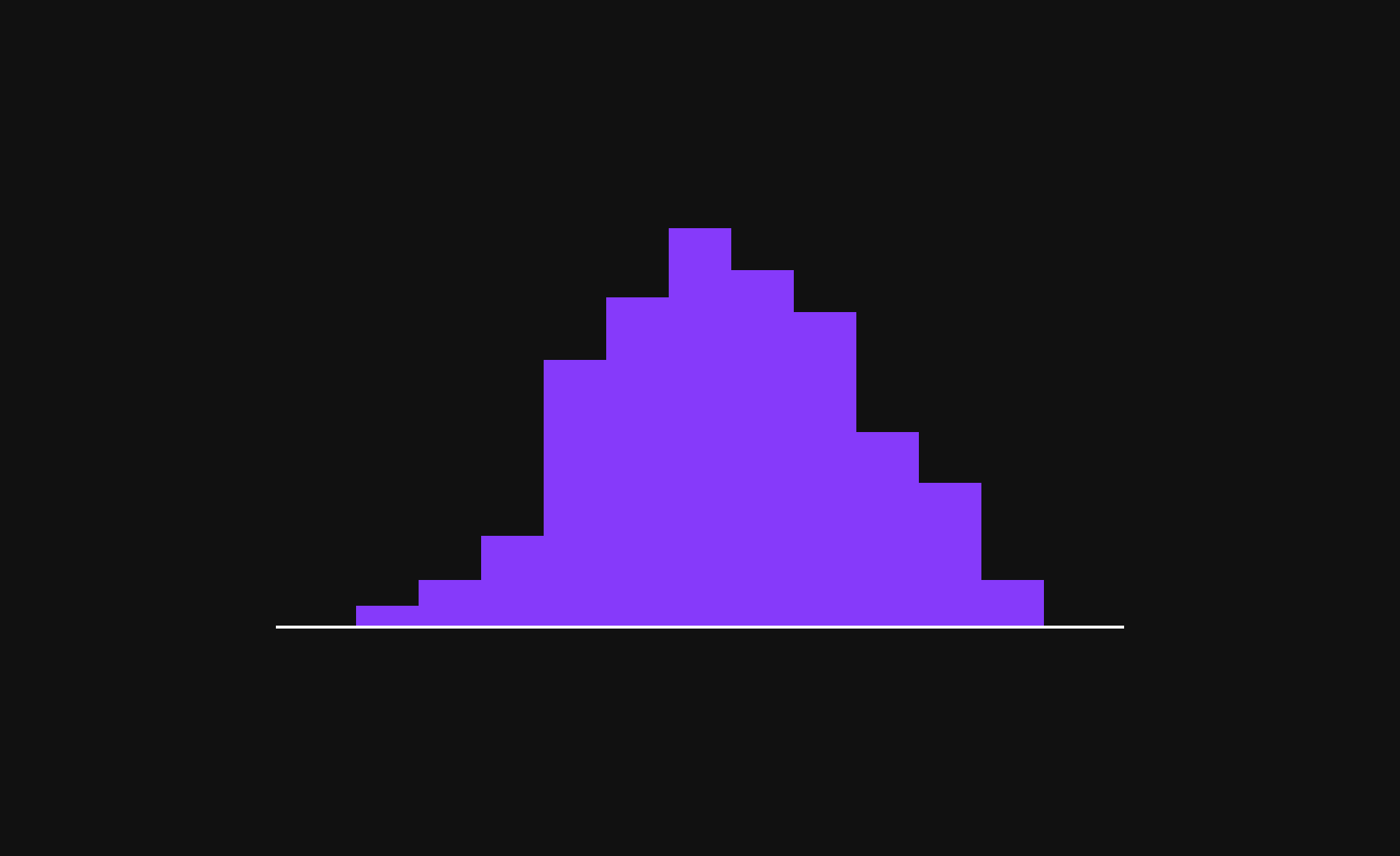
In the Transformer Block, Normalization ensures that each token’s representation remains stable and well-balanced across layers.
For example, the 768-dimensional vector of the token "friend" is normalized, meaning:
- The mean becomes 0
- The standard deviation becomes 1
This process helps the model maintain consistent scaling, preventing extreme variations in token values and improving learning efficiency. Normalization is a crucial step that keeps the computations smooth and stable as tokens move through multiple Transformer layers.
Multi-head Attention
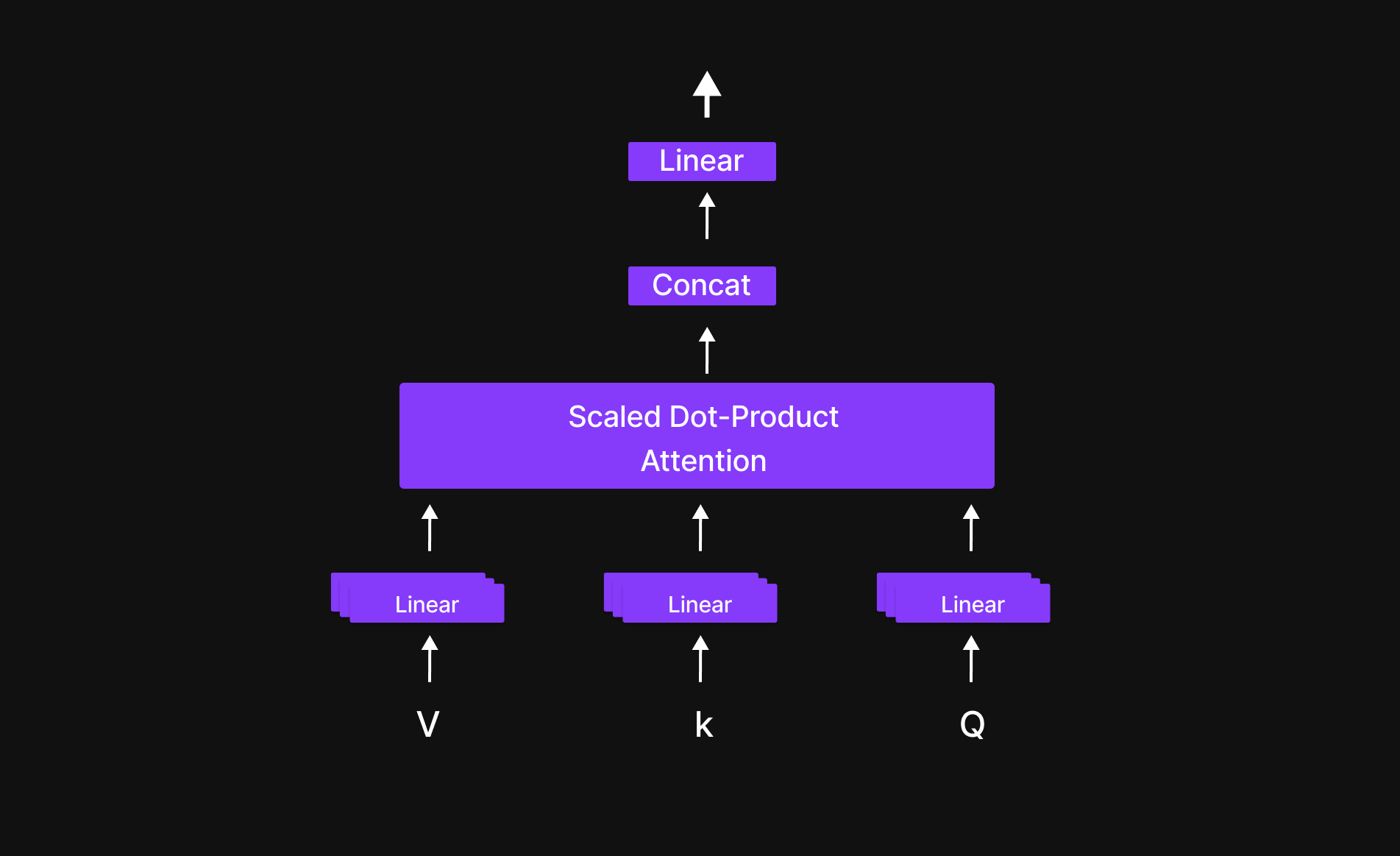 Figure 17: Structure of head attention
Figure 17: Structure of head attention
In a sentence, every word has a relationship with others. Multi-Head Attention helps the model determine how much importance each token should give to the others.
For example, if we focus on the word "friend", the model decides how much attention it should pay to "a," "true," "accepts," and "you." This process allows the model to create a context map, identifying which words are most relevant to each other.
