[2] Advanced RAG: Enhancing Retrieval with Parallel Queries and Reciprocal Rank Fusion
Mayank Pratap Singh
@Mayank Pratap Singh
![[2] Advanced RAG: Enhancing Retrieval with Parallel Queries and Reciprocal Rank Fusion](/_next/image?url=%2Fimages%2Fblog%2FRankfusion%2F15.gif&w=1920&q=75)
Table of contents
- Parallel Query Retrieval [Multi-Query RAG]
- Basic RAG vs Parallel Query RAG
- Example
- Implementation: Multi-Query Retrieval in LangChain (with Qdrant)
- Step 1: Set Up the Vector Store with Embedded Documents
- Step 2: Configure the MultiQueryRetriever with an LLM
- Step 3: Retrieve Documents with the Multi-Query Approach
- Developer’s Note
- Basic RAG vs Parallel Query RAG
- Reciprocal Rank Fusion (RRF)
- Example
- Implementation: Combining Results with RRF
- Step 1: Define Query Variants
- Step 2: Perform Similarity Search for Each Query
- Step 3: Apply Reciprocal Rank Fusion (RRF)
- Step 4: Rank the Documents Based on Fused Scores
- Step 5: Display the Final Ranked List
- Bringing It All Together
If you're new to Retrieval-Augmented Generation (RAG), it's highly recommended to start with the fundamentals first. In my Introduction to RAG, I cover the core concepts, workflow, and basic implementation patterns.
This article builds upon that foundation and explores advanced retrieval strategies like:
- Parallel Query Retrieval: increasing recall through diverse query formulations
- Reciprocal Rank Fusion (RRF): merging results for more robust document selection
Let’s dive into the next level of RAG.

Imagine this: you check your bank account balance at an ATM, and it shows an unexpected number.

To double-check, you open your mobile banking app – aha, the app reveals a pending transaction that explains the discrepancy.

That extra step of checking your balance twice saved you from a costly misunderstanding.

This everyday banking habit mirrors a powerful idea in building smarter AI: sometimes one look (or one query) isn’t enough. In the world of Large Language Models and Retrieval-Augmented Generation (RAG), asking multiple questions and combining answers can dramatically improve results.
In this blog, we’ll explore two advanced retrieval techniques used in Retrieval-Augmented Generation (RAG): Parallel Query Retrieval (Multi-Query RAG) and Reciprocal Rank Fusion (RRF). These techniques help improve the relevance and diversity of retrieved context by expanding and refining how queries interact with the vector database. We’ll walk through their underlying logic helping you build more accurate and robust LLM applications.
Parallel Query Retrieval [Multi-Query RAG]

You’ve just attempted an online bank transfer, but it failed without a clear explanation.

Frustrated, you take a multi-pronged approach: you call customer support, check your email for alerts, and refresh your transaction history in the banking app, all at once. Each source gives a snippet of insight: the support agent mentions an “invalid account number,” an email alert suggests “exceeded transfer limit,” and your app simply flags the transaction as failed. Individually, none of these explanations is satisfying.

But together, they paint a fuller picture: maybe a typo in the account number triggered a security block and hit a daily limit. By asking multiple people and systems in parallel, you’ve broadened your search for answers and increased your chances of finding the truth.
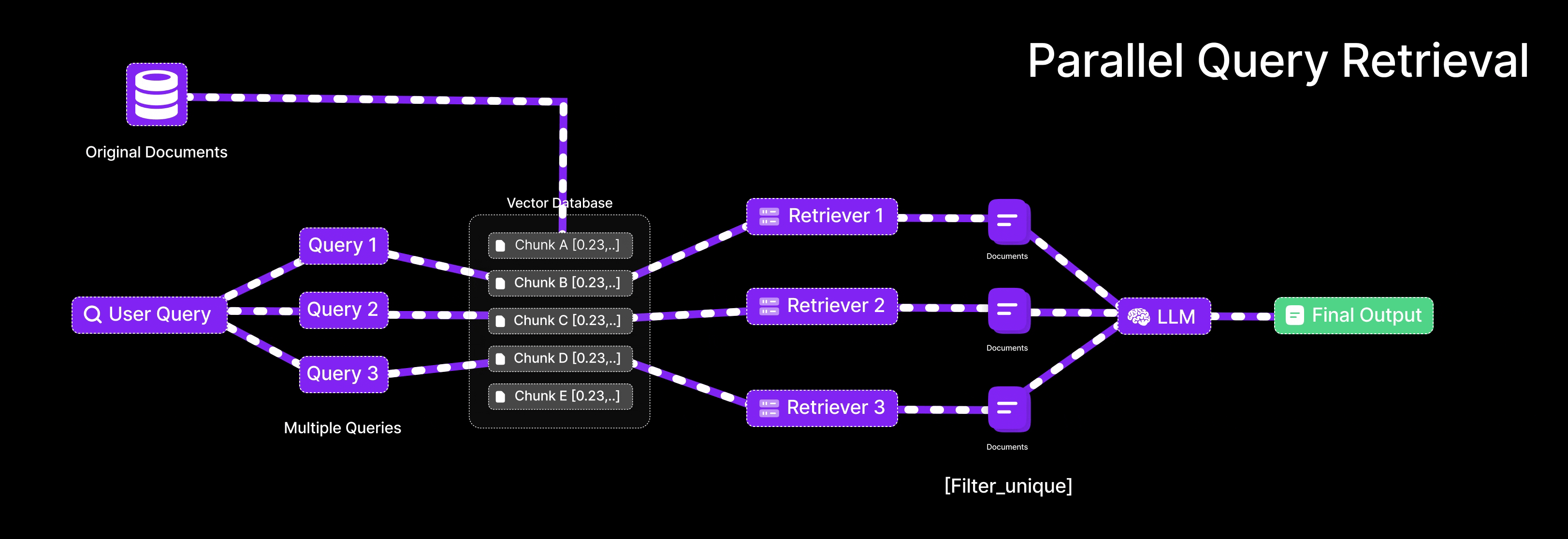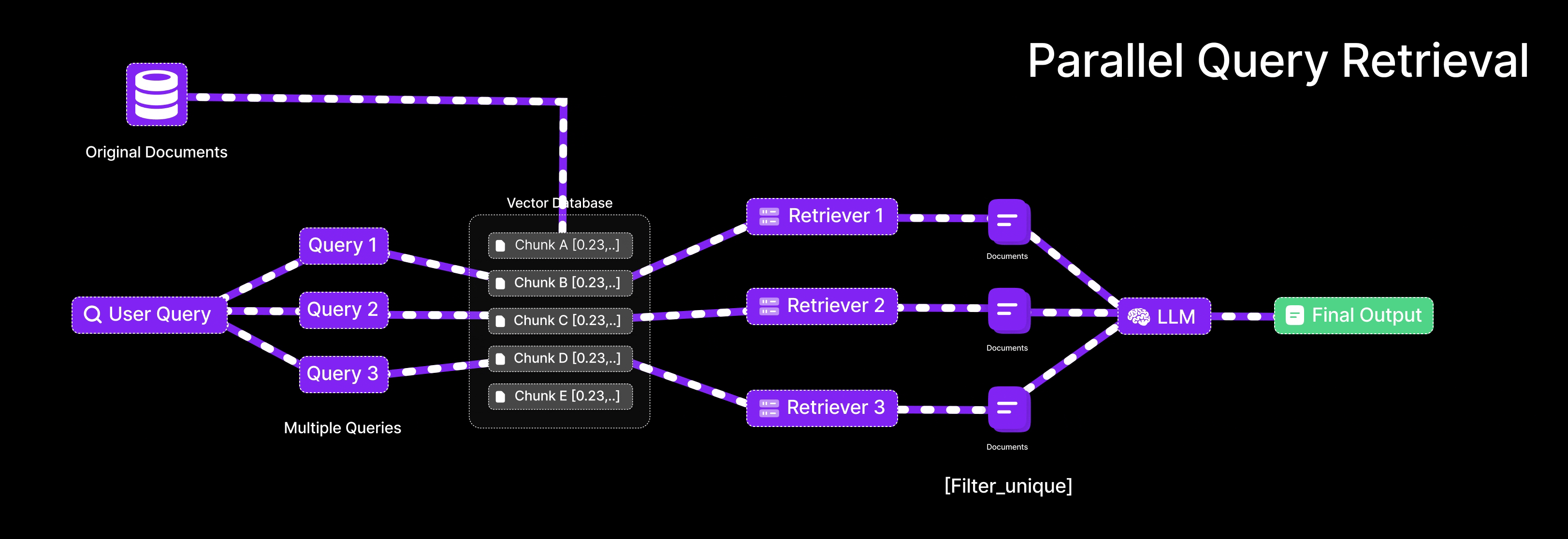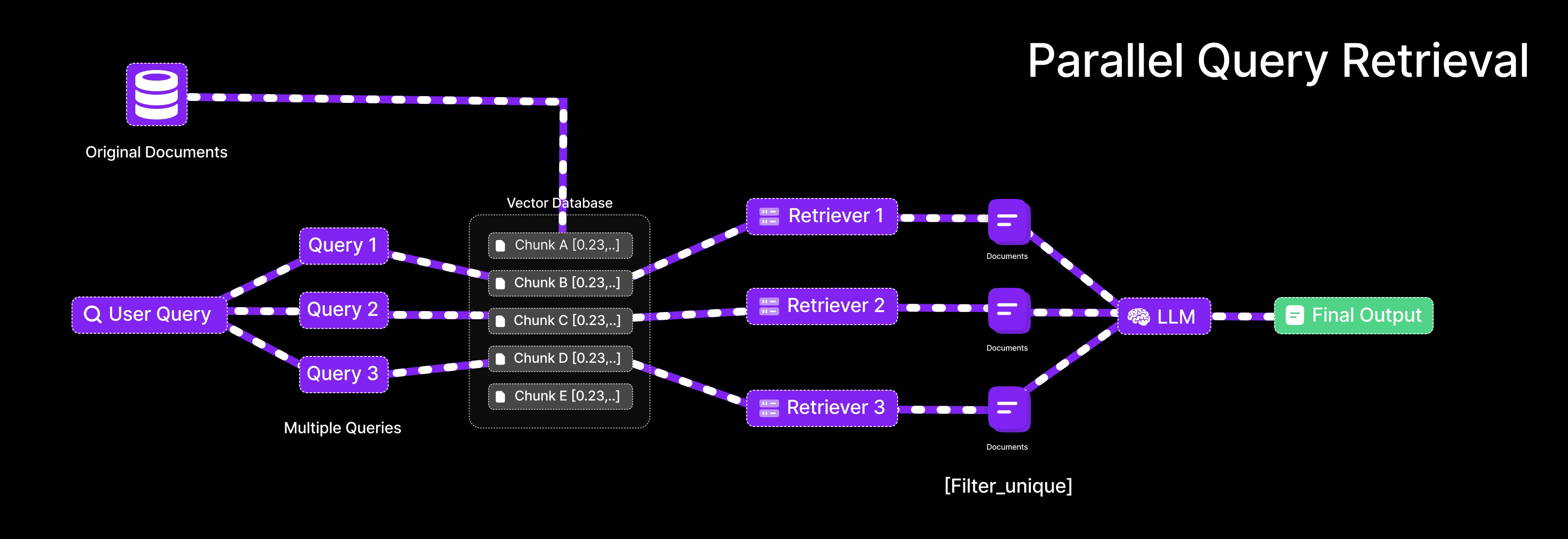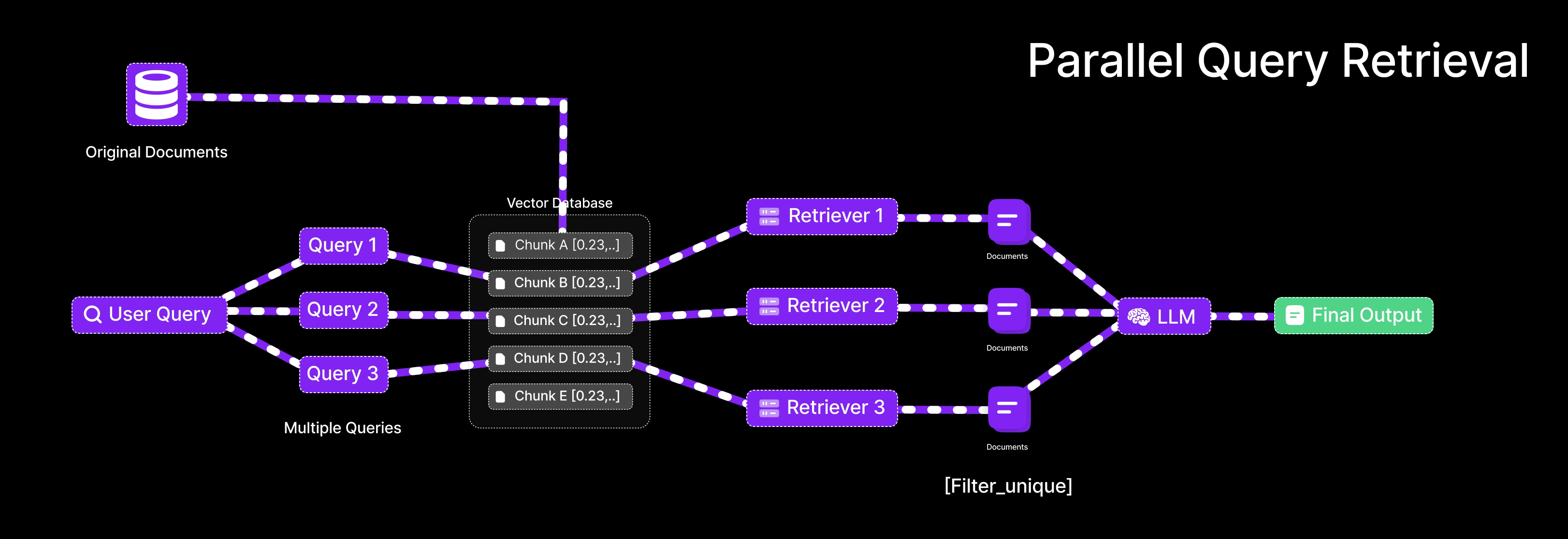
This is exactly what Parallel Query Retrieval does for an LLM: instead of relying on one formulation of a question, it issues multiple queries simultaneously (or in quick succession) to cover different angles. In Retrieval-Augmented Generation, that means an LLM isn’t stuck with a single shot at finding relevant documents – it can reformulate the user’s question in several ways and gather a richer set of results.
