[2] A Bird’s-Eye View of LLM Architecture
Mayank Pratap Singh
@Mayank Pratap Singh
![[2] A Bird’s-Eye View of LLM Architecture](/_next/image?url=%2Fimages%2Fblog%2FBirds_Eye_View_of_LLM%2FCover.gif&w=1920&q=75)
Table of Contents
- Introduction – Importance of understanding LLM architecture.
- Why Study LLM Architecture? – Key innovations in DeepSeek.
- LLMs as Next-Word Prediction Engines – How they generate text.
- Key Components of LLMs – Input, Processing (Transformer Block), and Output.
- Tokenization & Embeddings – How raw text is converted into model input.
- Transformer Block – Multi-Head Attention, FFNN, and normalization.
- DeepSeek’s Innovations – Multi-Head Latent Attention (MLA) & Mixture of Experts (MoE).
- Conclusion – Summary and transition to the next blog.
Introduction
This is the second blog in the DeepSeek series, and if you're curious about how LLMs like DeepSeek function behind the scenes, you're in the right place! Understanding the architecture of an LLM can provide deeper insights into how these models process and generate text.
In this blog, we'll take a closer look at the key components of LLM architecture, helping you build a strong foundation for grasping more advanced DeepSeek-related concepts in future discussions.
If you haven't checked out the first blog yet, you can find it here
[1] What Makes DeepSeek so Special?
Why Study LLM Architecture?
DeepSeek stands out as an LLM due to the innovative techniques that can be broken down into four major phases, each contributing to its remarkable performance.
These are as follows
- Innovative Architecture
- Multi-Head Latent Attention
- Mixture of Experts (MoE)
- Multi-token prediction
- Quantization
- Rotary Positional Encodings (RoPE)
- Training Methodology
- GPU optimization tricks
- Model Ecosystem
The first key aspect of DeepSeek's innovative architecture is Multi-Head Latent Attention. To understand it clearly, you first need to understand the Attention Mechanism, which we will cover in the next blog of this series.
However, before diving into the Attention Mechanism, it is essential to understand the LLM architecture itself. That is what we are going to cover today.
The Architecture of LLMs
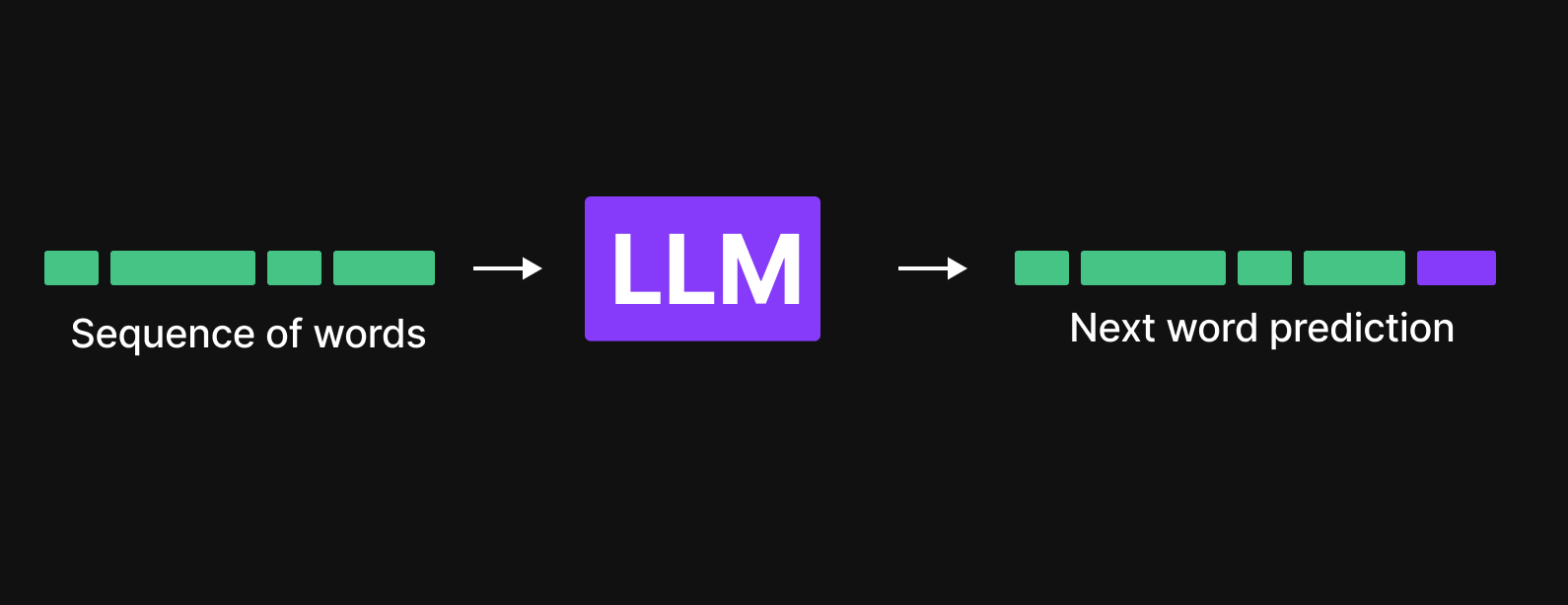
LLMs function as next-word prediction engines. Given a sequence of words, they predict the most probable next word based on learned patterns.
But how does this engine work?
LLMs contain trillions of parameters, but what are these parameters, and how do they function?
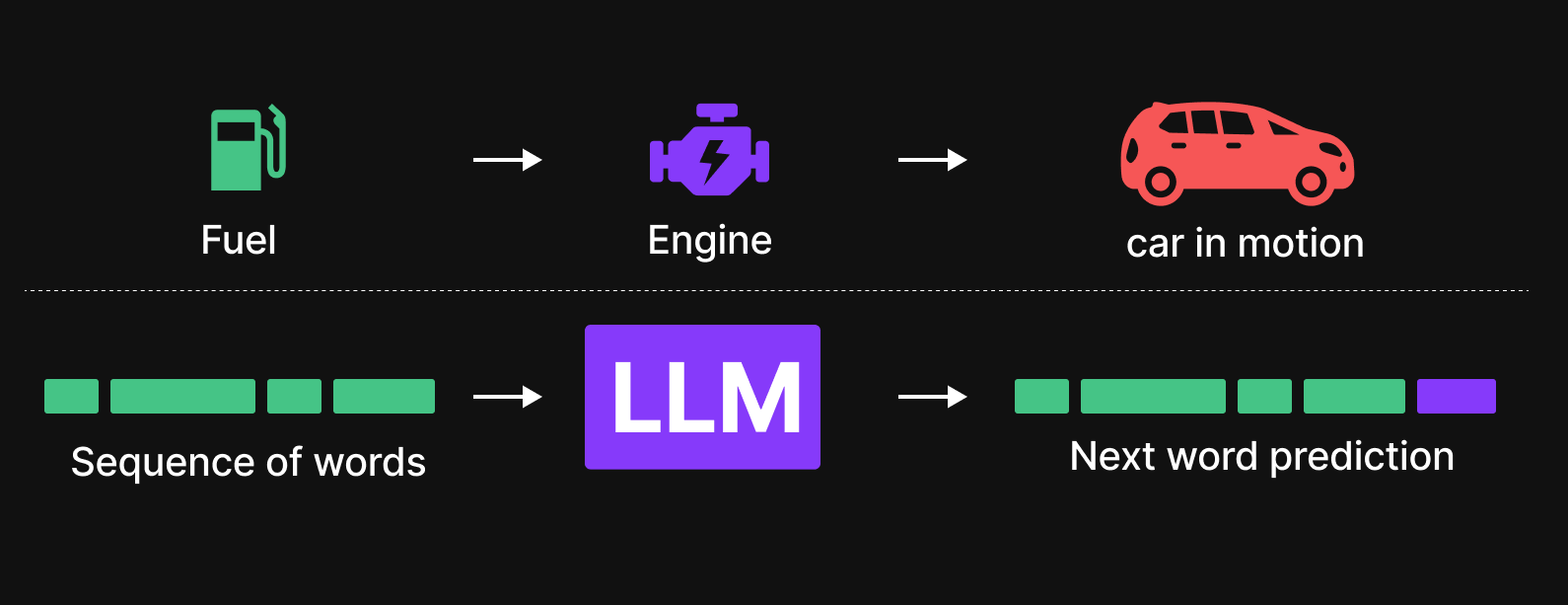
We can understand this through an analogy with a car. A car needs fuel to power the engine, which in turn enables the car to move. Similarly, in an LLM, tokens (words) act as fuel, powering the model’s internal mechanisms to generate meaningful text. Just as fuel follows a complex journey through the engine before producing motion, tokens pass through various layers of the LLM architecture before generating the next predicted word.