By doing this, Multi-Head Attention enables the model to understand the structure and meaning of a sentence, making it effective at capturing relationships, context, and dependencies in language.
we are going to see the attention mechanism in details in next blog
 Figure 18:Giving attention to other words (context map)
Figure 18:Giving attention to other words (context map)
Dropout
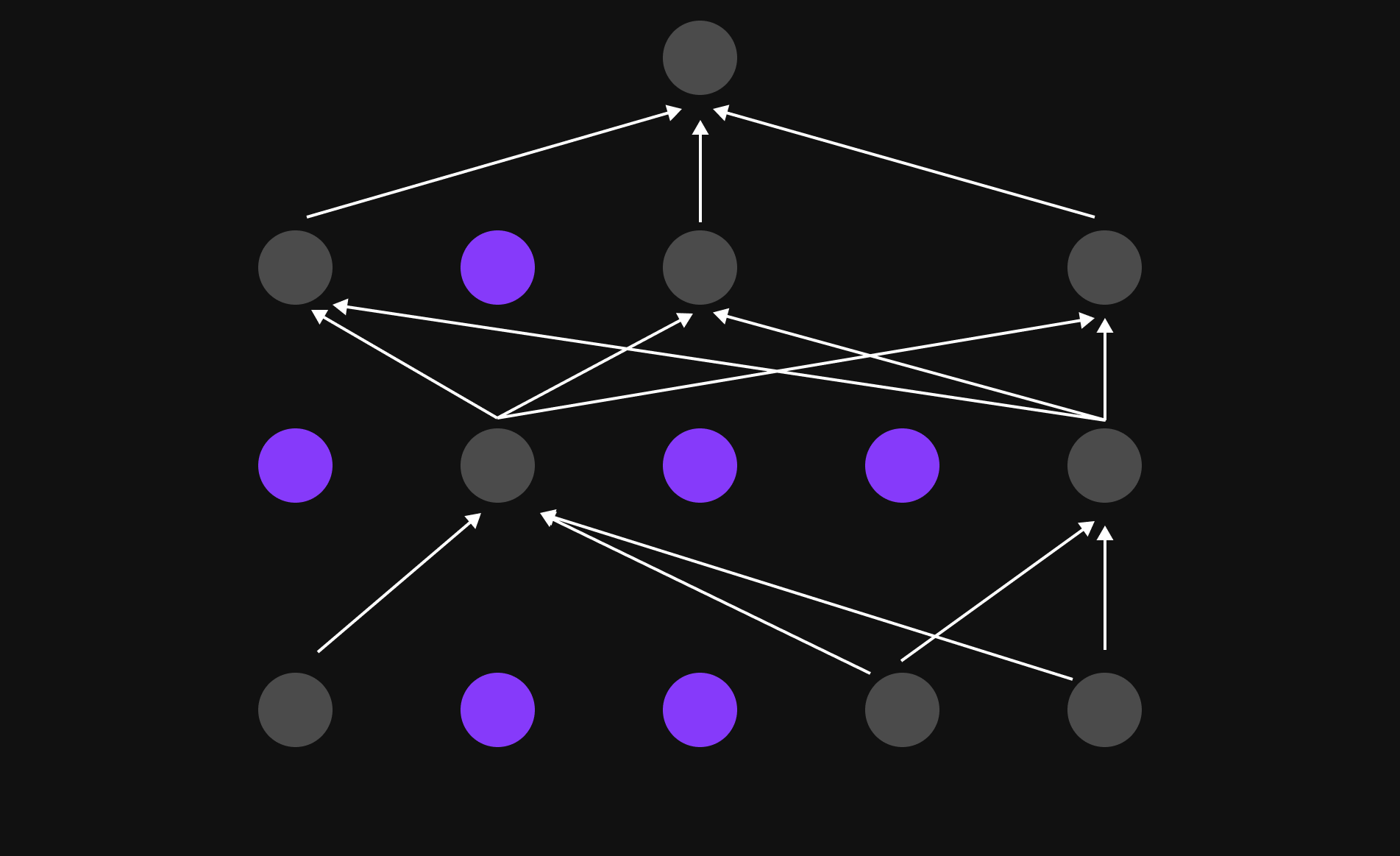 Figure 19: Dropout -randomly turns off a portion of these parameters during training
Figure 19: Dropout -randomly turns off a portion of these parameters during training
In Large Language Models (LLMs), not all parameters contribute equally to learning. Some parameters remain inactive or "lazy," relying too much on others. Dropout is a regularization technique that randomly turns off a portion of these parameters during training.
By doing so:
- Inactive parameters are forced to learn, as they can no longer depend on others.
- The model avoids overfitting, ensuring it generalizes well to new text rather than memorizing training data.
- It enhances robustness, making sure that learning is distributed across all parameters instead of a few dominant ones
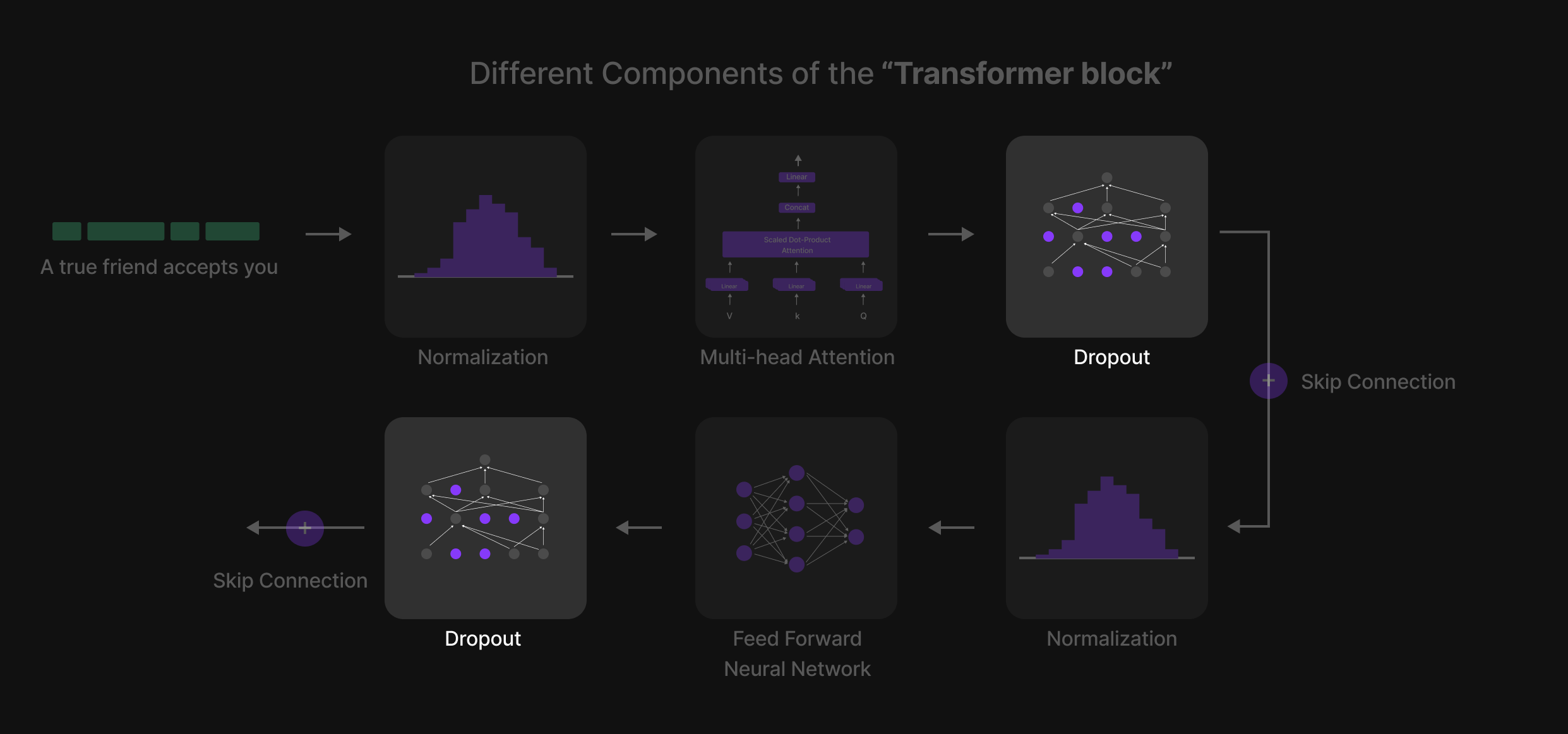 Figure 20: Dropout is applied twice
Figure 20: Dropout is applied twice
In the Transformer Block, Dropout is applied twice—once after Multi-Head Attention and again after the Feed-Forward Neural Network—ensuring that learning remains balanced and effective throughout the model.
Skip Connection
In Large Language Models (LLMs), training involves passing information through multiple Transformer Blocks, each with several layers. However, as data moves through these layers, gradients (updates that guide learning) can become too small (vanishing gradient problem), making it harder for earlier layers to learn effectively.
Skip Connections, also known as Shortcut Connections, solve this issue by providing an alternate path for gradients to flow. Instead of relying solely on sequential updates, they allow information to bypass certain layers and be added directly to later layers.
This mechanism ensures that:
- Early layers continue to receive useful gradient updates, preventing them from becoming stagnant.
- Deep networks train more efficiently, improving overall learning stability.
- The model retains important information, avoiding excessive distortion through multiple transformations.
Skip Connections play a crucial role in keeping LLMs stable, efficient, and capable of processing deep linguistic structures without losing valuable information.