Just like you didn’t stop at the ATM, LLM shouldn’t stop at just one query
Basic RAG vs Parallel Query RAG
In a basic RAG setup, you take the user’s question, turn it into an embedding, and use that to find the most relevant documents from a vector database.
But here’s the thing RAG is quite sensitive to how the question is phrased. Just changing a few words can lead to completely different results. Parallel Query Retrieval solves this by creating several different versions of the original question, each with slightly different wording. This way, instead of relying on just one way of asking, it searches using multiple angles — helping you pull in a broader and more complete set of answers.
Example
- Converts this single query into an embedding.
User Query: “Why is my bank balance lower than expected?”
Basic RAG Behavior:
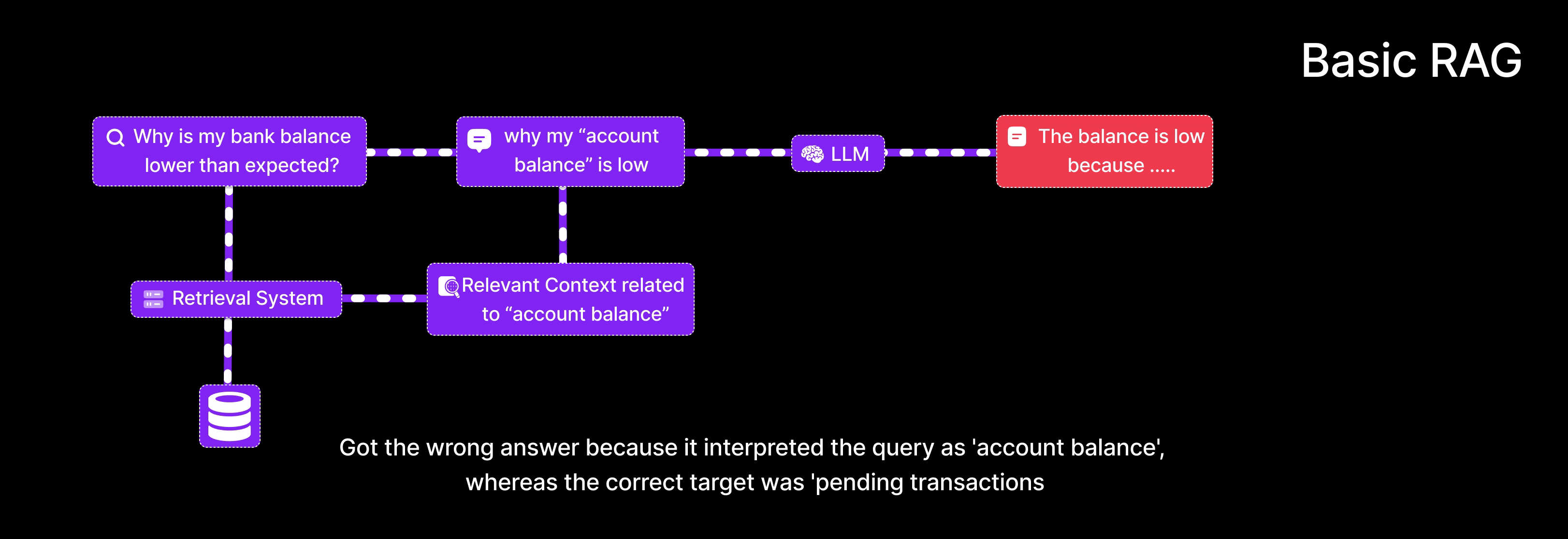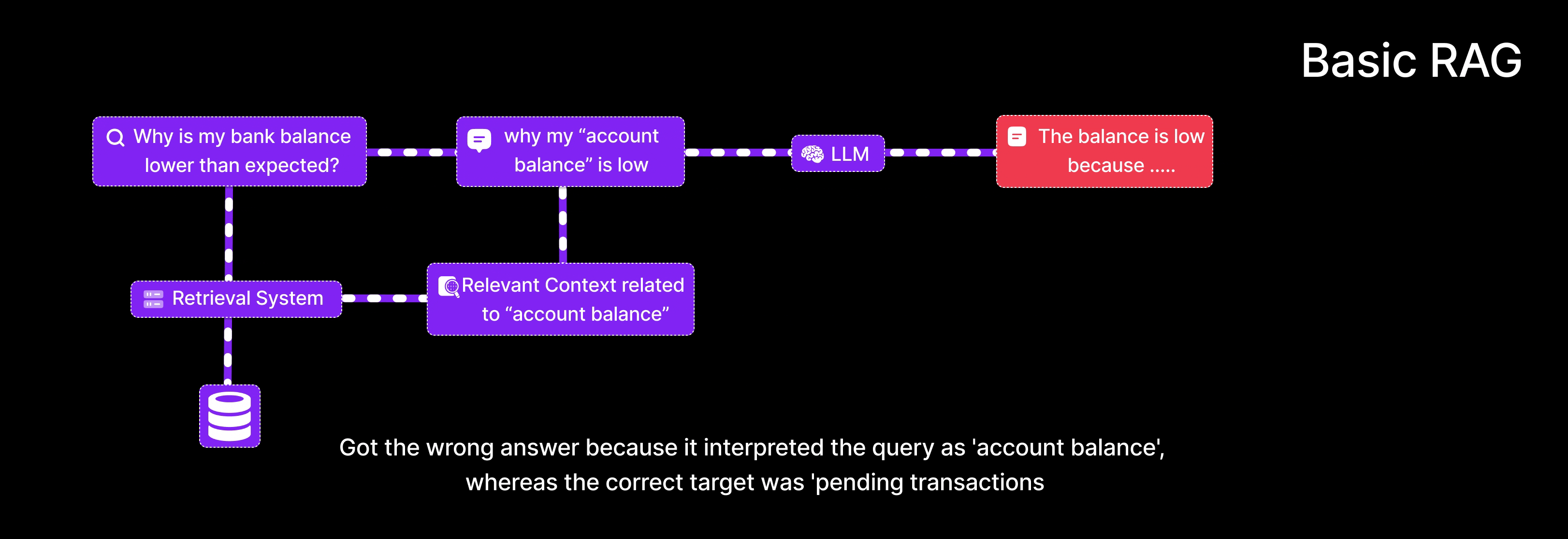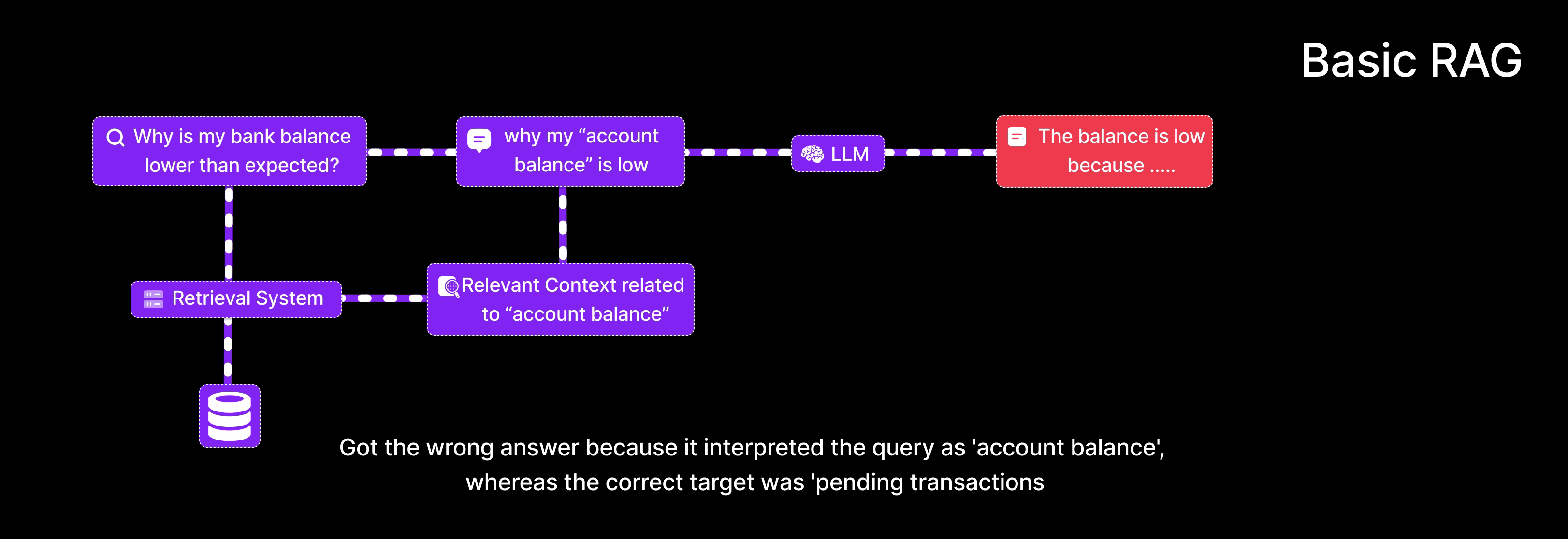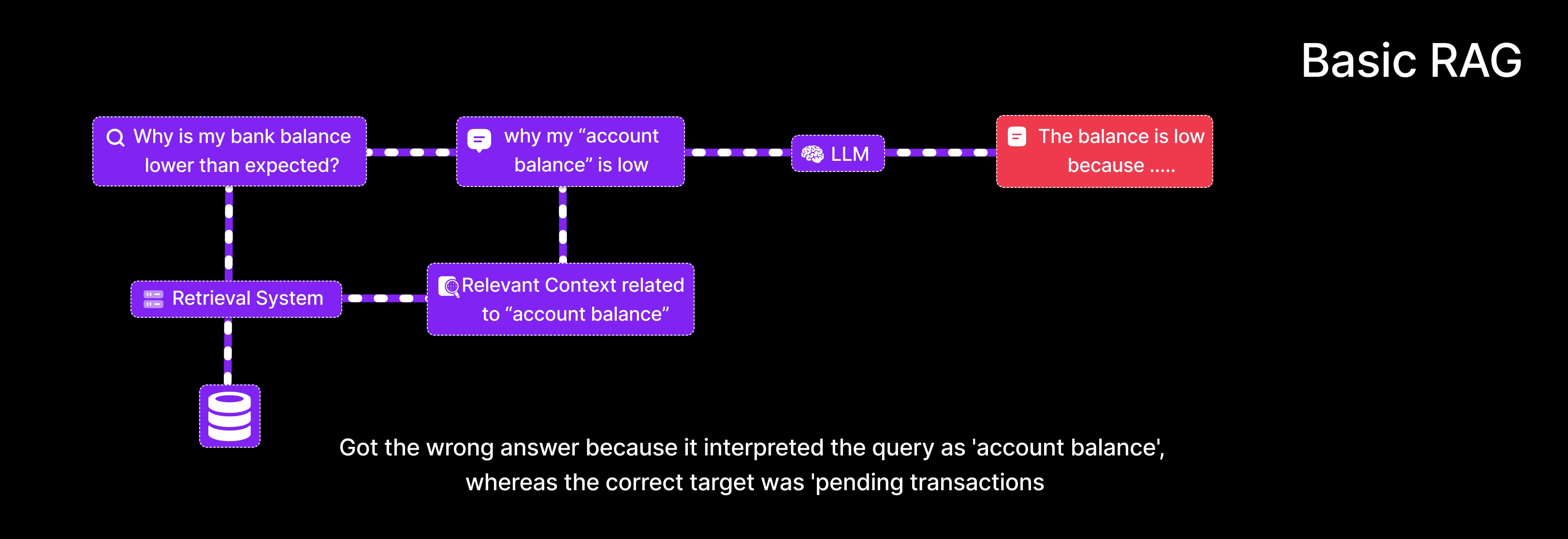
- Retrieves documents discussing general definitions of
account balance. - Returns an answer explaining what an account balance is.