What lies within the black box of LLMs?
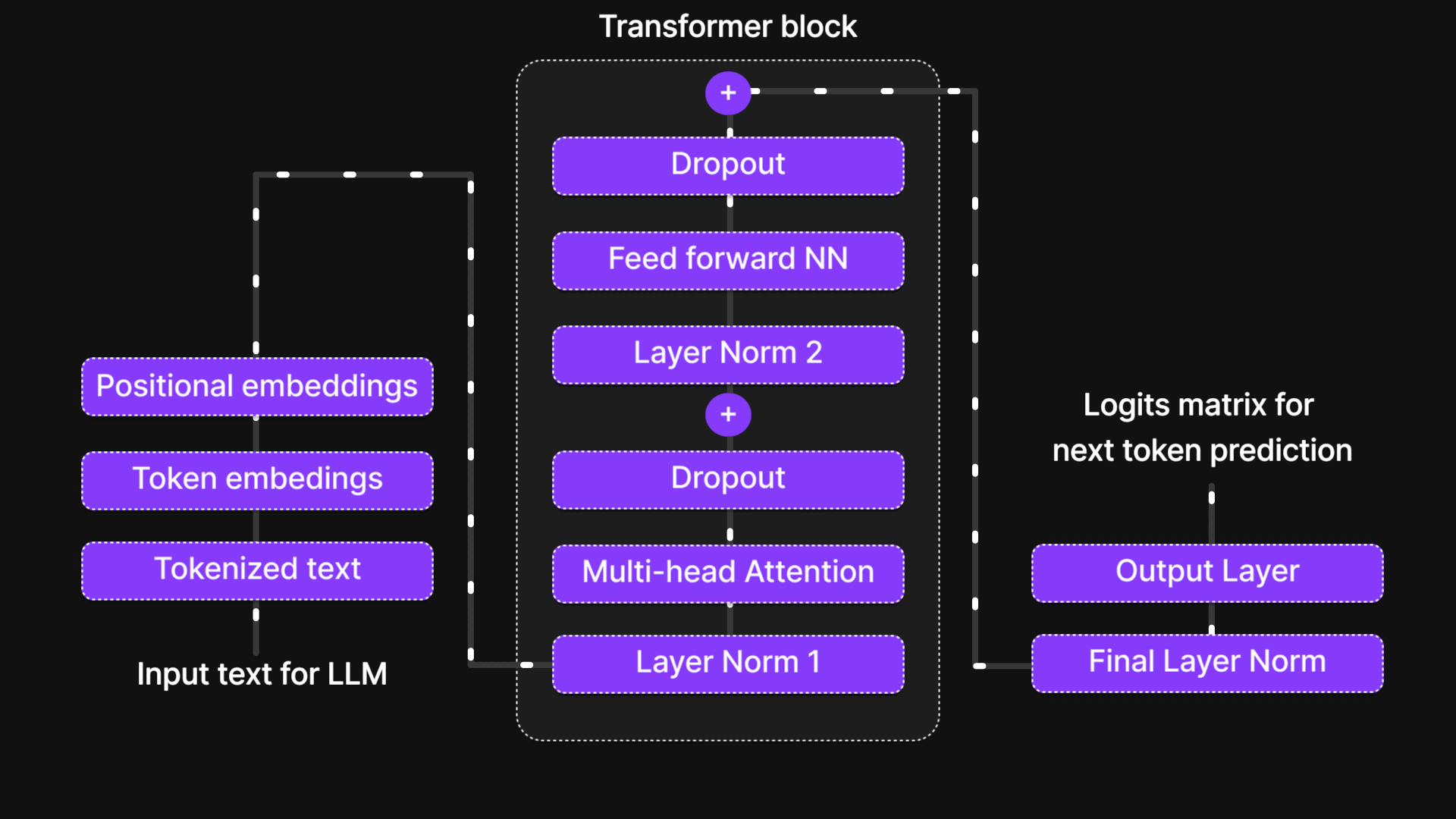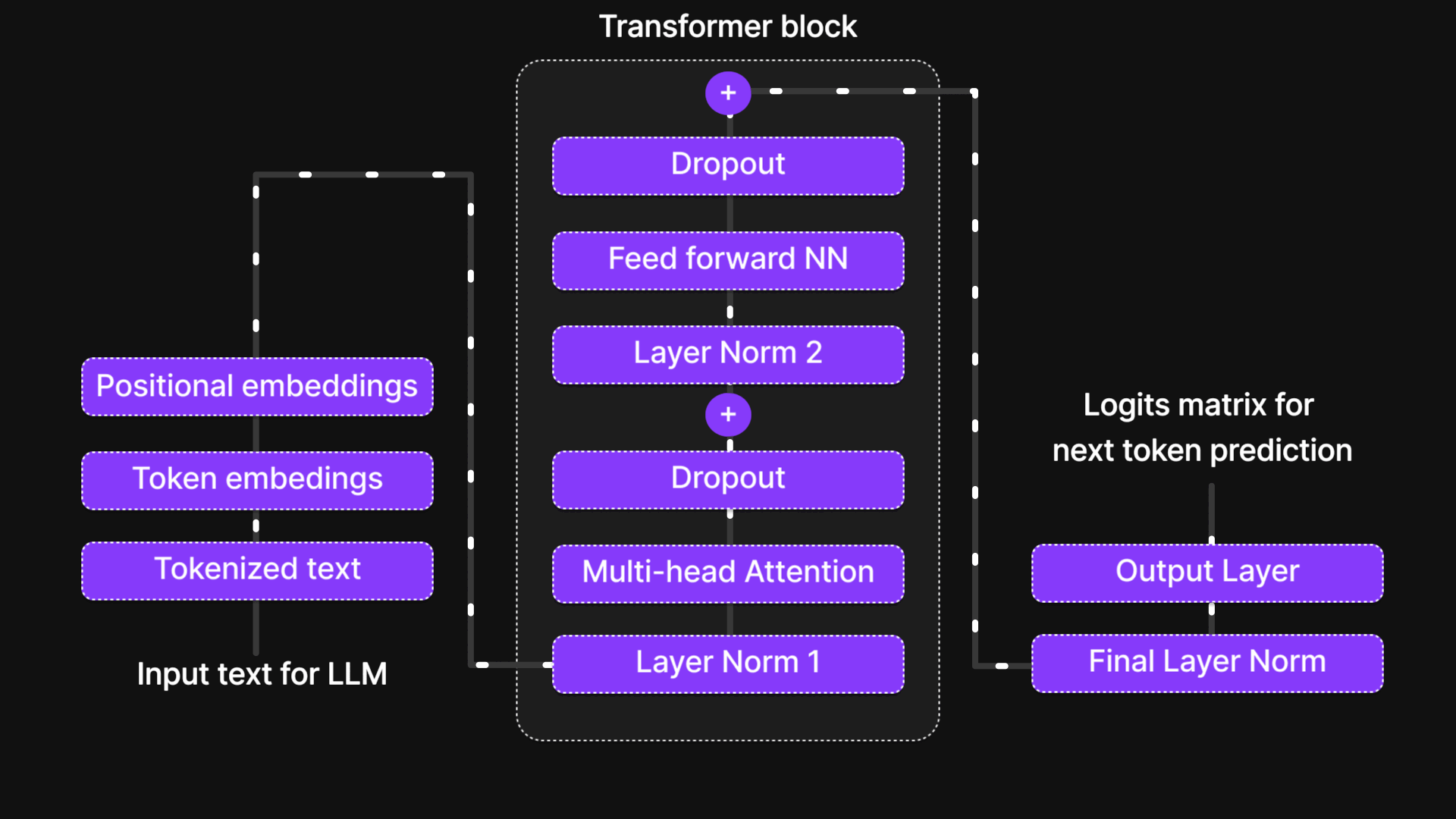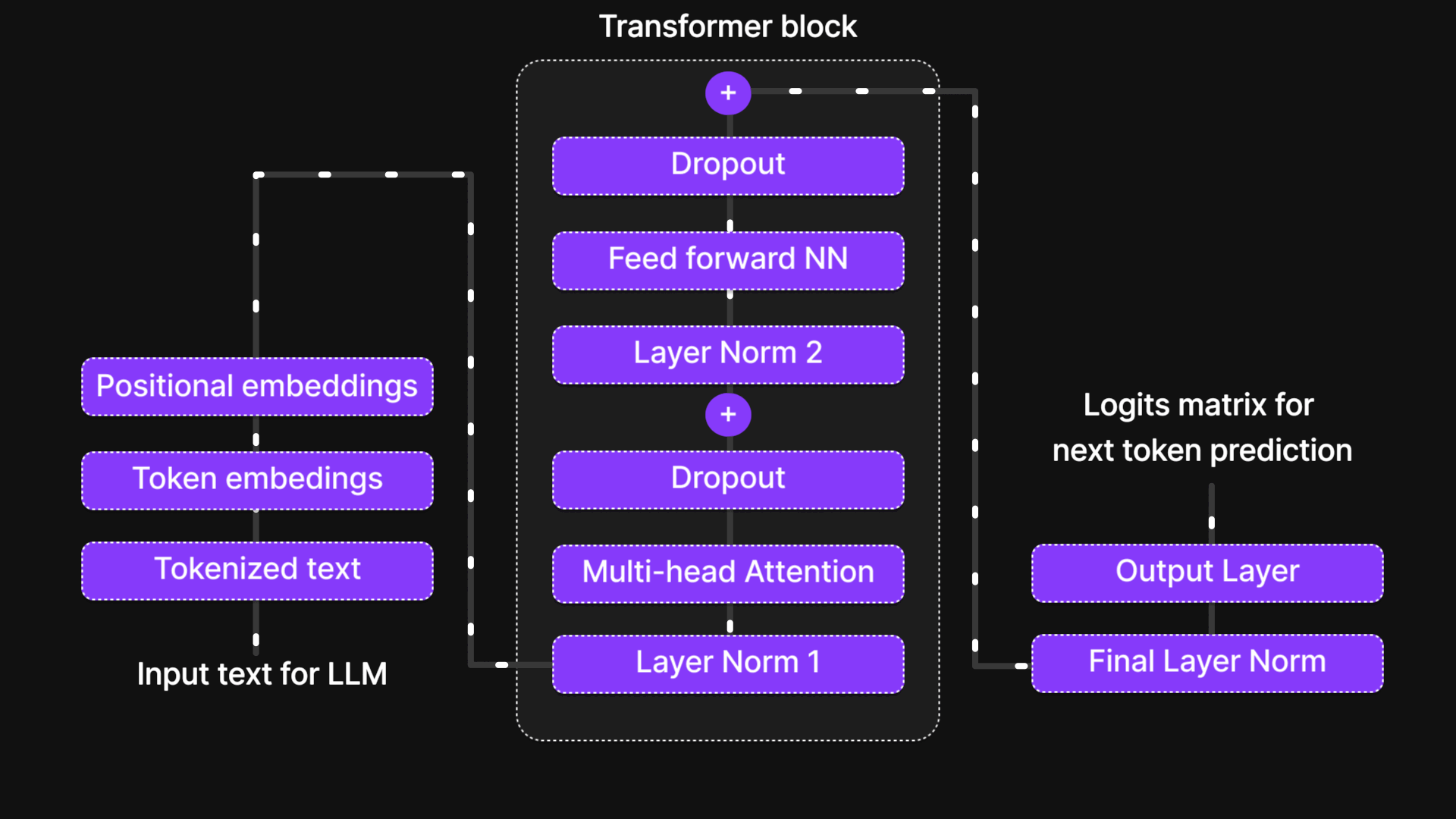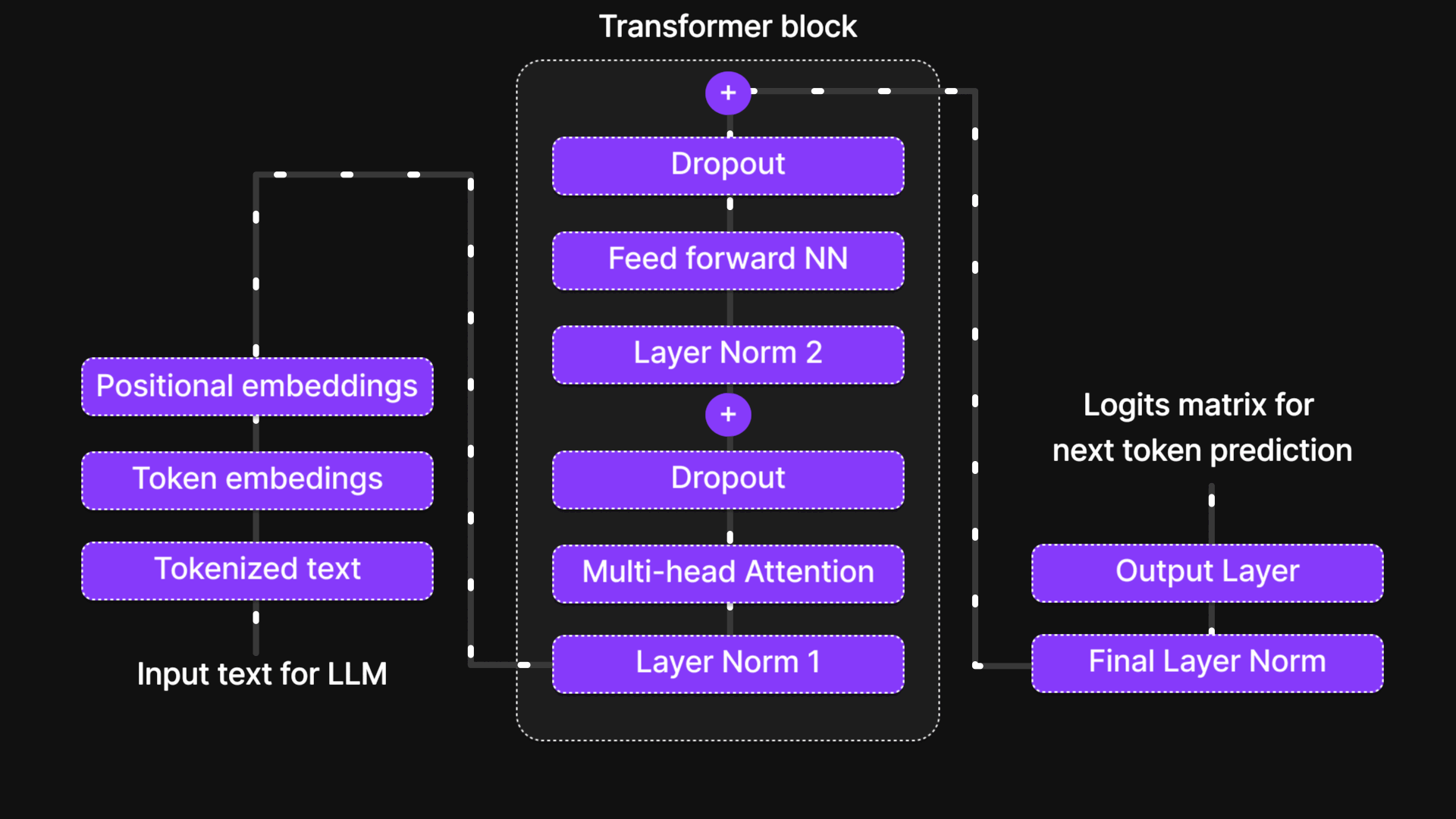 Figure 3: The architecture of LLMs
Figure 3: The architecture of LLMs
Building an engine that truly understands language isn’t easy—that’s why LLM architecture is complex, with multi-head attention and deep layers powering next-token prediction.