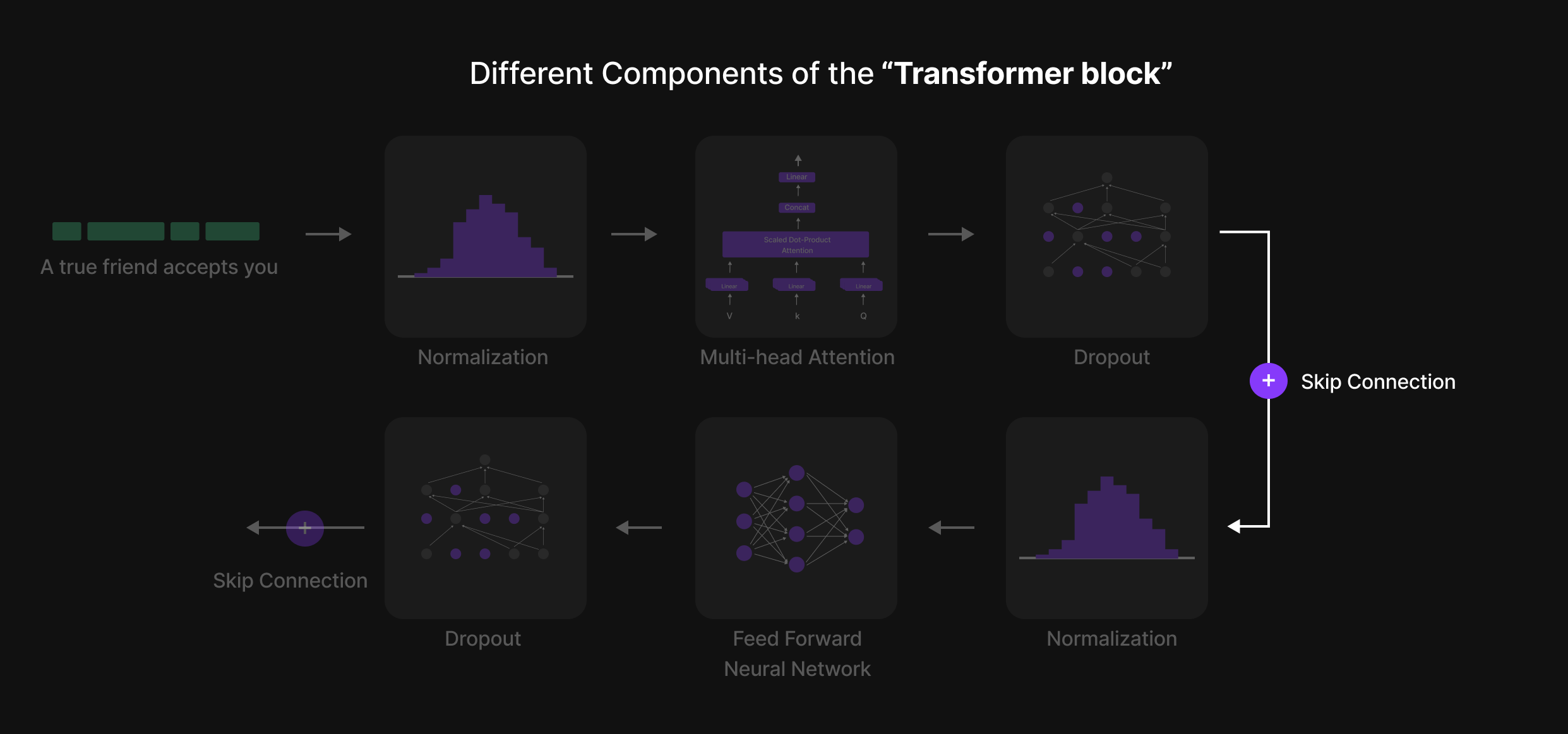
Normalization 2
After passing through Multi-Head Attention, the token representations have already been updated based on contextual relationships. However, before feeding them into the Feed-Forward Neural Network (FFN), another Normalization step is applied.
Purpose of the Second Normalization:
- Stabilizes the input to the Feed-Forward Network, ensuring that activations remain balanced.
- Prevents numerical instability, avoiding extreme variations in token values.
- Improves training efficiency by ensuring that the FFN processes well-scaled inputs, reducing learning disruptions.
By applying Normalization before the FFN, LLMs maintain consistent and well-structured token representations, enabling efficient learning and robust language modeling across multiple Transformer layers.
Feed Forward Neural Network

In the Transformer Block, the next is the Feed-Forward Neural Network (FFN)
—a crucial step that enhances the model's ability to capture complex patterns and relationships in language.
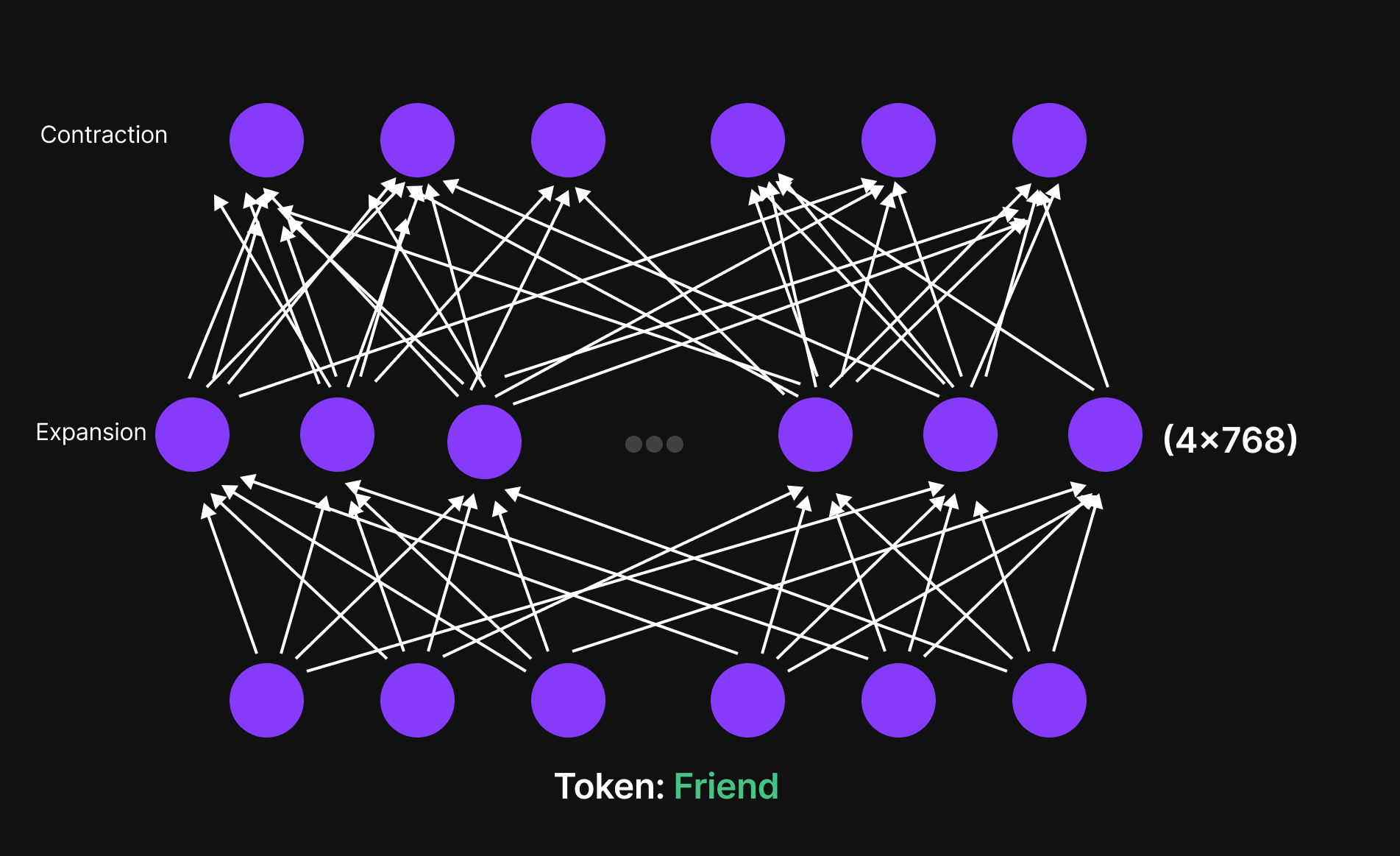 Figure 24: Feed-Forward Neural Netowrk
Figure 24: Feed-Forward Neural Netowrk
How the Feed-Forward Network Works
- Each token, represented as a 768-dimensional vector (for GPT-2 Small), is first expanded into a higher-dimensional space—typically 4 times the original size (3072 dimensions in GPT-2 Small).
- This expansion allows the model to explore richer feature spaces and capture subtle variations in meaning.
- The network then compresses the representation back to 768 dimensions, refining the information for the next Transformer layer.
This expansion and contraction mechanism ensures that the model learns complex linguistic structures while maintaining computational efficiency.