- Potentially misses the actual cause (e.g., pending transactions, fees).
Parallel Query Retrieval Behavior:
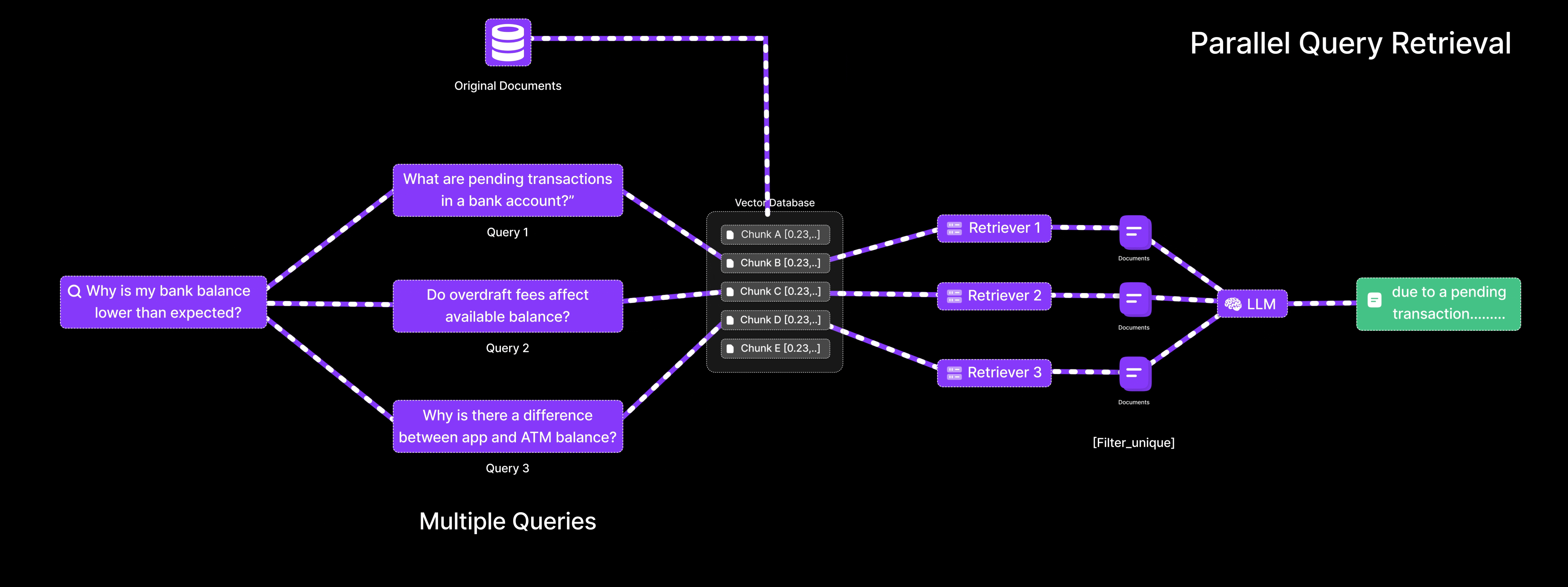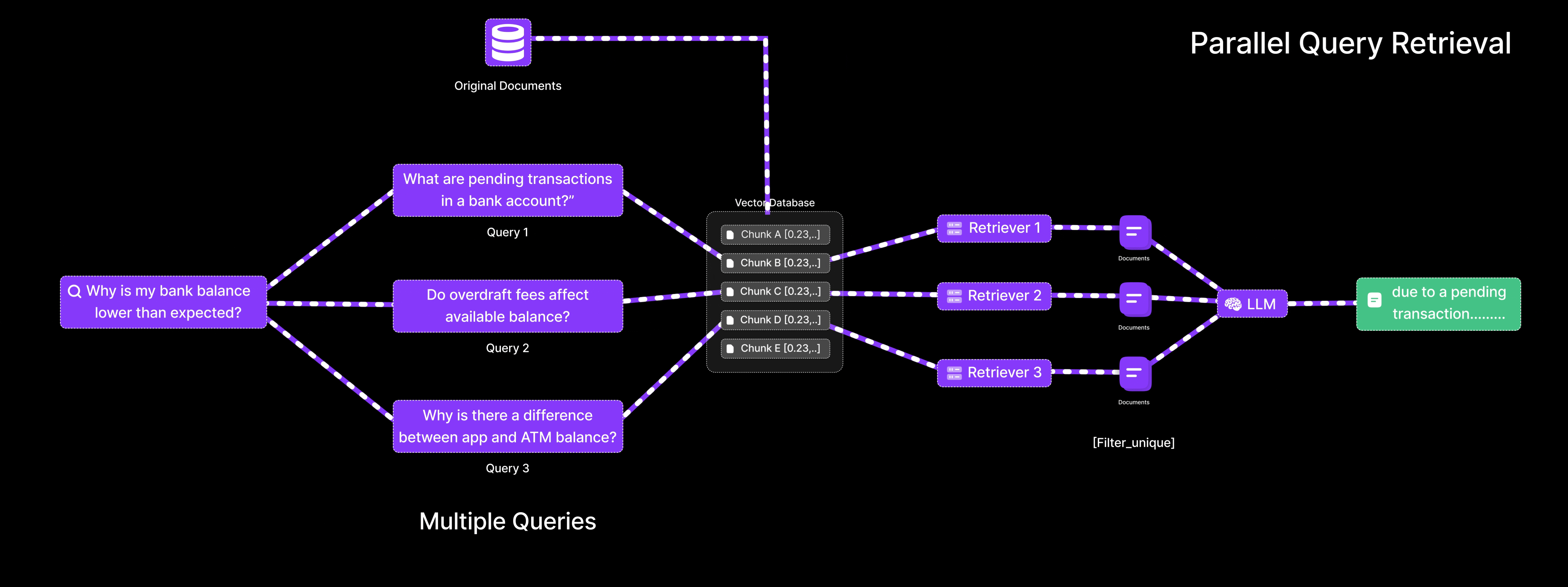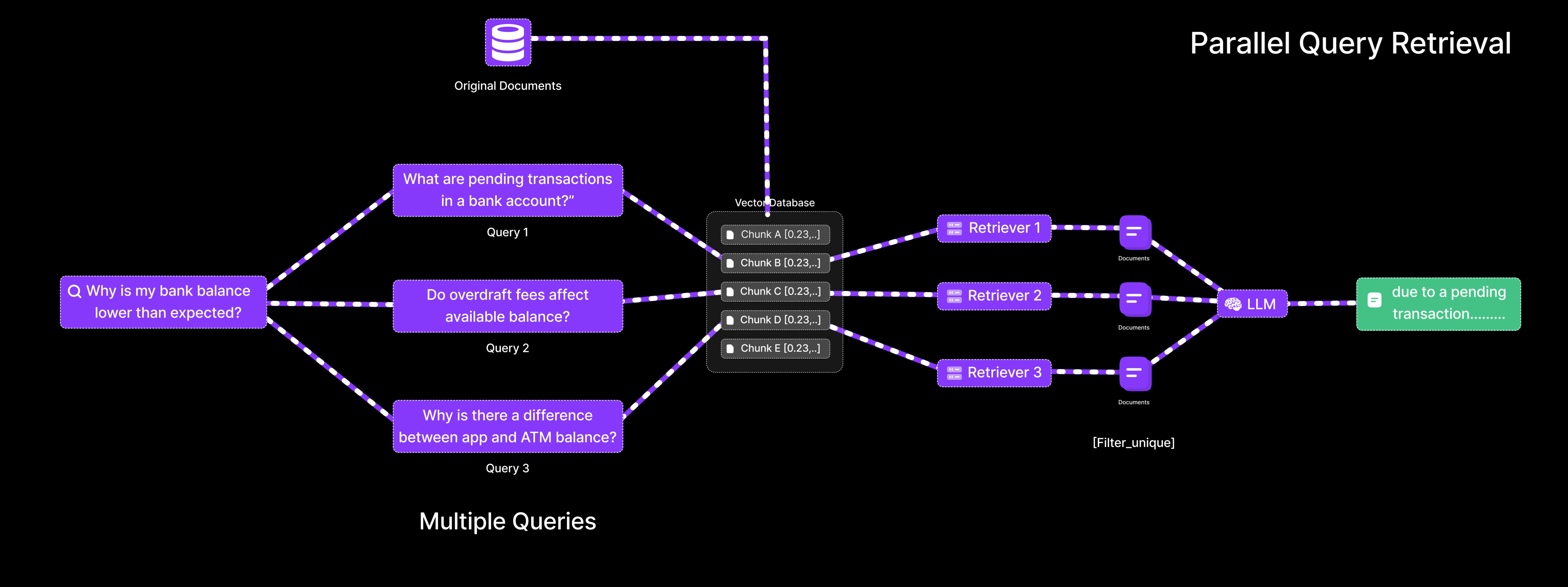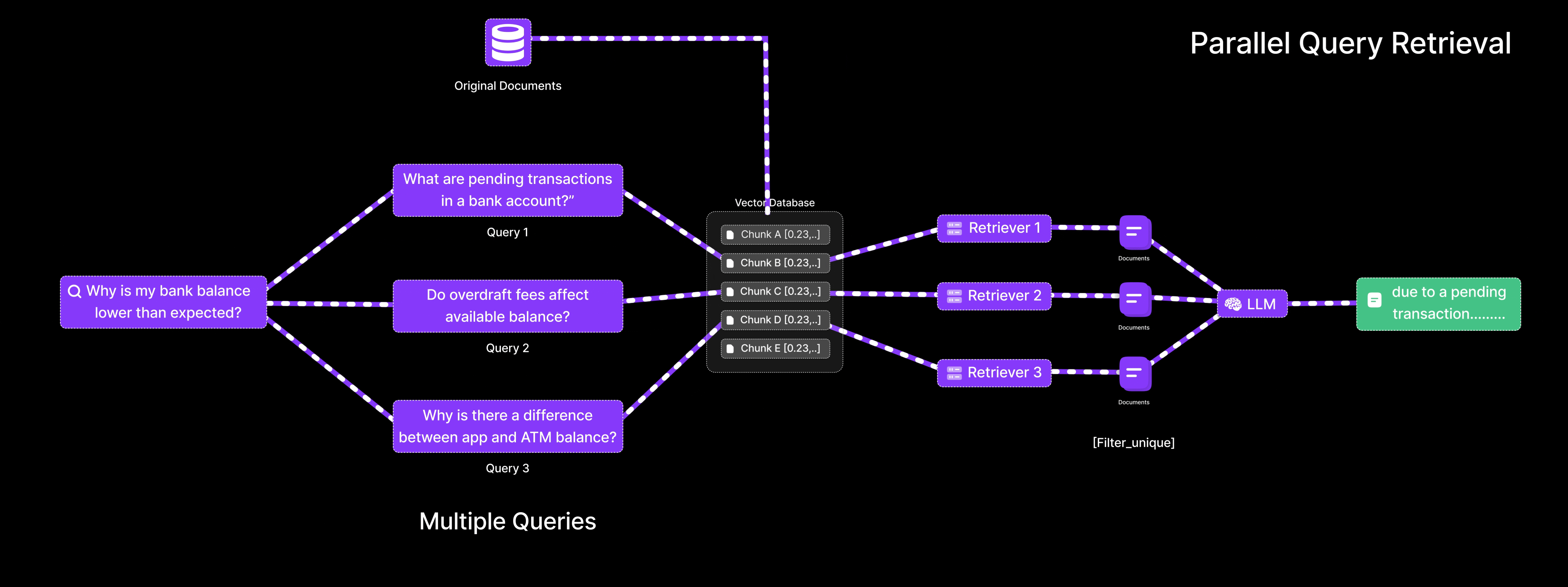
- Reformulates the query into multiple variations, such as:
- “What are pending transactions in a bank account?”