The architecture of an LLM can be divided into three parts:
- Input
- Processing
- Output
Input Stage of an LLM
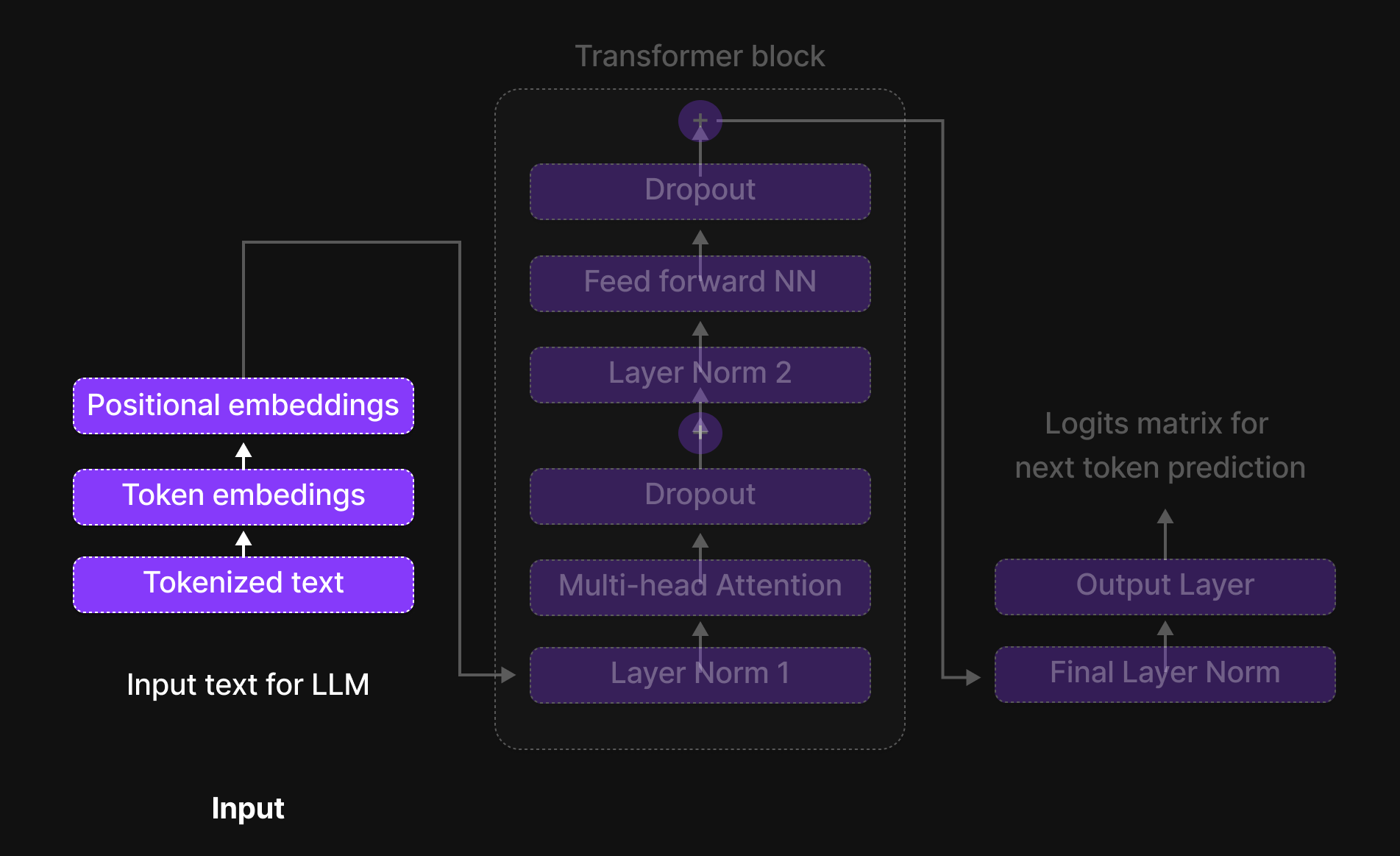 Figure 4: Input block
Figure 4: Input block
The journey of a sentence through a Large Language Model (LLM) begins with the input stage, where several key transformations take place before it enters the processing unit, commonly known as the Transformer block.
First, the raw text undergoes tokenization, a process where the sentence is broken down into smaller units called tokens—these could be words, subwords, or characters, depending on the tokenization method used. This step ensures that the model can handle language efficiently,
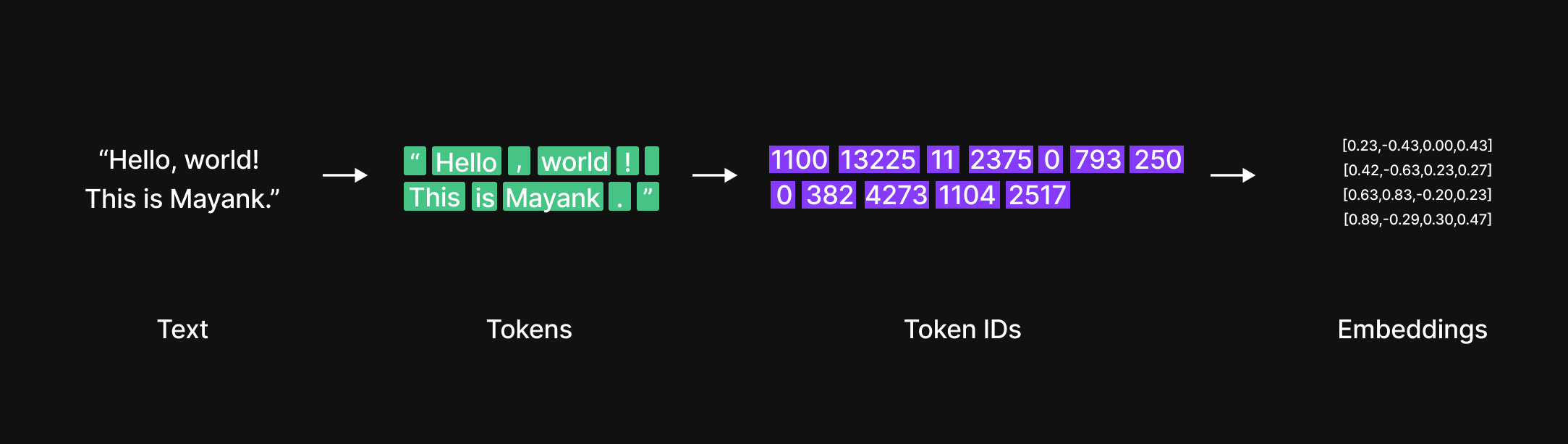
Next, each token is converted into a numerical representation through token embeddings. These embeddings assign a unique vector to each token, capturing semantic meaning and relationships between words. However, since token embeddings alone do not preserve the sequence order, we introduce positional embeddings. These embeddings encode the position of each token within the sentence, allowing the model to understand the order and structure of the input.