Dropout Layer 2
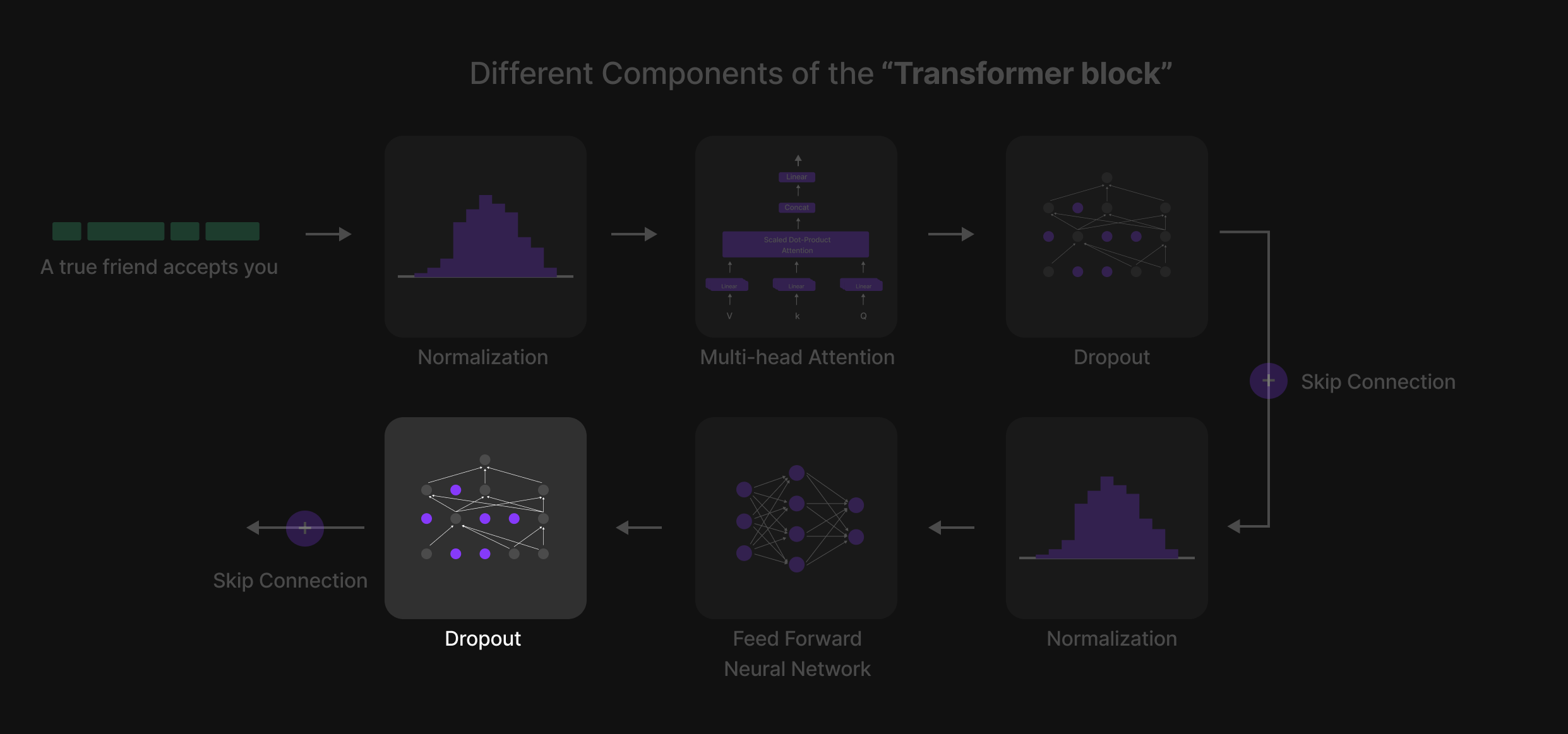 Figure 25: Final Dropout layer
Figure 25: Final Dropout layer
After the Feed-Forward Neural Network (FFN), the final Dropout layer is applied. This serves as a last safeguard against overfitting, ensuring that the model does not rely too heavily on specific parameters. By randomly deactivating some neurons, it forces the network to distribute learning more effectively, leading to better generalization when processing unseen text.
Final Skip Connection
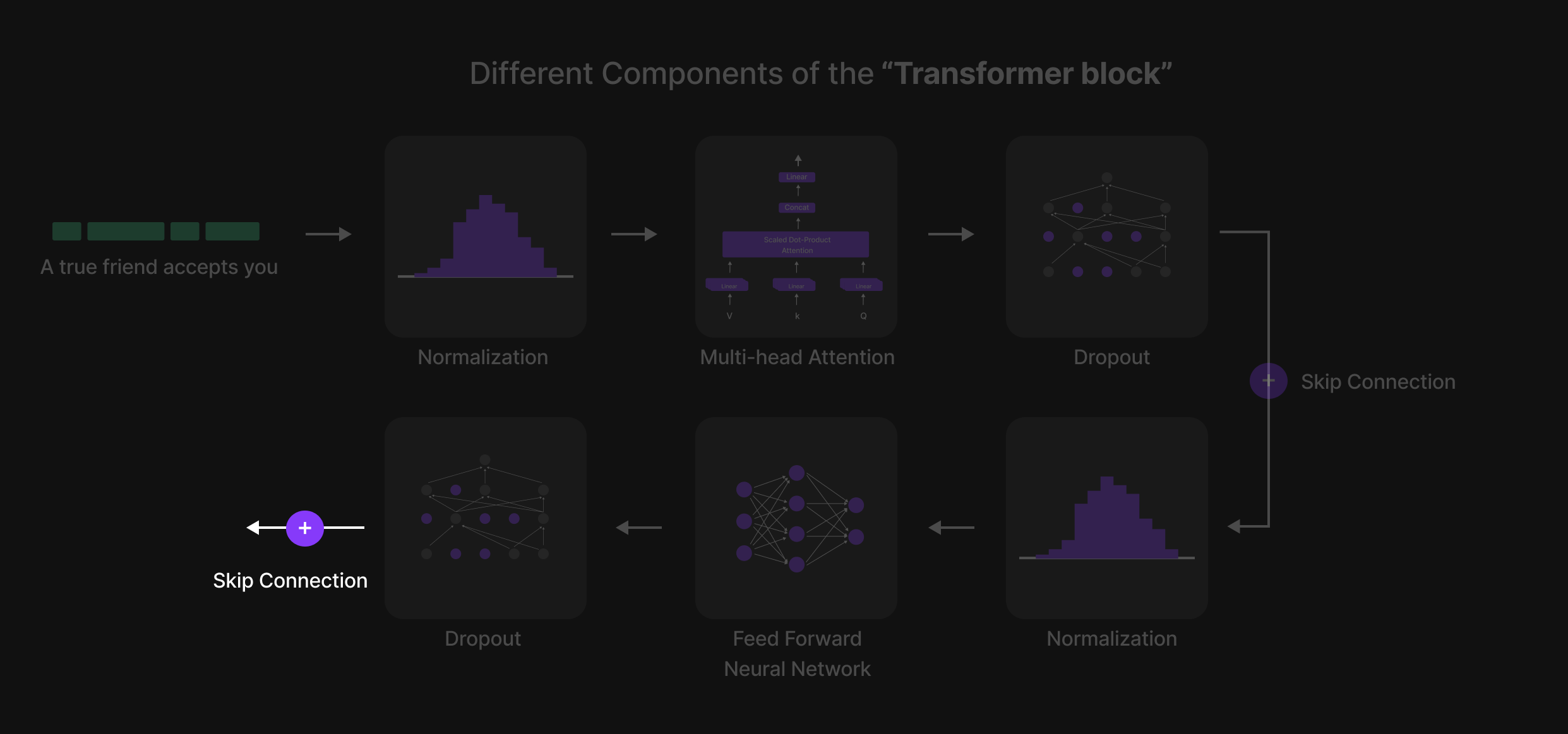 Figure 26: Final Skip Connection
Figure 26: Final Skip Connection
Following the second Dropout layer, a Skip Connection (Shortcut Connection) is applied.
Complexity does’t Stop here
 Figure 27: Multiple Transformer block
Figure 27: Multiple Transformer block
However, the complexity does not stop there. A model like GPT-2 Small has 12 such Transformer Blocks, meaning every token must repeat this process 12 times before moving forward. For larger models, such as GPT-2 Large (36 blocks) or GPT-2 XL (48 blocks), this process becomes even more intensive. Modern LLMs like GPT-4 may have 96 or more Transformer Blocks, making the journey even more computationally demanding.
Why Is This Repetition Necessary?
Each Transformer Block gradually refines the representation of a token, ensuring that it captures deeper relationships and meanings. As the token moves through these blocks:
- Its contextual understanding improves with each Multi-Head Attention layer.
- The Feed-Forward Neural Network enhances its feature space, making it more adaptable to complex patterns.
- The Dropout layers prevent overfitting, ensuring robust generalization.
- The Skip Connections allow smoother gradient flow, stabilizing training.
Despite the repetitive nature, this layered processing is what enables LLMs to understand language at an advanced level.
Retaining Dimensions Across Transformer Blocks
Although the token undergoes numerous transformations, its dimensionality remains the same. For example, if a token starts as a 768-dimensional vector, it remains 768-dimensional even after passing through all 12 (or more) Transformer Blocks. The key difference is that its values are updated, making it more contextually aware and linguistically refined.
Once the token completes this tedious yet essential journey, it moves toward the output layer, where the final token prediction takes place.