- “Do overdraft fees affect available balance?”
- “Why is there a difference between app and ATM balance?”
- Each query is embedded and searched independently.
- Retrieves a diverse set of context chunks covering all relevant factors.
- Merges the results and provides a more complete and accurate explanation.
Result: The system identifies that the balance discrepancy is due to a pending transaction and a recent fee deduction, information that would likely be missed with a single-query approach.
Query retrieval involves:
-
Query diversification:
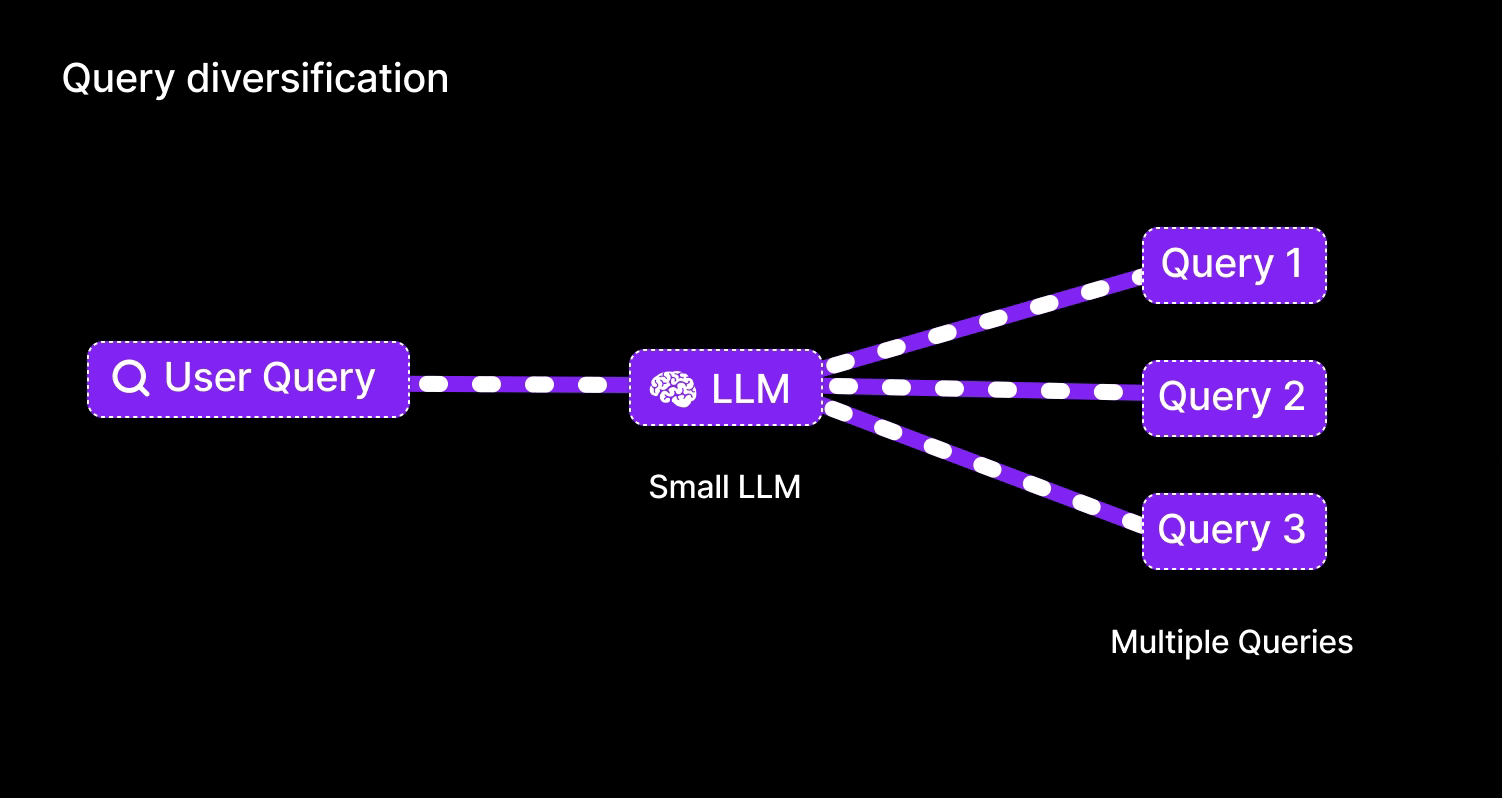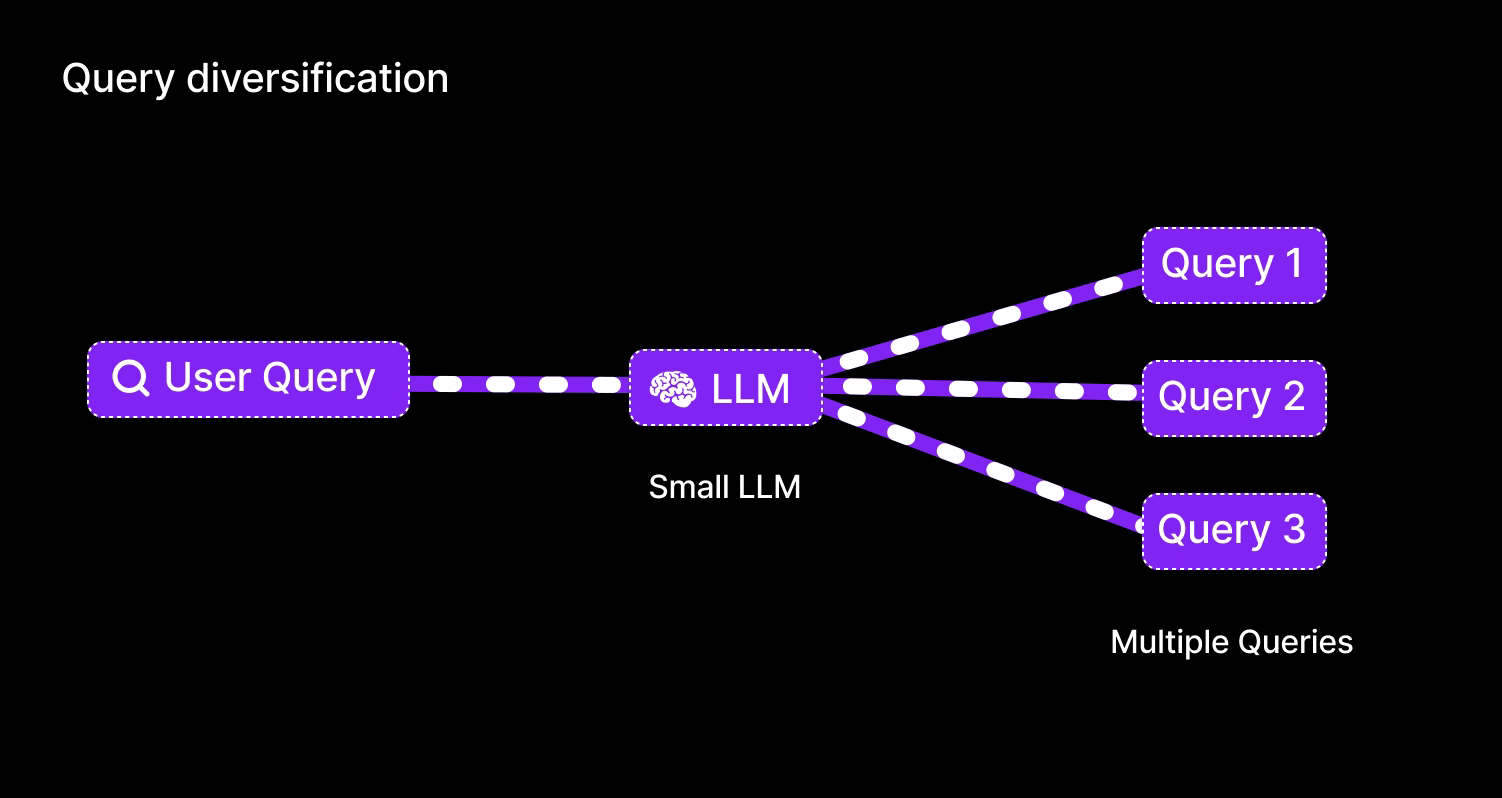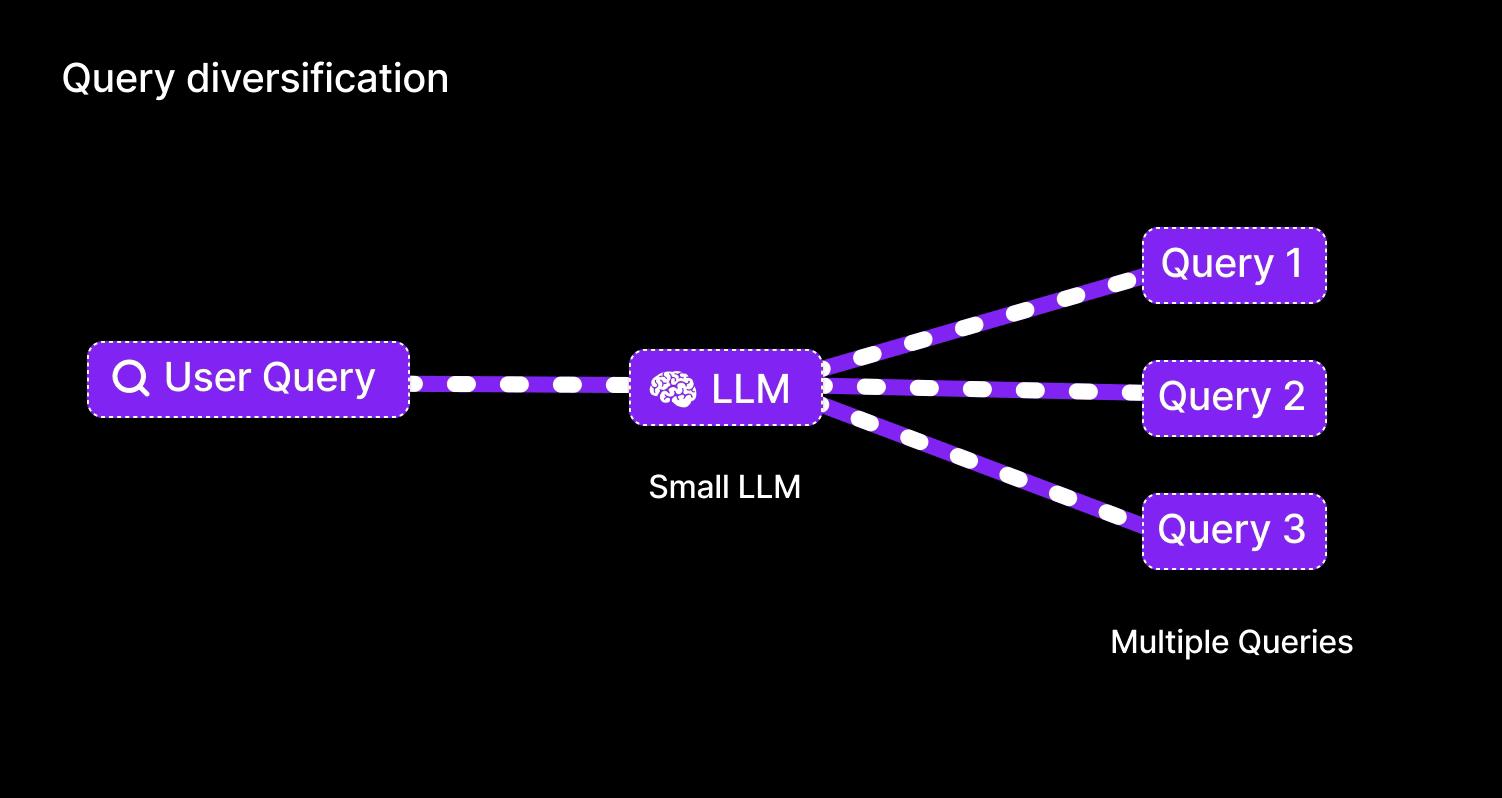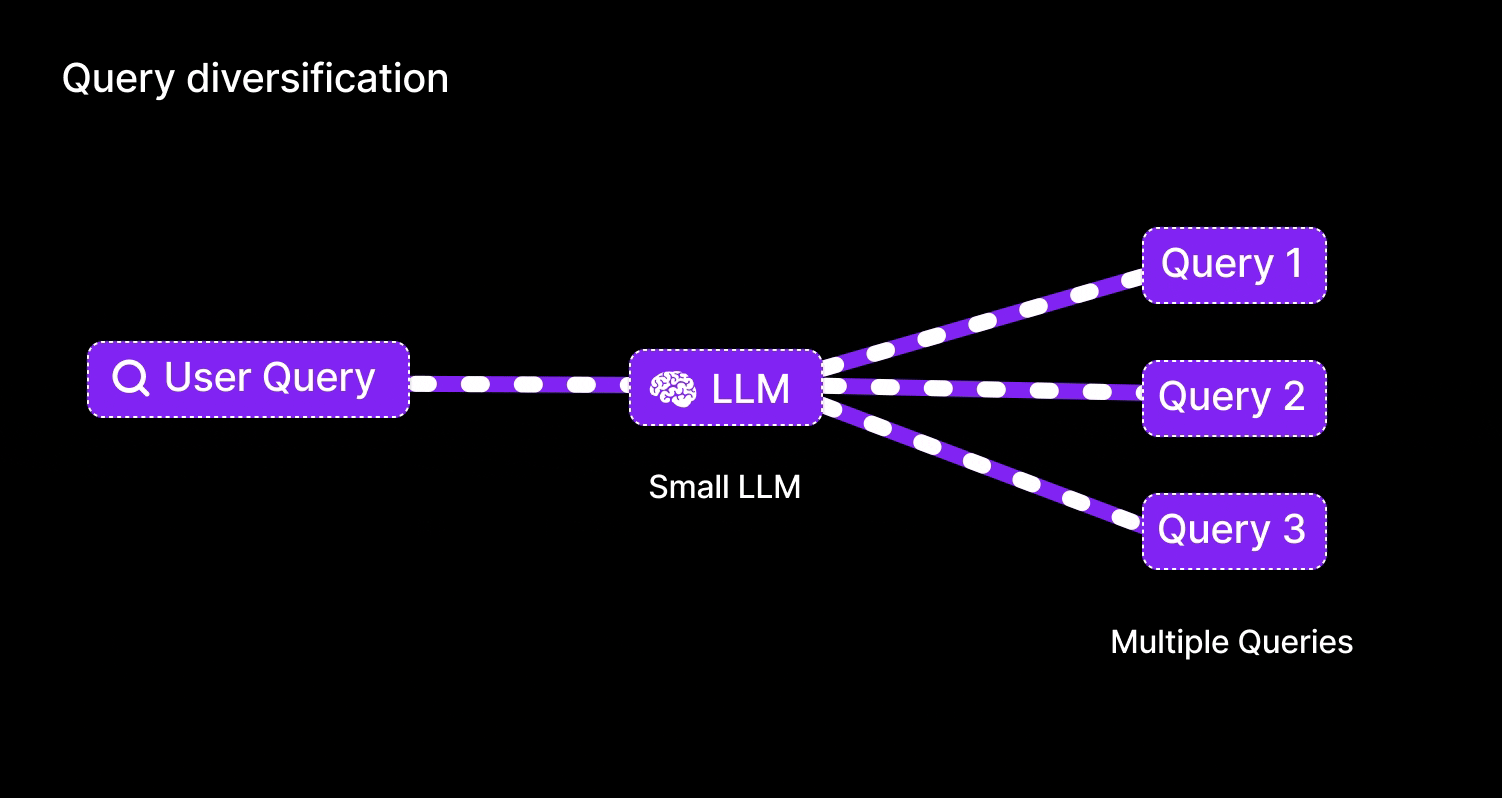