With tokenization, token embeddings, and positional embeddings in place, the input is now fully prepared for the Transformer block, where deep learning mechanisms, such as multi-head attention and feed-forward neural networks, process the text to generate meaningful predictions.
Processor Stage of an LLM: Transformer Block
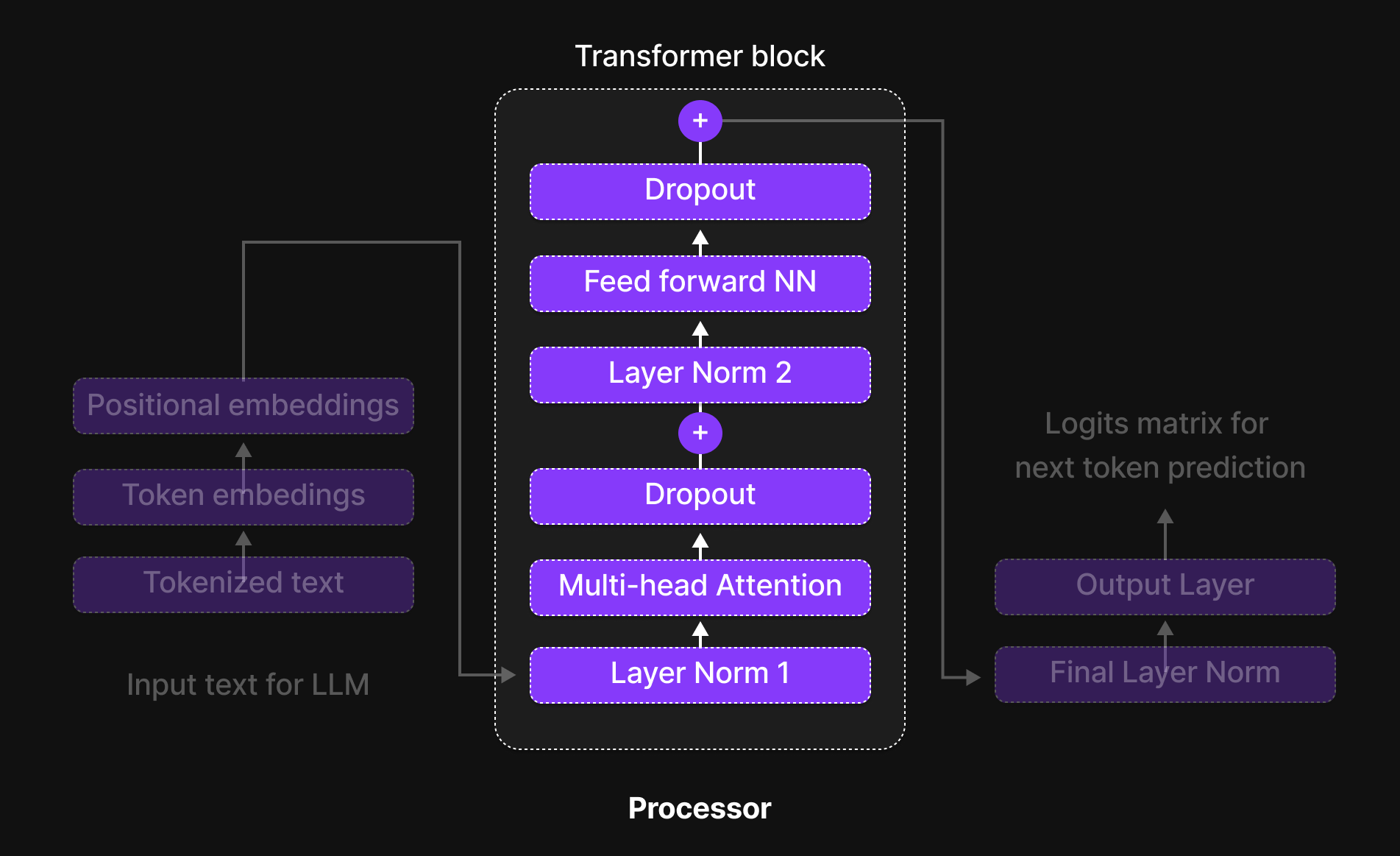 Figure 6: Processor: Transformer block
Figure 6: Processor: Transformer block
Once the input undergoes tokenization and embedding, it enters the Transformer Block, the core processing unit of a Large Language Model (LLM). Within this block, multiple layers work together to extract patterns, contextual relationships, and dependencies within the text.
The Transformer Block consists of six key components that process the input sequentially:
- Normalization Layer – Ensures stable and efficient training by standardizing activations.
- Multi-Head Attention Layer – Captures relationships between words in a sentence, even those far apart, by allowing the model to focus on different parts of the input simultaneously.
- Dropout Layer – Helps prevent overfitting by randomly deactivating some neurons during training.
- Normalization Layer 2 – Another layer of normalization to maintain stability.
- Feed-Forward Neural Network (FFNN) – A fully connected layer that transforms and refines the information extracted by attention.
- Dropout Layer 2 – Adds another level of regularization to ensure robustness.