Output Layer
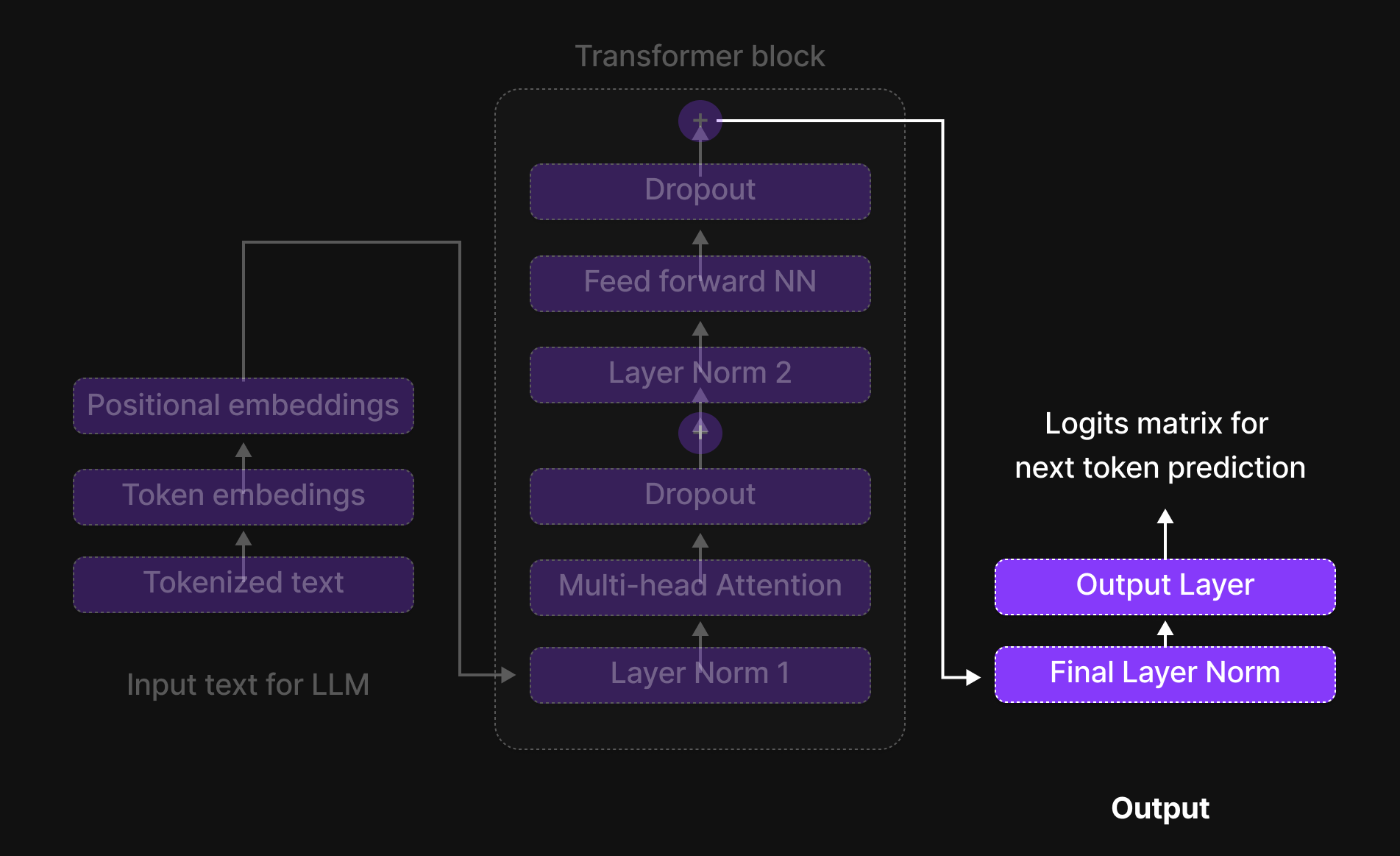 Figure 28: Output Block of LLM architecture
Figure 28: Output Block of LLM architecture
Once the tokens ("A true friend accepts you") pass through the Transformer Block, their representations still have 768 dimensions, but their values have changed as the model refines its understanding of the context.
Dimension is same but the values has been changed, it has now richer context
 Figure 29: Dimension is same but the values has been changed, it has now richer context
Figure 29: Dimension is same but the values has been changed, it has now richer context
Final Layer Normalization
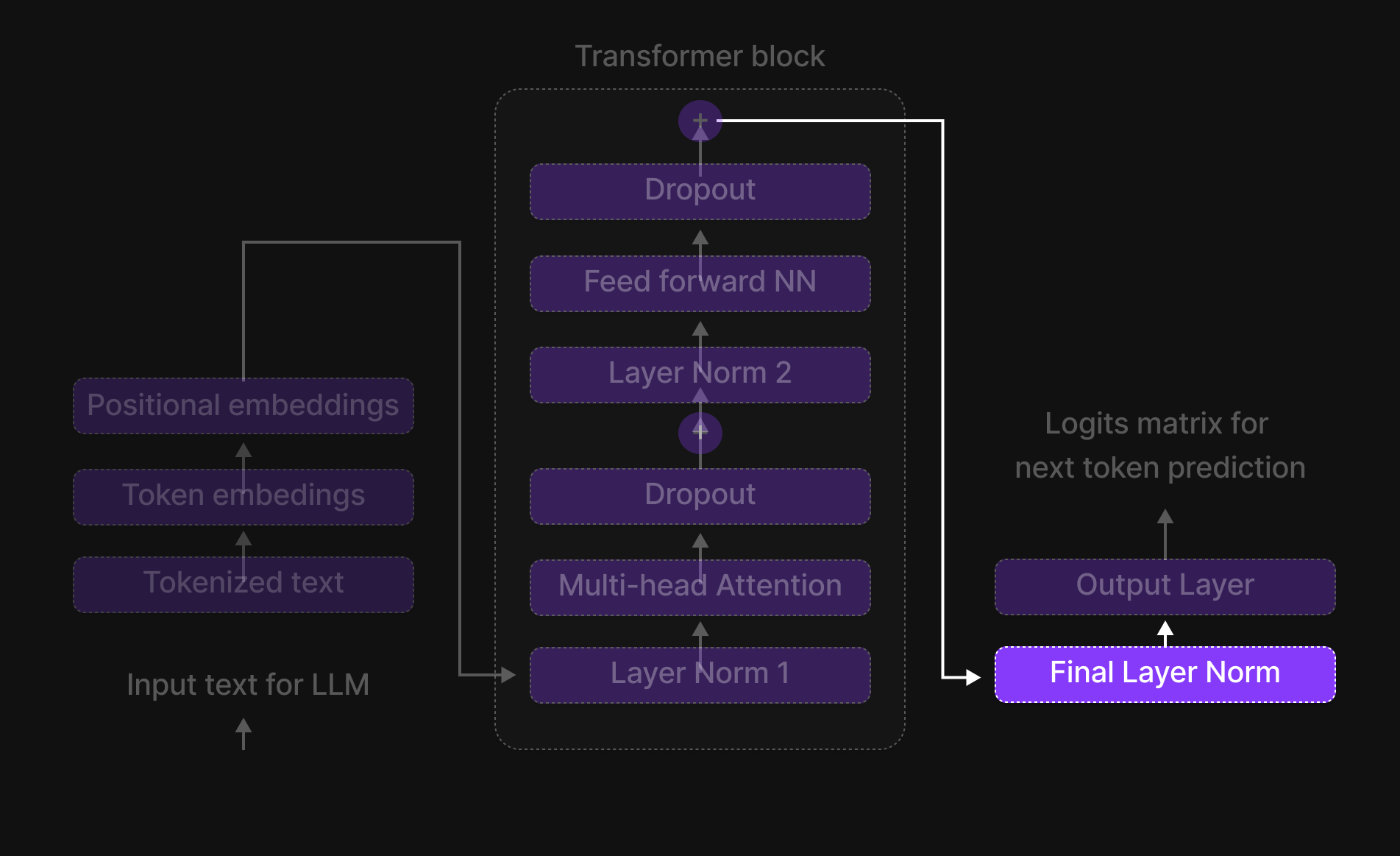 Figure 30: Final Layer Normalization
Figure 30: Final Layer Normalization
Before moving to the next step, each 768-dimensional vector is passed through a Final Layer Normalization process. This ensures that the model’s learned features remain well-scaled and stable before making predictions.
At this point, all token representations still maintain 768 dimensions, but their numerical values have been updated.