Use an LLM to create multiple query variants from the user’s original question (cover various phrasings or subtopics).
-
Parallel retrieval:
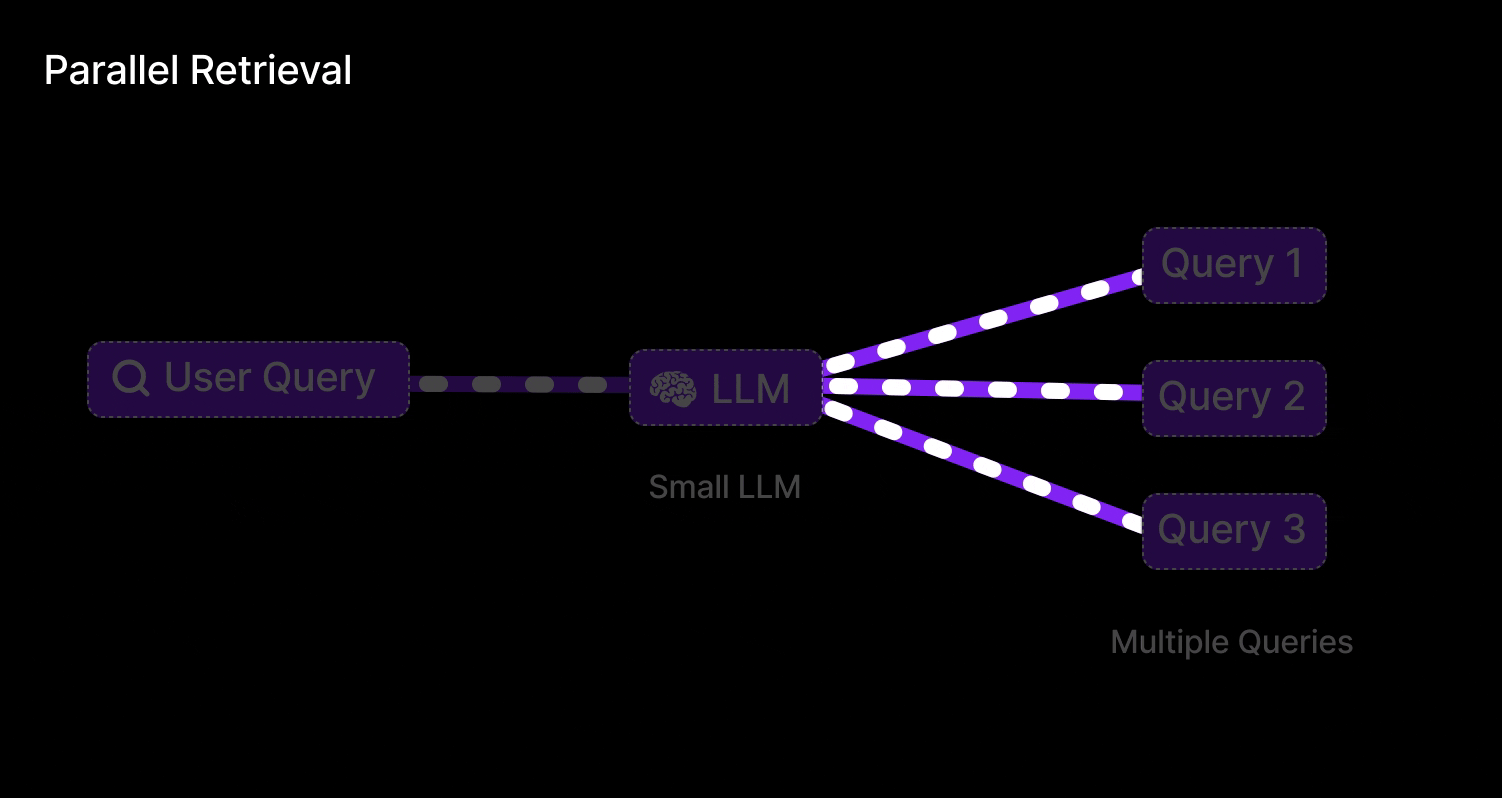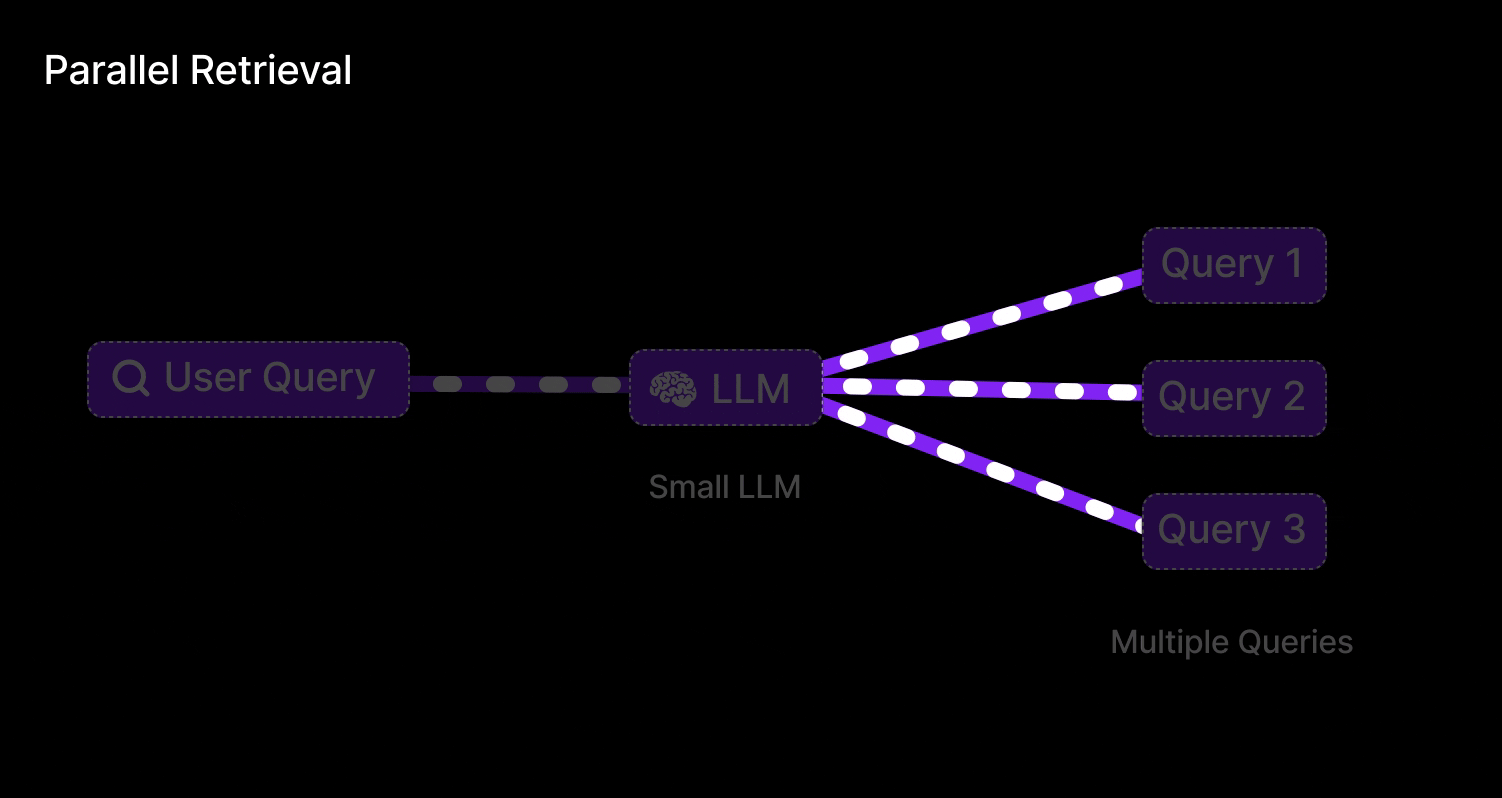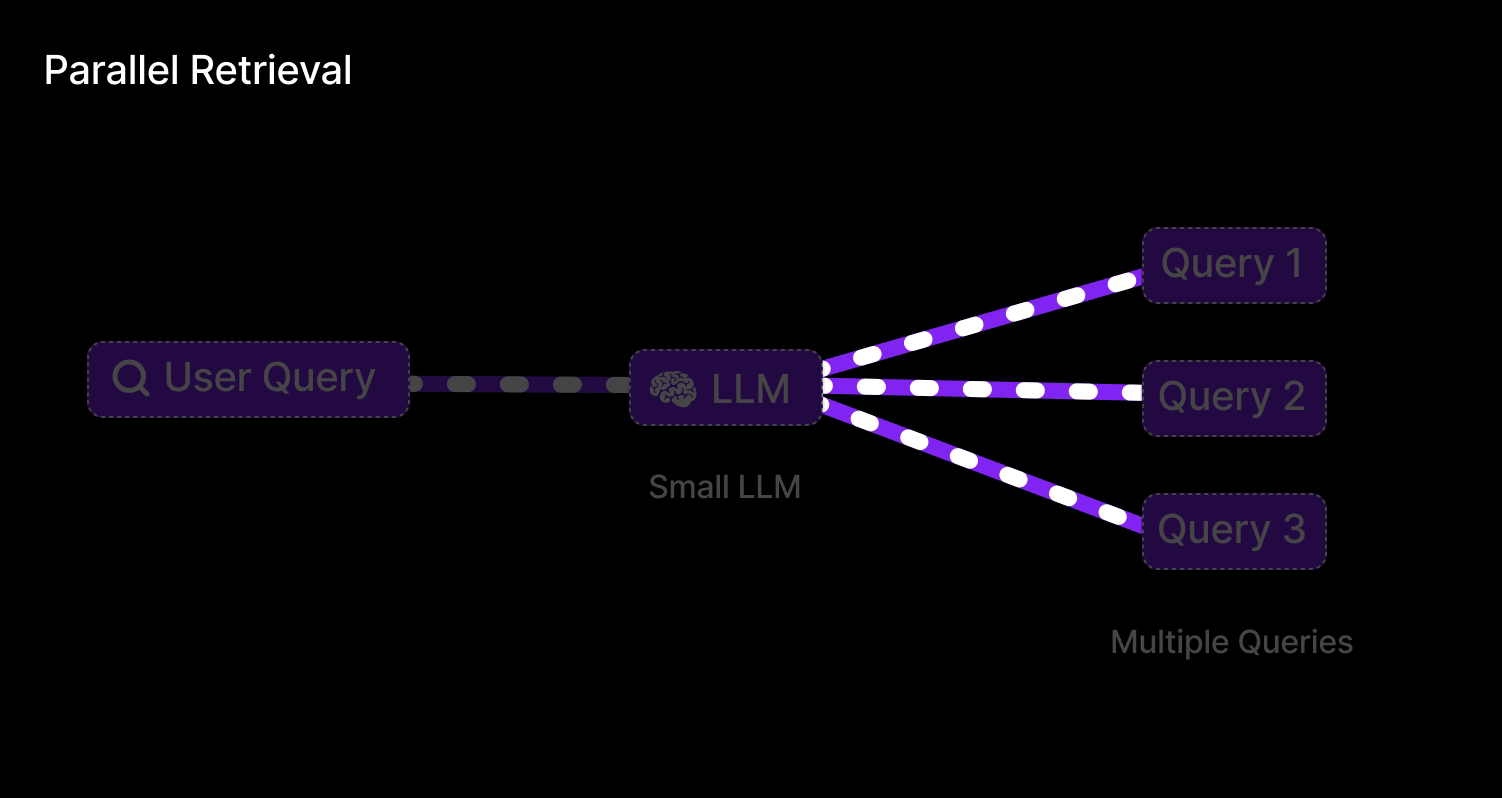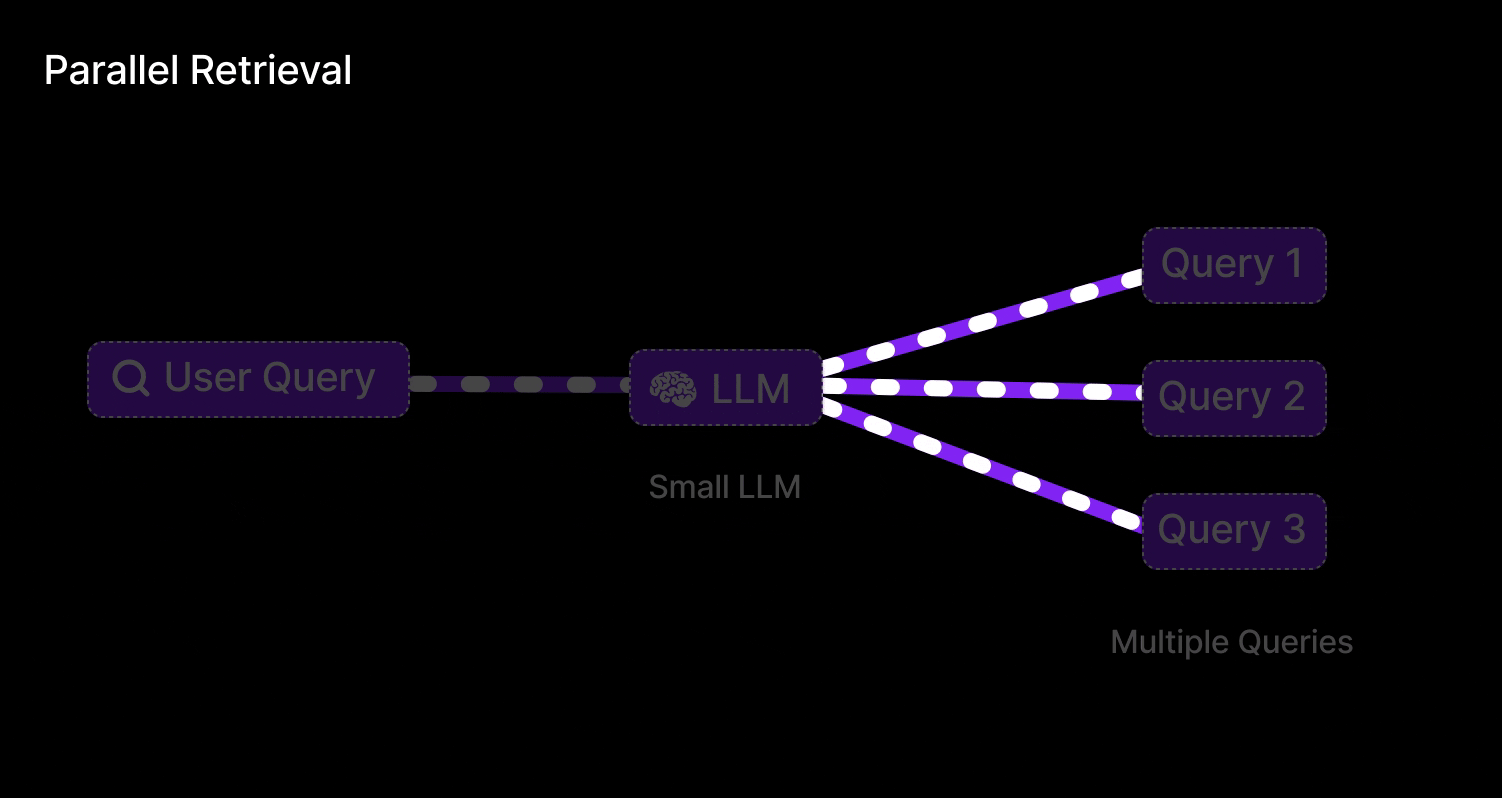
For each query variant, retrieve top-k documents from the vector store (this can be done in parallel).