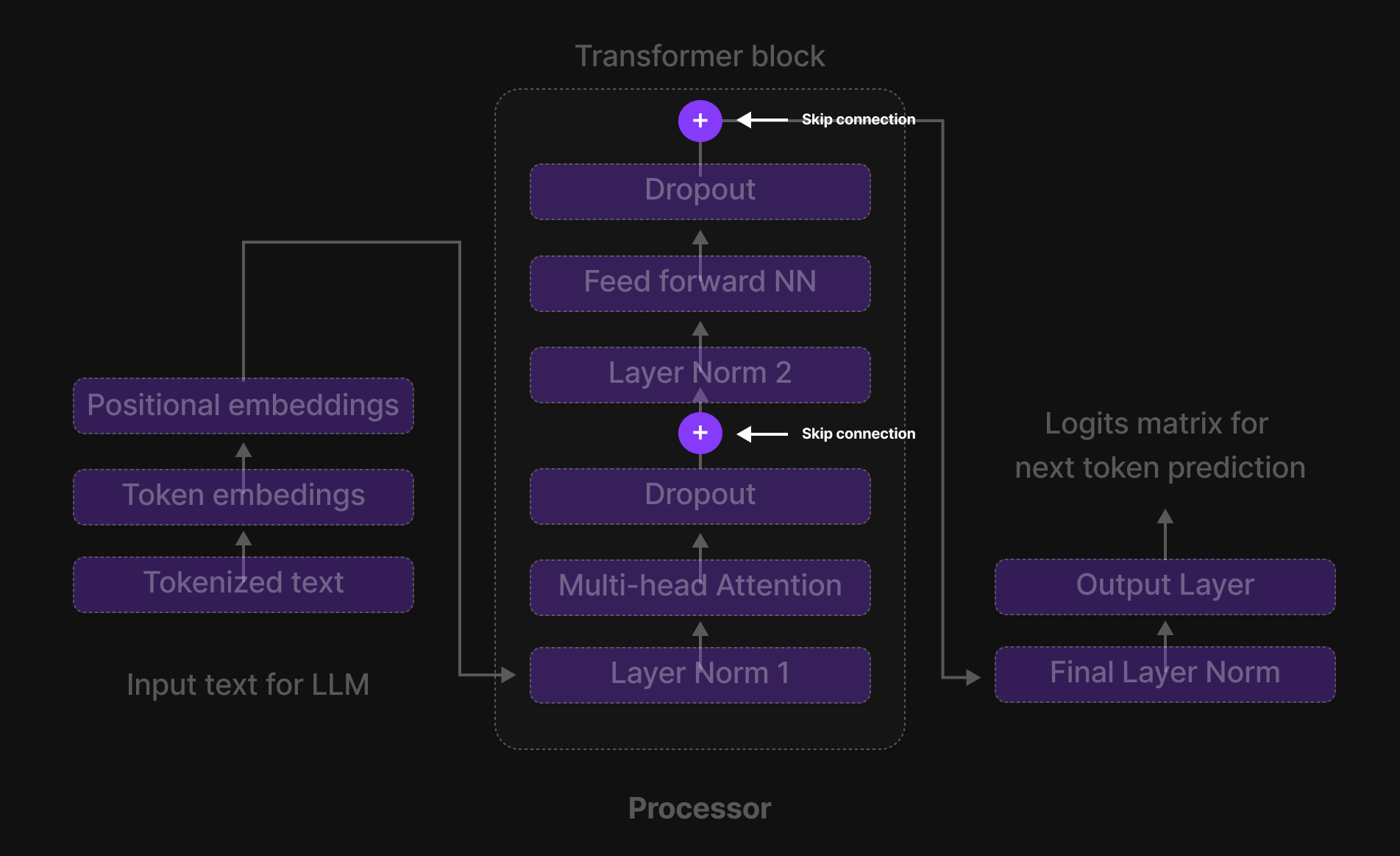
Additionally, the plus signs (+) in the architecture represent skip connections (or shortcut connections). These connections allow the model to bypass certain layers and retain essential information from earlier stages, enabling smoother gradient flow and improving performance during training.
Together, these components form the backbone of the Transformer Block, making it capable of efficiently processing language data and learning complex patterns in text.
Output Block in LLM Architecture
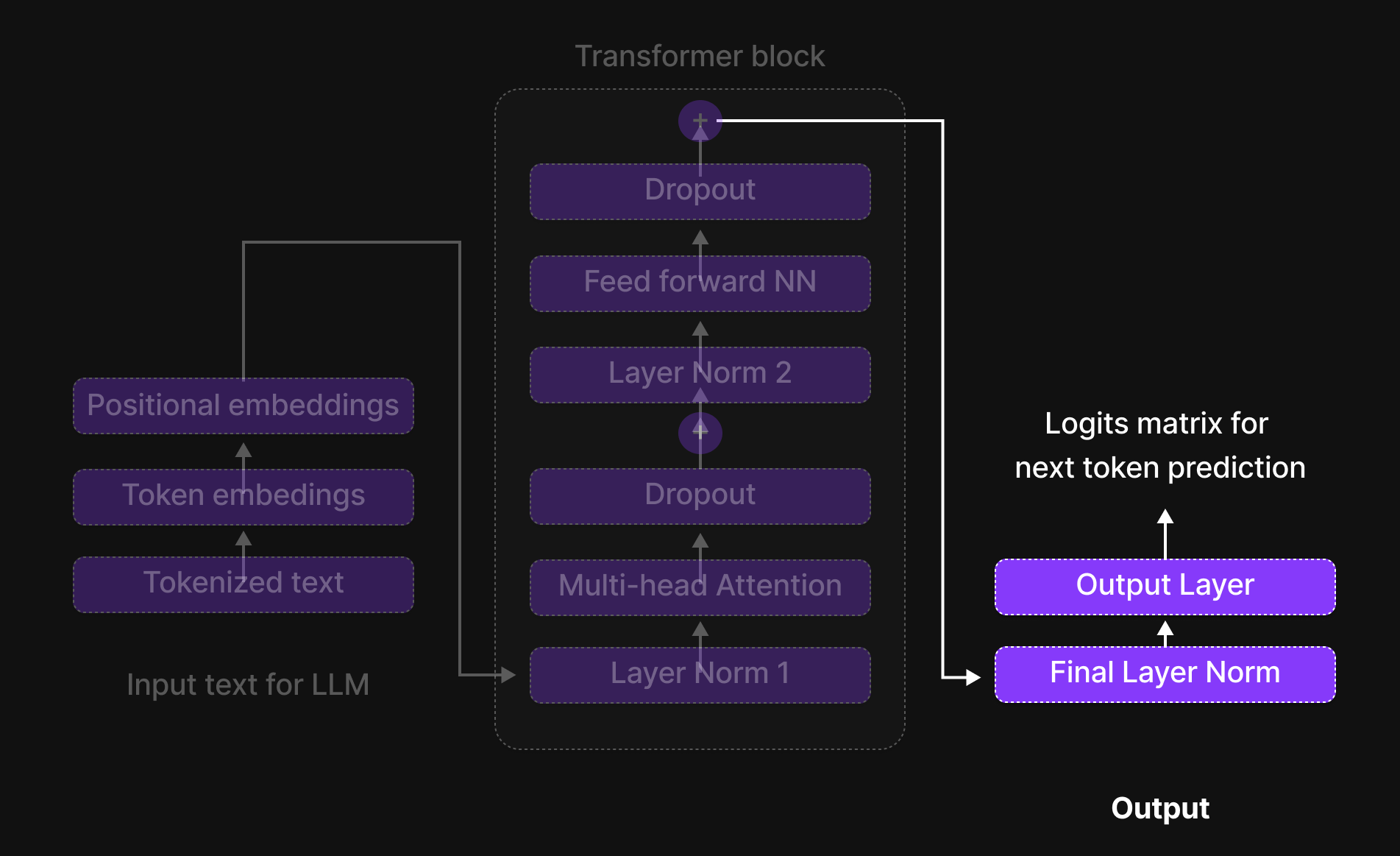 Figure 8: Output block
Figure 8: Output block
After the input passes through the Transformer Block, where complex computations like multi-head attention and feed-forward neural networks take place, we reach the Output Block—the final stage of processing in a Large Language Model (LLM).
The Output Block consists of two key components:
- Final Layer Normalization – This ensures that the processed information from the transformer block is well-scaled and stable before making predictions. It prevents extreme variations in values and helps maintain consistency.
- Output Layer – This layer generates a logits matrix, which represents the probability distribution for the next token prediction. Essentially, it calculates scores for all possible next tokens, and the token with the highest score is selected as the most probable next word in the sequence.
At this stage, the model has successfully processed the input text, understood its context, and predicted the next token, contributing to the generation of meaningful and coherent text.
What Has DeepSeek Done?