Output Projection Layer: Expanding to Vocabulary Size
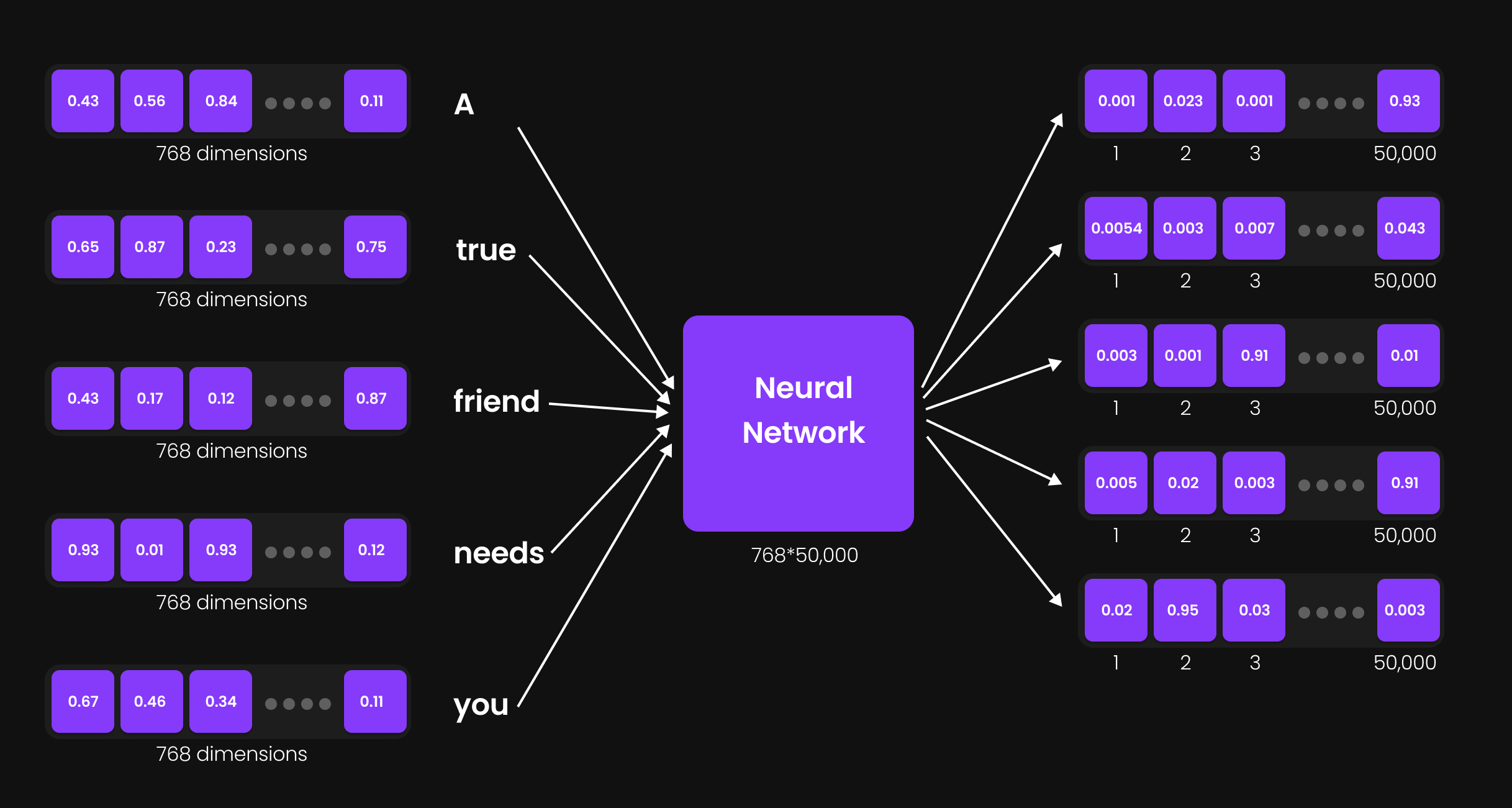 Figure 31: Output Projection Layer
Figure 31: Output Projection Layer
Now, we need to convert each 768-dimensional vector into a representation that aligns with the model’s vocabulary size, which is 50,000. This transformation is achieved using an output projection layer—a simple neural network of size 768 × 50,000.
Why is this necessary?
- Every token needs a 50,000-dimensional vector because we must determine the next most likely token from the entire vocabulary.
- The output projection layer ensures that each token representation can be mapped to a specific word in the vocabulary.
After this layer, the size of each token representation becomes 50,000, meaning we now have:
- "A" → 50,000-dimensional vector
- "True" → 50,000-dimensional vector
- "Friend" → 50,000-dimensional vector
- "Accepts" → 50,000-dimensional vector
- "You" → 50,000-dimensional vector
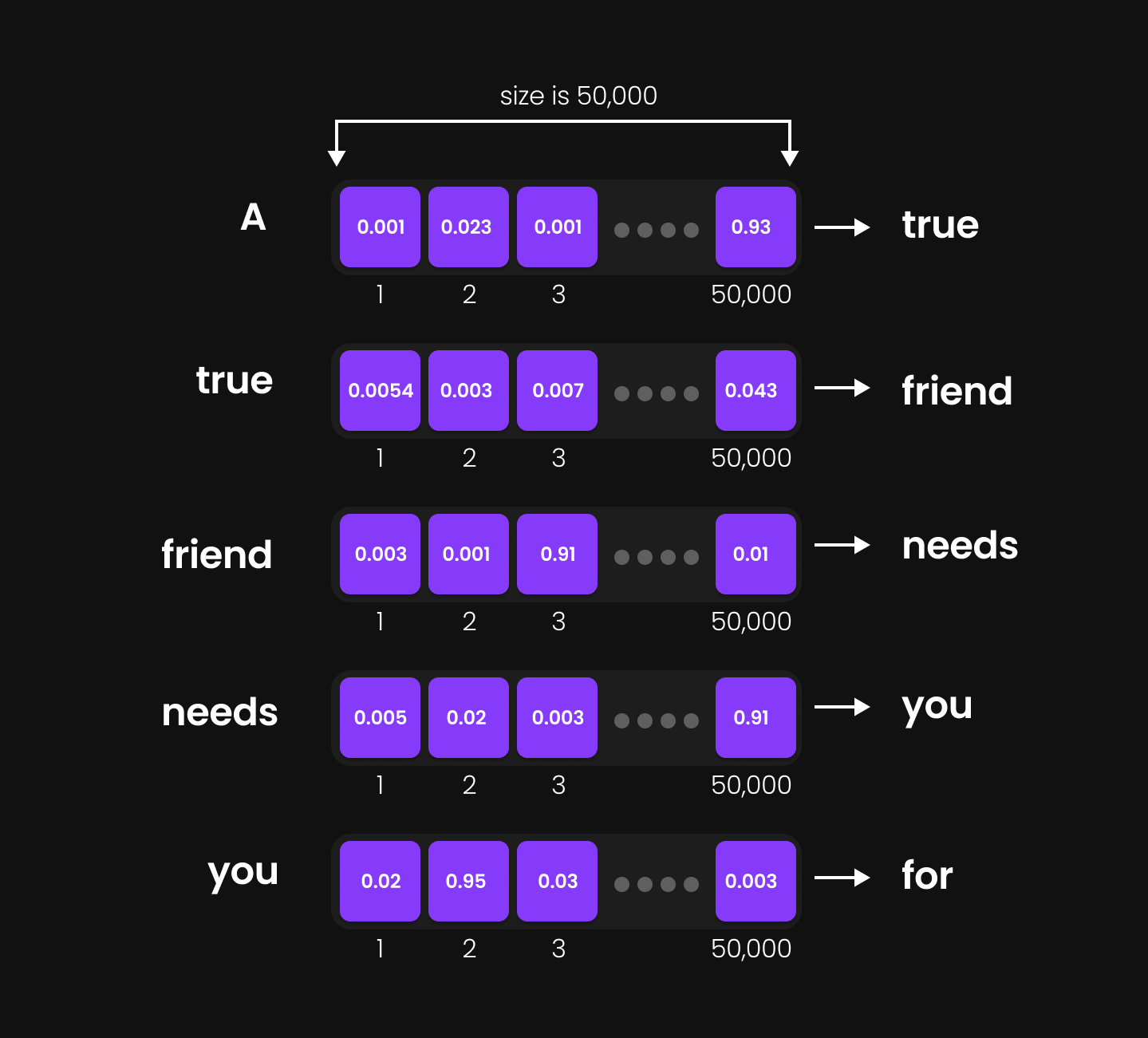
Final Step: Choosing the Next Token
Now, the model needs to select the next token from the vocabulary. Here’s how:
-
The 50,000-dimensional vector for each token contains values corresponding to each word in the vocabulary.
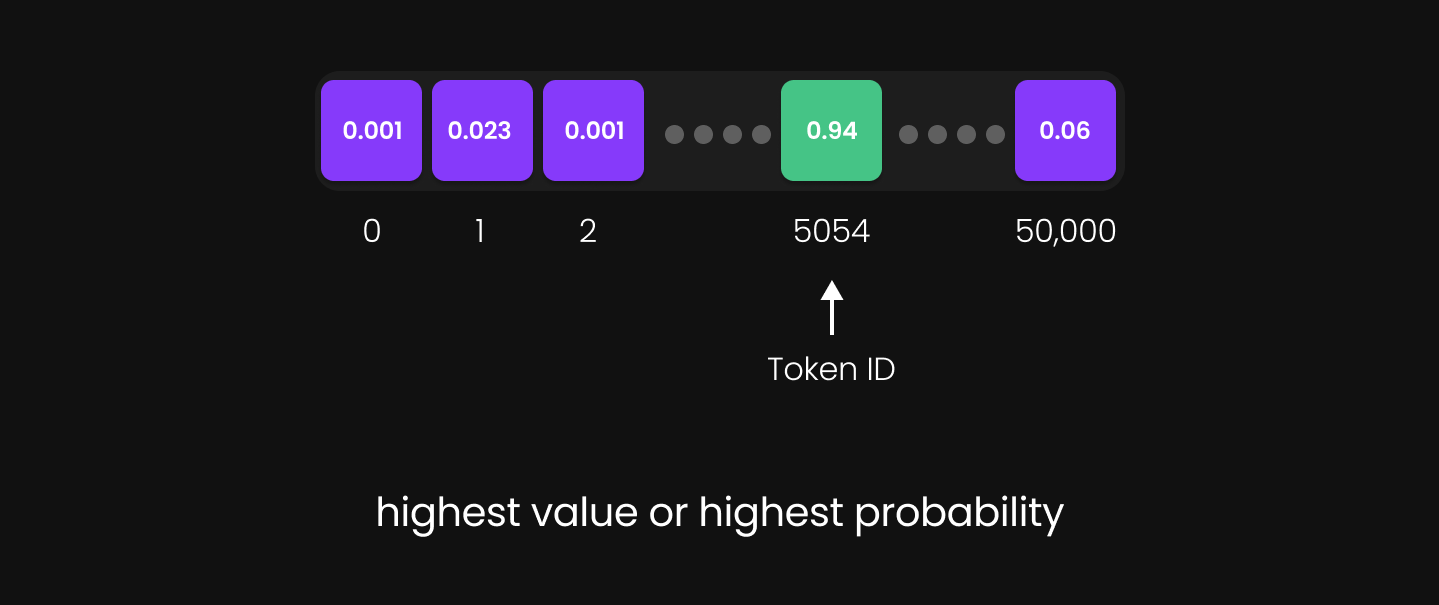 Figure 33: highest probability value
Figure 33: highest probability value -
The model identifies the index with the highest value—this index represents the most probable next word.