-
Result union:
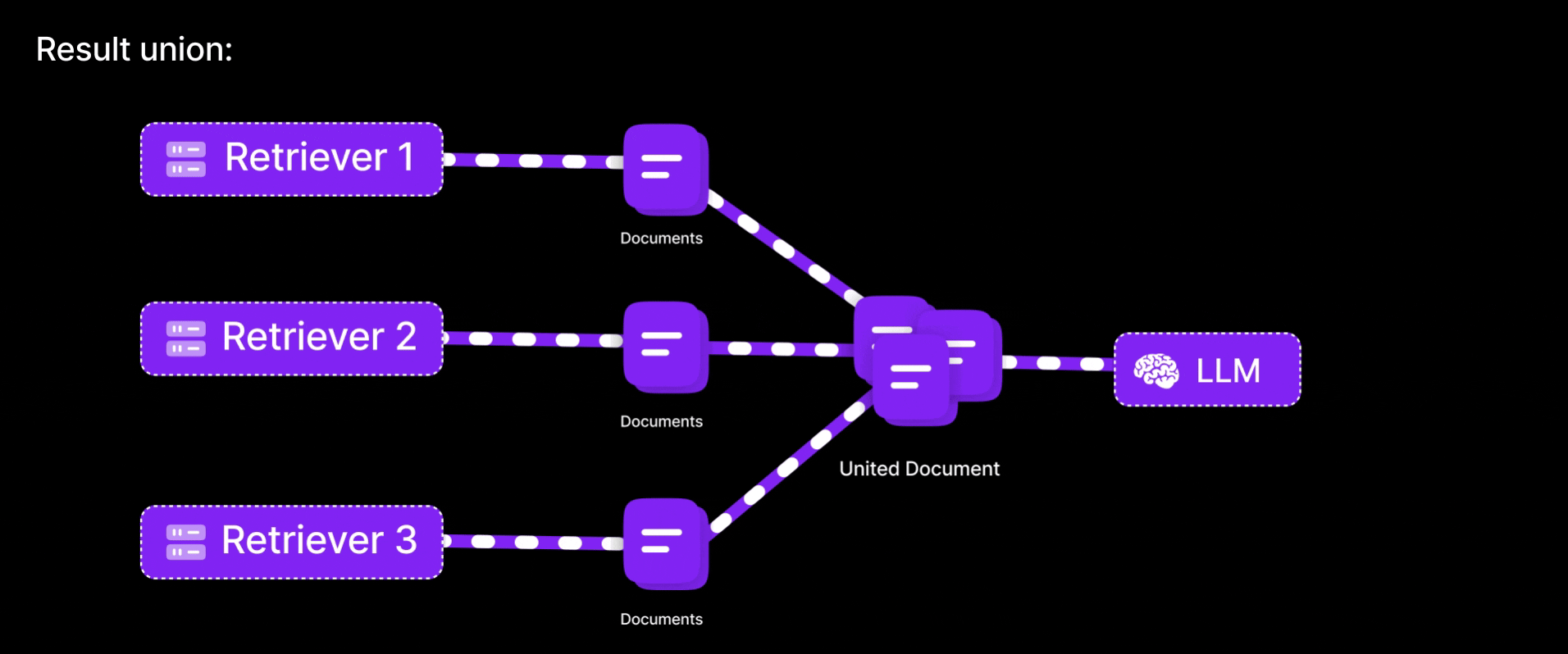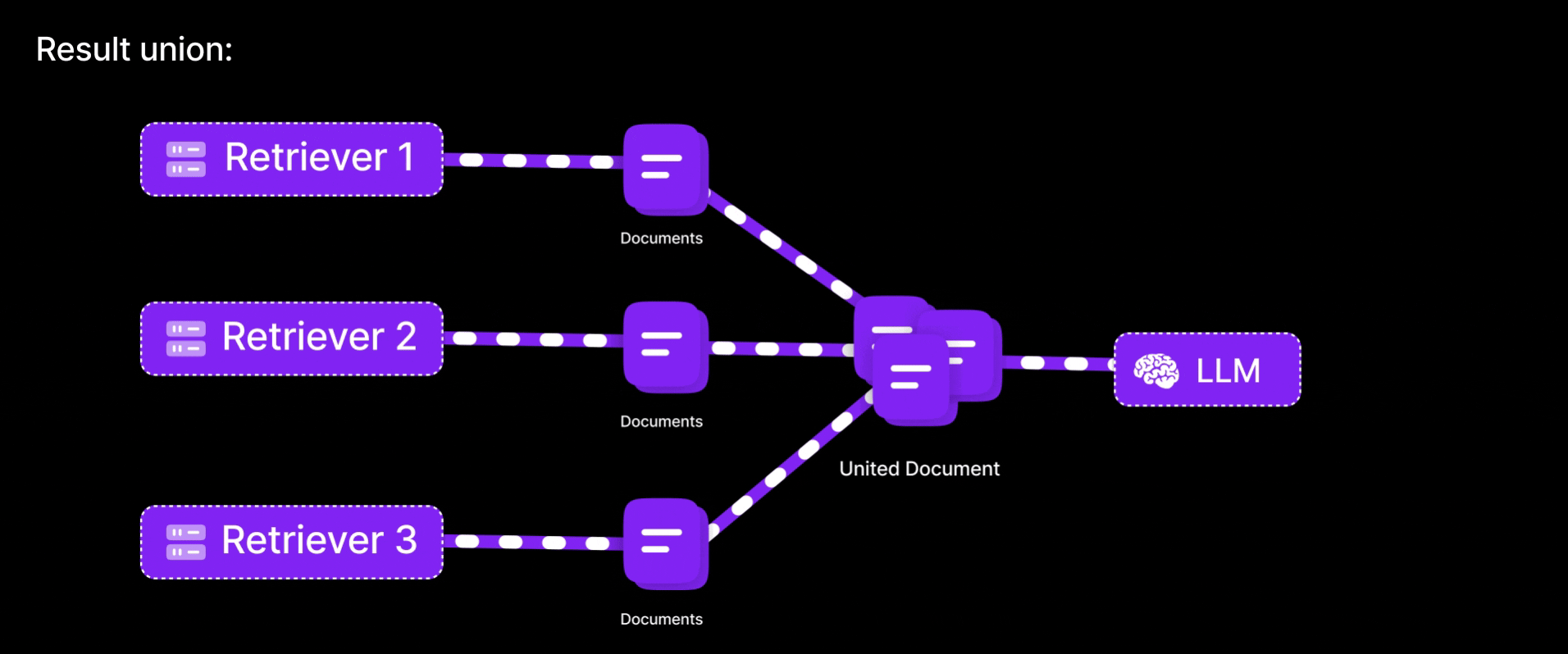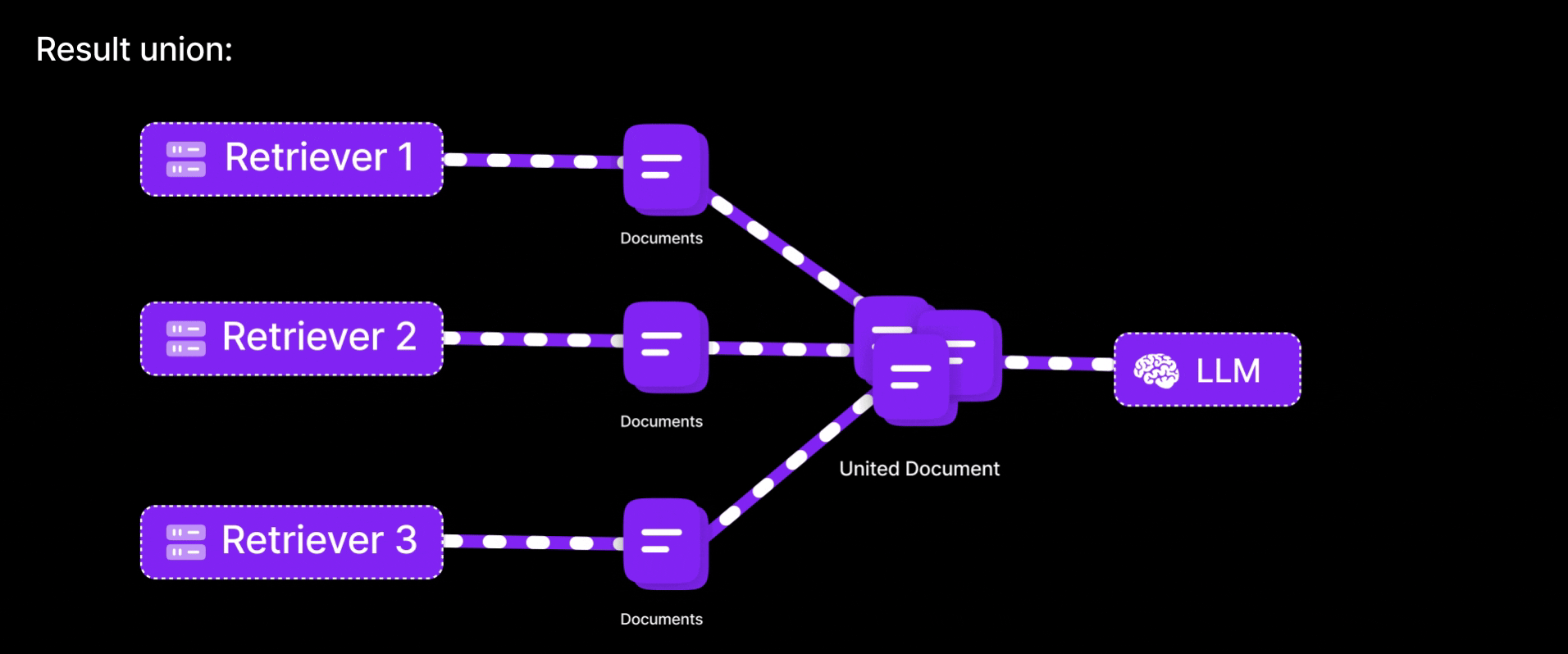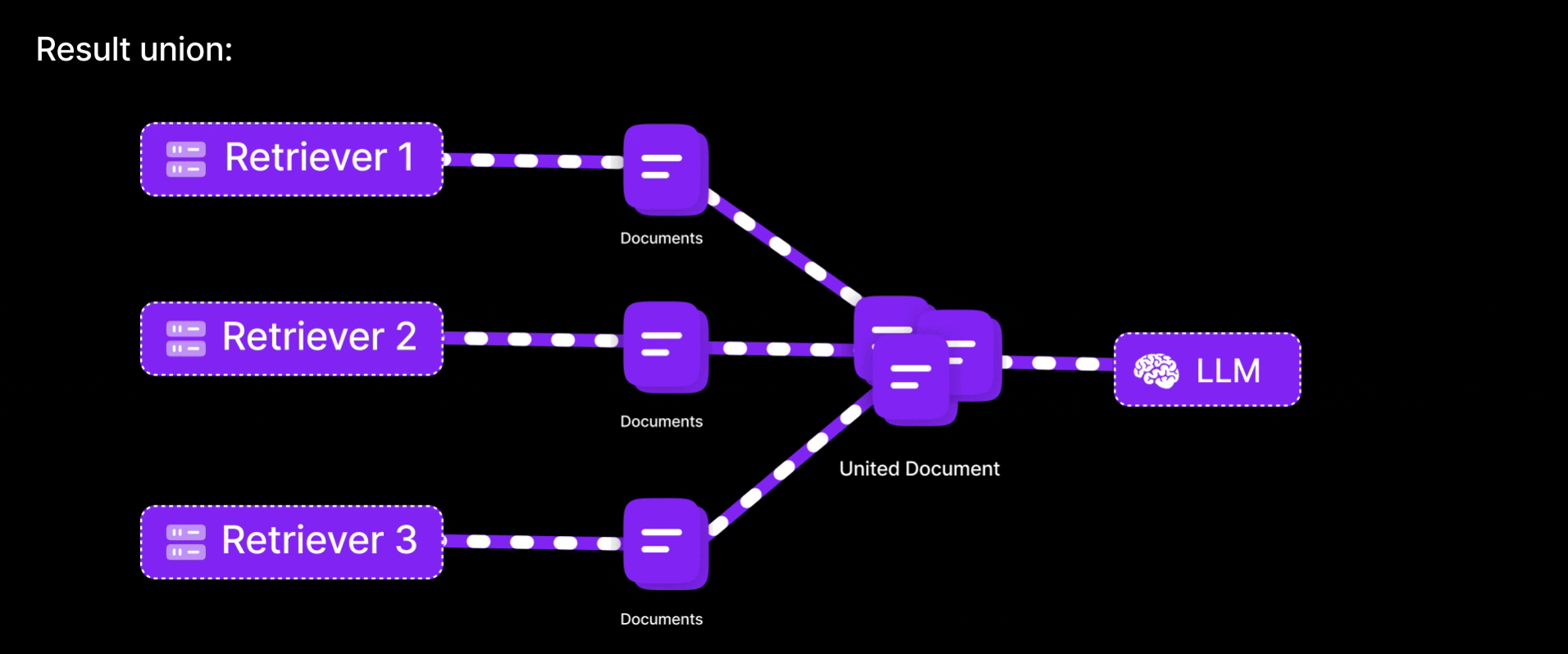
Unite the documents from all queries (deduplicating any overlaps) to form a richer context pool.