 Figure 9: High-performance sports car
Figure 9: High-performance sports car
Imagine you’re a car enthusiast, and you come across a high-performance sports car that has been breaking records. Naturally, you're curious—what makes this car so fast and efficient?
 Figure 10: Car engine
Figure 10: Car engine
You pop open the hood and start examining the engine. You notice that, while it has many of the same parts as other cars, two key components have been upgraded in a way that significantly boosts its speed and efficiency. Maybe it's an advanced turbocharger or a more efficient fuel injection system—something that gives it an edge over the competition.
This is exactly what’s happening with DeepSeek in the world of LLMs. It has the same foundational structure as previous models, but it introduces specific architectural improvements that enhance its performance,
DeepSeek has introduced innovations in two key areas of the traditional transformer model:
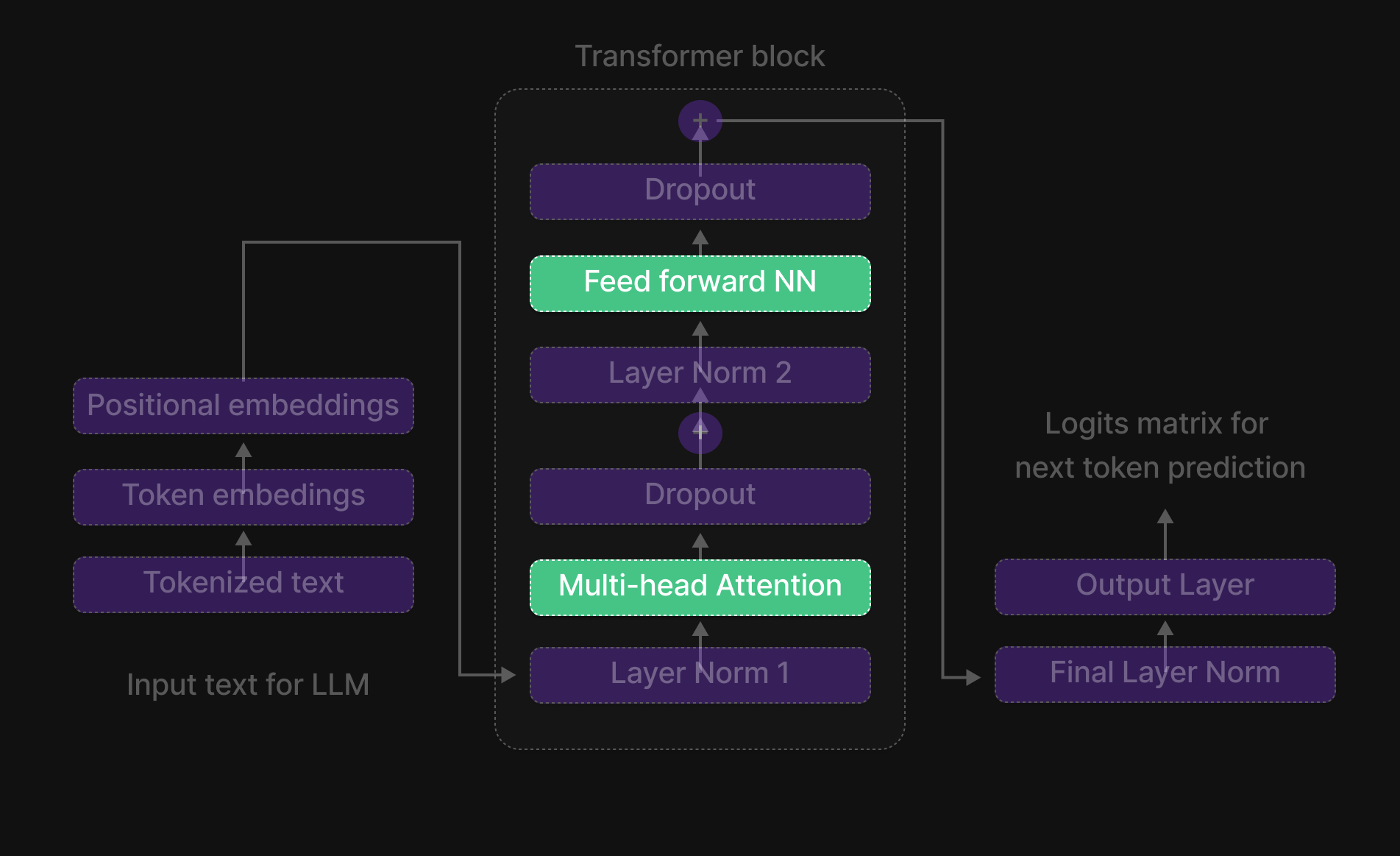 Figure 11: Deepseek innovation in traditional transformer
Figure 11: Deepseek innovation in traditional transformer
- Multi-Head Attention Block
- Feed-Forward Neural Network (FFNN)
One crucial component to focus on is Multi-Head Attention, as Multi-Head Latent Attention plays a significant role in this part of the architecture.
The innovation of Multi-Head Latent Attention was introduced in the Multi-Head Attention block, while Mixture of Experts (MoE) was implemented in the Feed-Forward Neural Network (FFNN) layer of the traditional LLM architecture.
Mixture of Experts (MoE) in Feed-Forward Networks
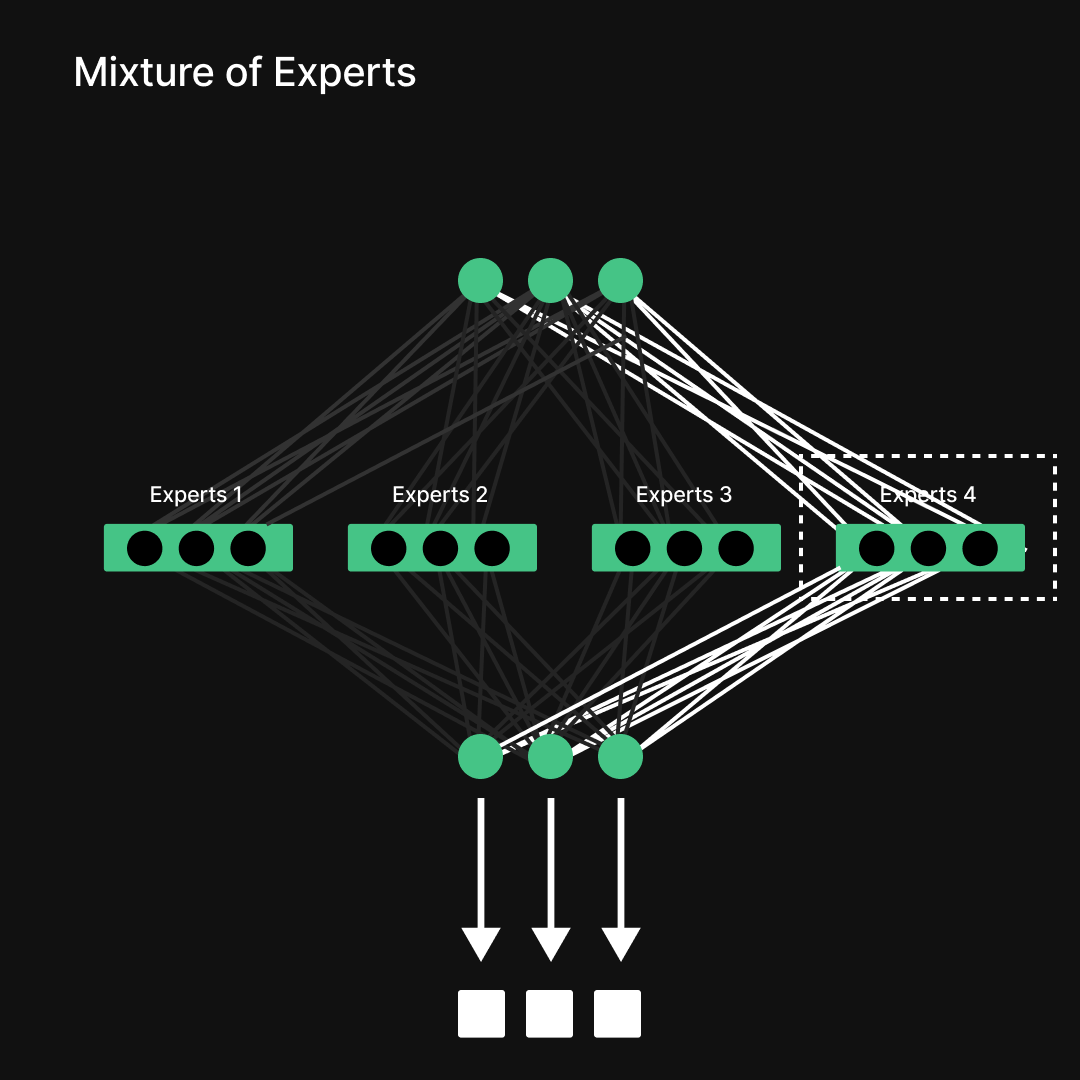
A major innovation in DeepSeek, is the Mixture of Experts (MoE) architecture within the Feed-Forward Network. Instead of activating all parameters at once, MoE selects only a subset of specialized "expert" networks per token, making computations more efficient.