-
Using this index, the model retrieves the corresponding token from the vocabulary.
For example:
- If "A" is the input, the highest probability might correspond to the index for "true," making "true" the predicted next token.
- If "A true" is the input, the model predicts "friend" as the output.
- If "A true friend" is the input, the next token predicted could be "accepts," and so on.
This process happens at every step, ensuring fluid and contextually meaningful text generation.
Conclusion
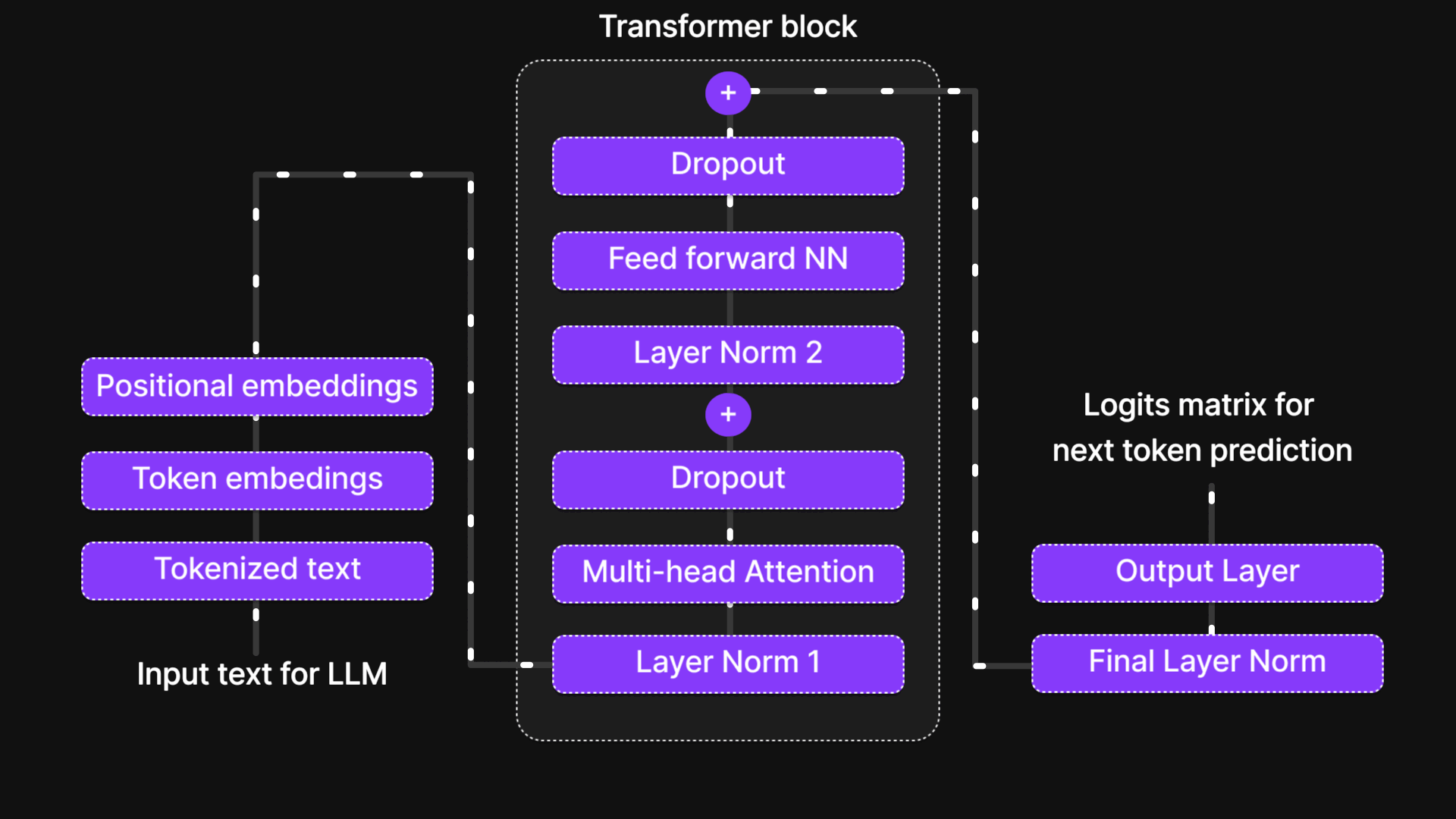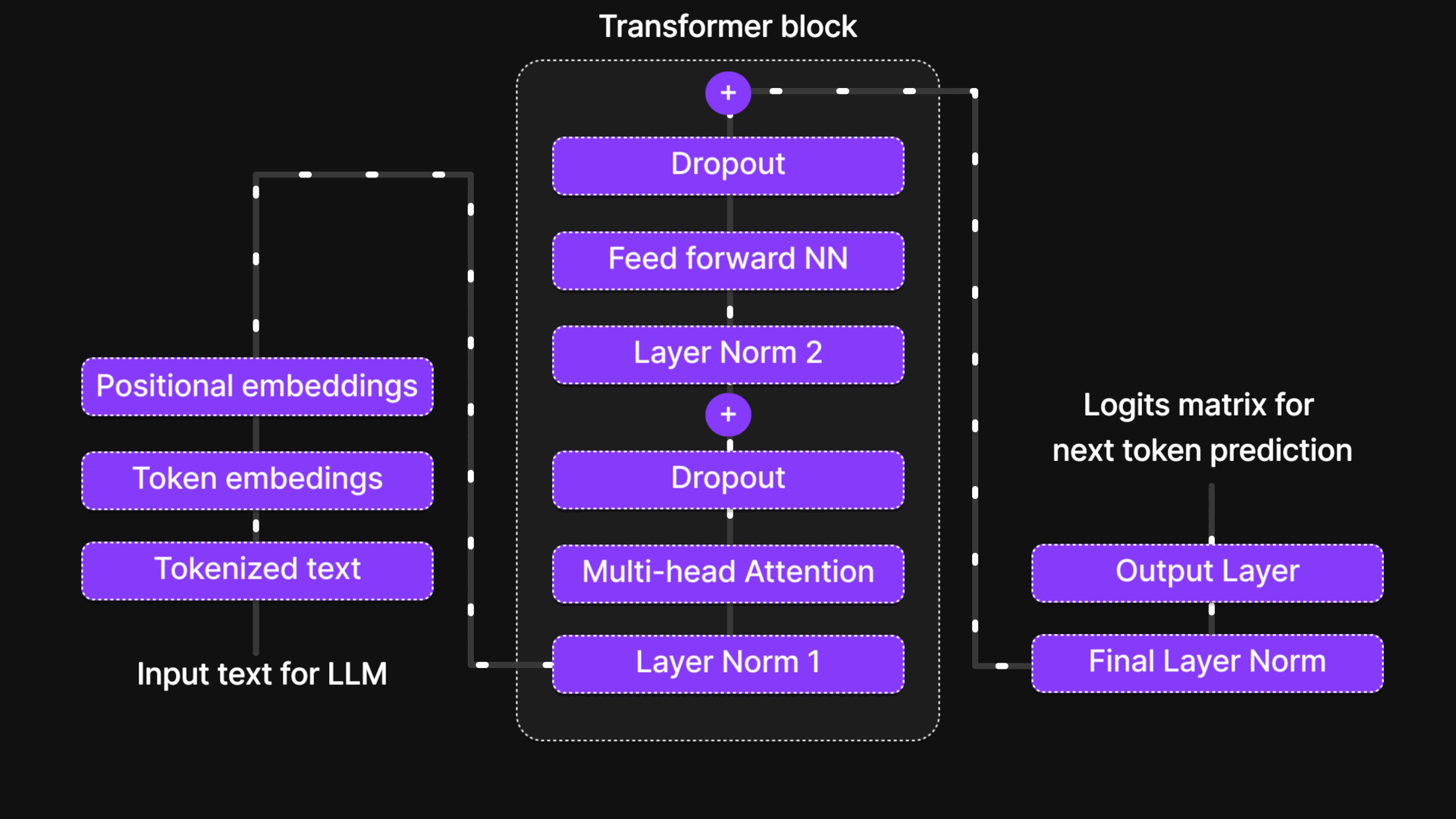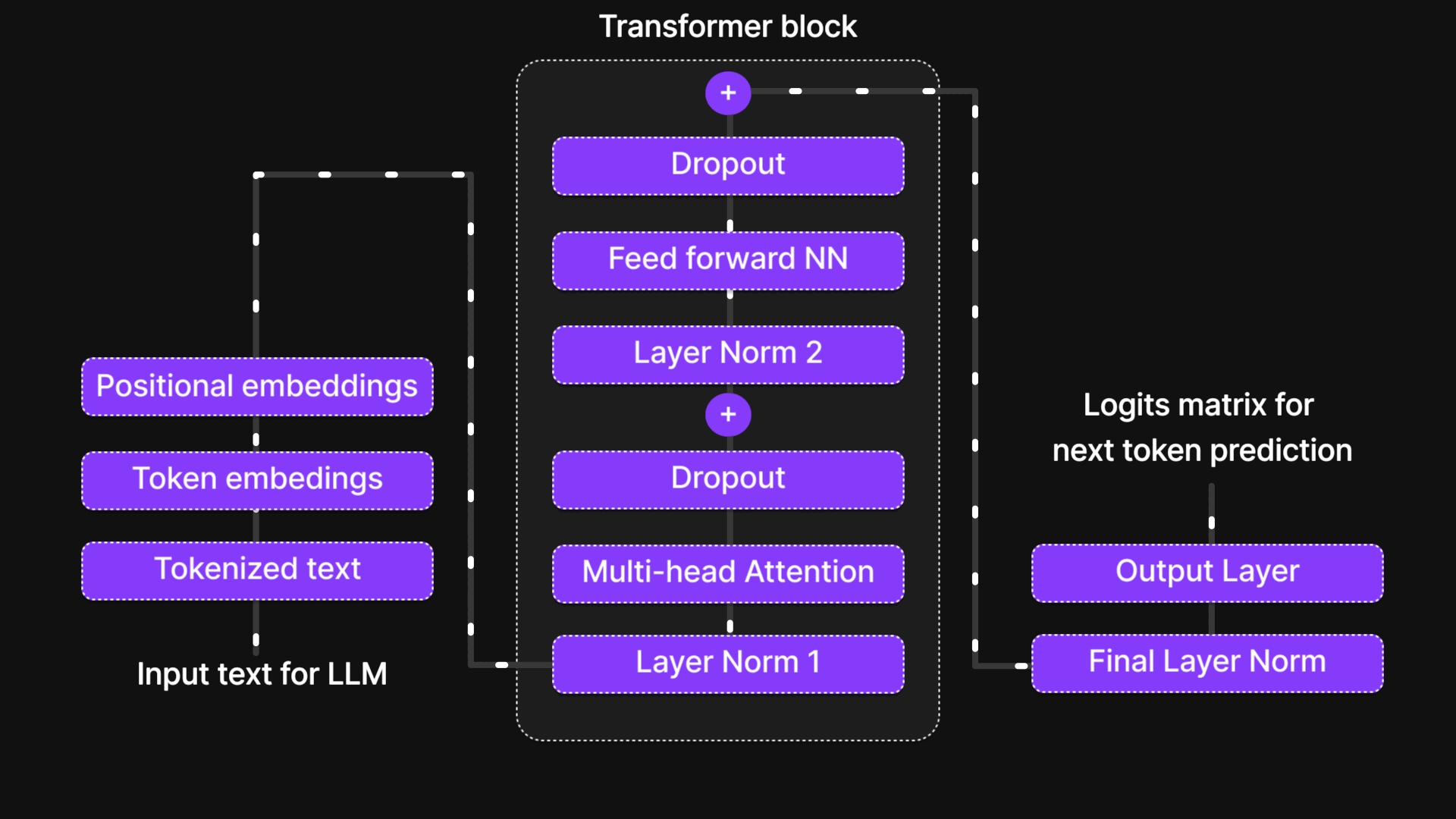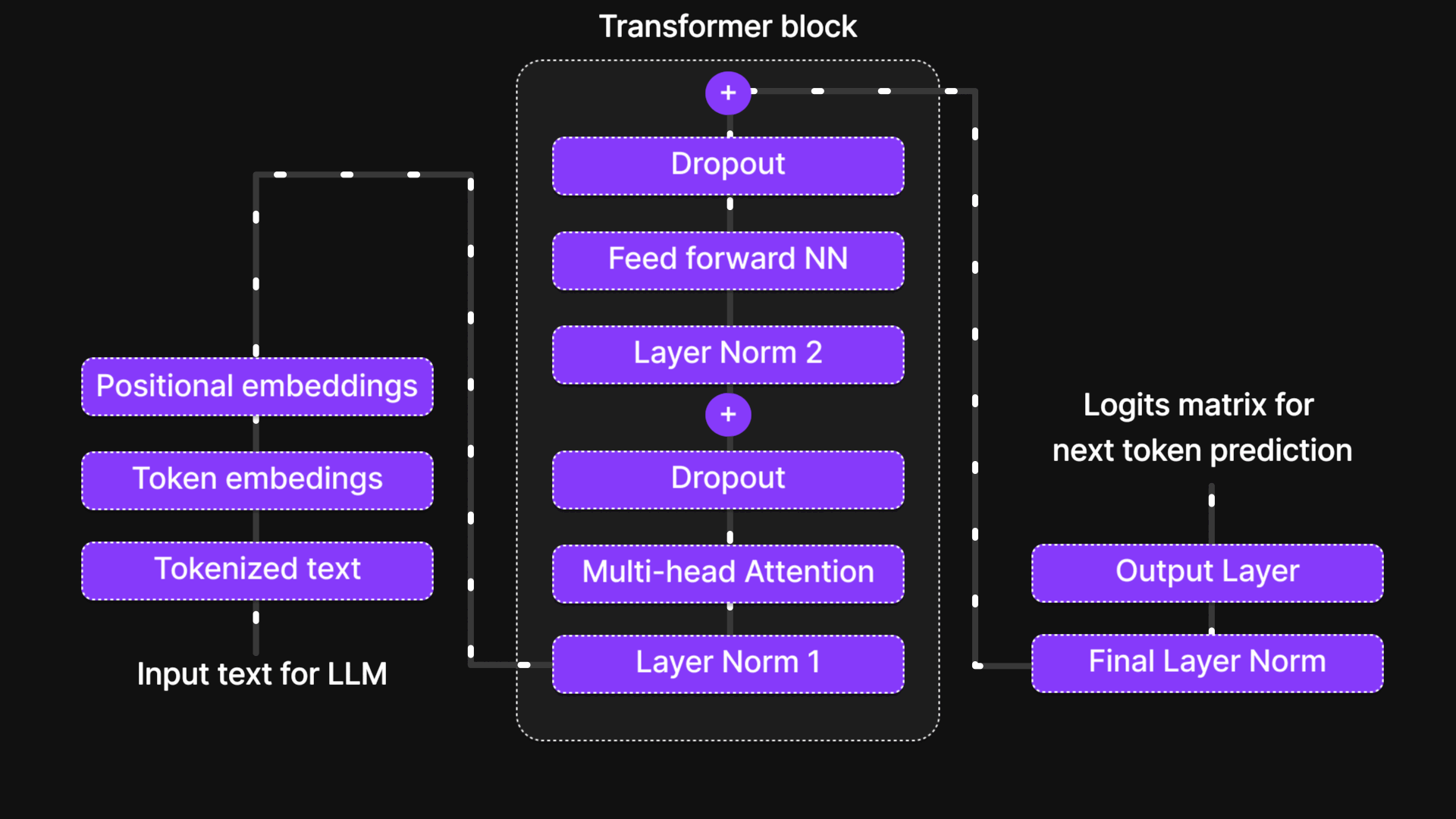 Figure 35: LLM Architecture
Figure 35: LLM Architecture
A token’s journey through an LLM transforms it from raw text into a refined, context-aware representation. It starts with tokenization, where words are broken down and assigned Token IDs. Then, Token Embeddings capture meaning, and Positional Embeddings ensure word order is preserved. These combined embeddings form the Input Embedding, which enters the Transformer Blocks, where Multi-Head Attention refines context, and the Feed-Forward Network (FFN) enhances understanding. Dropout and Normalization maintain efficiency and stability as the token moves through multiple layers.
Finally, in the Output Layer, the token's representation is expanded to match the vocabulary, and the model predicts the next word based on probabilities. This process enables LLMs to generate coherent, human-like text. As models evolve with innovations like Multi-Head Latent Attention, Mixture of Experts (MoE), and RoPE, their ability to process and generate language will only become more powerful. Understanding this journey provides key insights into how modern AI understands and generates language
So that’s it for now!
I’m also building ML and LLM projects, sharing and discussing them on LinkedIn and Twitter. If you’re someone curious about these topics, I’d love to connect with you all!
LinkedIn : mayankpratapsingh022
Twitter/X : Mayank_022
Stay curious, keep learning, and let’s continue unraveling the future of AI together!