- MoE dynamically activates different "expert" FFN layers based on the input token, ensuring only relevant computations are performed.
- This approach significantly reduces computational cost while maintaining the model's expressive power.
By leveraging Mixture of Experts, LLMs can scale to trillions of parameters without requiring excessive computational resources, making them more efficient while preserving high-level language understanding.
Multi-Head Latent Attention
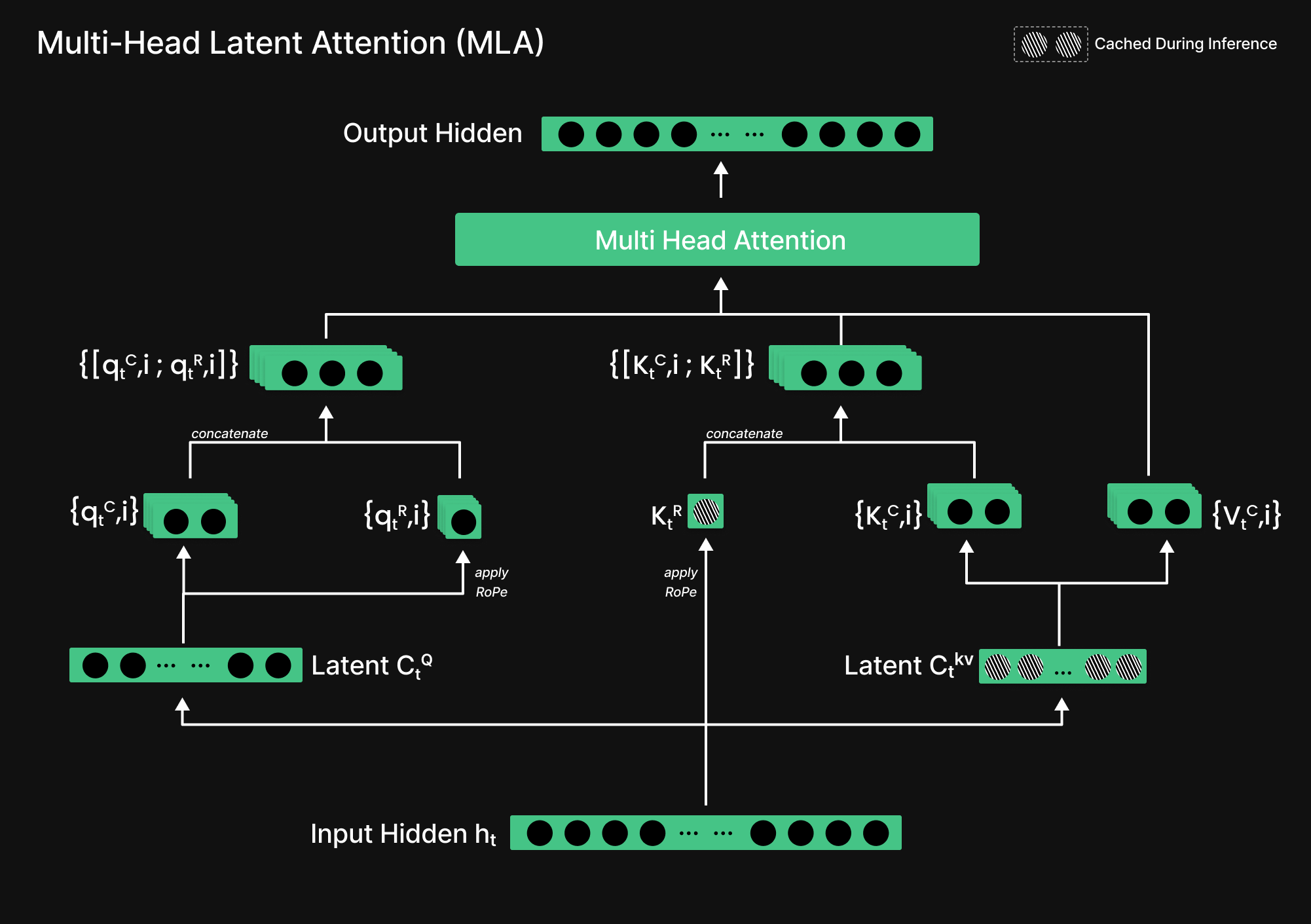 Figure 13: Multi-Head Latent Attention
Figure 13: Multi-Head Latent Attention
Multi-Head Attention (MHA) is a mechanism in transformer models that allows the model to focus on different parts of the input simultaneously by using multiple attention heads. Each head processes the input independently, capturing different aspects of the context, and their outputs are then combined to enhance the model’s understanding. However, MHA can be computationally expensive, especially during inference, due to the need to store and process large key-value pairs. Multi-Head Latent Attention (MLA) optimizes this by compressing attention inputs into a smaller latent space, significantly reducing memory usage while maintaining strong performance. This is achieved through down-projection to a low-dimensional representation, followed by up-projection when computing attention scores, striking a balance between efficiency and accuracy.
I will cover Mixture of Experts & Multi-head latent attention in details in another blog.
Conclusion
In this blog, we explored the high-level architecture of Large Language Models (LLMs), breaking it down into three key stages: Input, Processing, and Output. We discussed how tokens are transformed into numerical representations, processed through transformer blocks using multi-head attention and feed-forward networks, and finally converted into meaningful text predictions. Additionally, we highlighted DeepSeek’s innovations, particularly Multi-Head Latent Attention (MLA) and Mixture of Experts (MoE), which enhance efficiency and scalability. However, this was just an overview, not an in-depth technical breakdown. In our next blog, Journey of a Token Through the LLM Architecture, we will dive deeper into each step, tracing how a token moves through the model to gain a more detailed understanding of these mechanisms in action. Stay tuned!
I’m also building ML and LLM projects, sharing and discussing them on LinkedIn and Twitter. If you’re someone curious about these topics, I’d love to connect with you all!
LinkedIn : mayankpratapsingh022
Twitter/X : Mayank_022
Stay curious, keep learning, and let’s continue unraveling the future of AI together!