By generating multiple variations of the same question, this method reduces the chance of missing important information due to limitations in a single query embedding. It increases the likelihood of retrieving relevant documents by approaching the question from different angles. Similar to consulting multiple bank representatives to understand an issue, if one explanation falls short, others may provide additional clarity. The result is improved recall, as the system captures a broader and more accurate set of information than it would with a single query.
Implementation: Multi-Query Retrieval in LangChain (with Qdrant)
Let’s translate this into code. We’ll use LangChain’s built-in support for multi-query retrieval and a Qdrant vector database as our document store. Imagine we have a knowledge base of bank FAQs and troubleshooting guides. We want to answer: “Why did my bank transfer fail?” using an LLM, but we’ll employ parallel queries to cover all bases (insufficient funds, invalid details, exceeding limits, etc.).
Step 1: Set Up the Vector Store with Embedded Documents
We begin by creating a set of example documents (e.g., bank FAQs and guides) and indexing them in Qdrant using an embedding model.
from langchain.vectorstores import Qdrant
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.schema import Document
# Example documents simulating a bank knowledge base
docs = [
Document(page_content="If a transfer fails due to insufficient funds, ...", metadata={"source": "FAQ"}),
Document(page_content="Transfers may be declined if daily limits are exceeded or account details are invalid, ...", metadata={"source": "Guide"}),
Document(page_content="Error codes for failed bank transfers: 101 Insufficient Funds, 102 Account Not Found, ...", metadata={"source": "TechSupport"})
# Additional documents can be added here
]
# Initialize OpenAI embeddings
embedding_model = OpenAIEmbeddings()
# Connect to Qdrant (ensure it is running at localhost:6333)
vectordb = Qdrant.from_documents(
docs,
embedding_model,
url="http://localhost:6333",
collection_name="bank_knowledge"
)
What’s happening:
We load documents into memory, embed them using OpenAI's embedding model, and store them in a Qdrant collection for future retrieval.
Step 2: Configure the MultiQueryRetriever with an LLM
We now use a language model to generate multiple versions of the user's query to increase recall.
from langchain.chat_models import ChatOpenAI
from langchain.retrievers import MultiQueryRetriever
# Use a deterministic LLM for consistent outputs
llm = ChatOpenAI(temperature=0)
# Wrap the base retriever with MultiQueryRetriever
multi_retriever = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(),
llm=llm
)
What’s happening:
We instantiate a ChatOpenAI model to generate multiple rephrasings of the input question. These variations are passed to the retriever to pull a wider range of relevant documents.
Step 3: Retrieve Documents with the Multi-Query Approach
Now, let’s use the retriever to fetch documents related to the user’s query.
user_question = "Why did my bank transfer fail?"
docs_found = multi_retriever.get_relevant_documents(user_question)
print(f"Retrieved {len(docs_found)} documents with Multi-Query RAG.")
for i, doc in enumerate(docs_found, 1):
snippet = doc.page_content[:60].strip()
print(f"Doc {i}: {snippet}...")
What’s happening:
The get_relevant_documents method internally prompts the LLM to generate multiple versions of the input query. Each query is used to perform a similarity search on the Qdrant vector store. The results are combined and deduplicated before being returned.
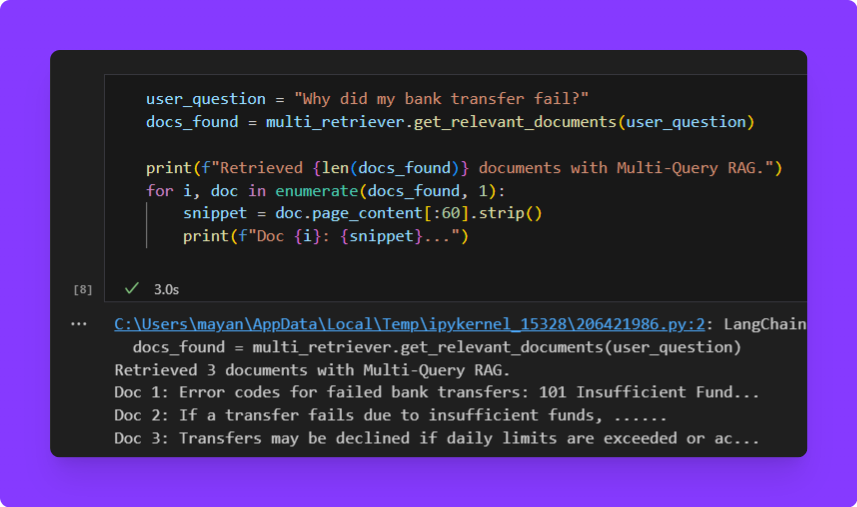
By broadening the search through multiple query interpretations, the system captures a wider context, increasing the chances of retrieving all necessary details for a comprehensive answer.
Developer’s Note
Multi-Query Retrieval introduces additional overhead — more calls to the LLM and more vector searches. However, these can often be run in parallel, and the improvement in retrieval quality generally outweighs the performance cost.
You can control the number of query variants generated (via LangChain settings). A higher number of variants improves recall but may introduce noise. It's recommended to tune this parameter based on your specific domain and requirements.
This approach is especially useful in sensitive domains such as finance, healthcare, or education where a question might require context from multiple perspectives. By employing Multi-Query Retrieval with Qdrant and LangChain, developers can build more robust and intelligent retrieval-augmented generation (RAG) systems.
Reciprocal Rank Fusion (RRF)
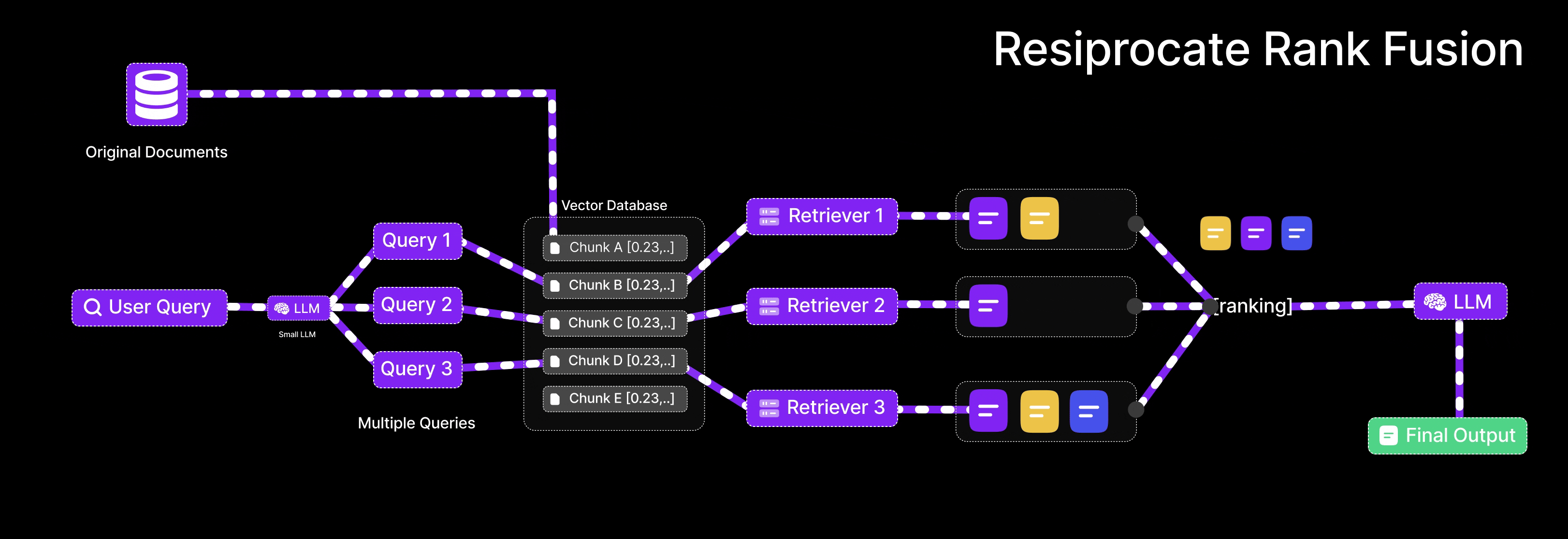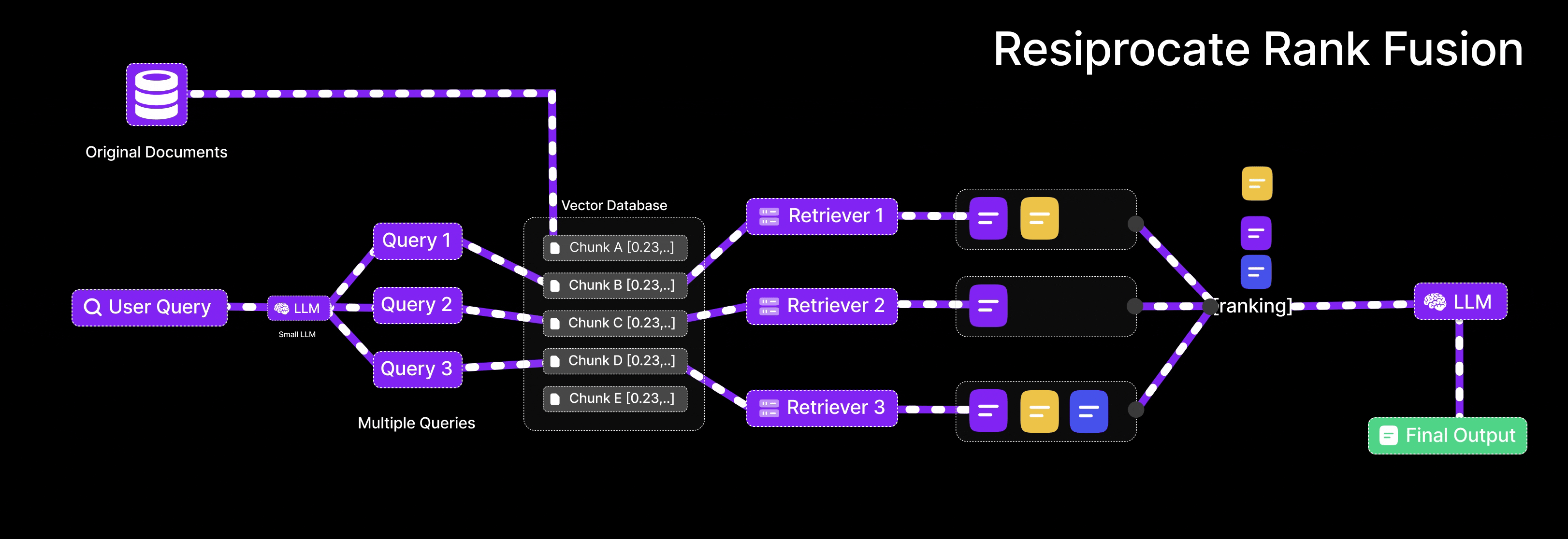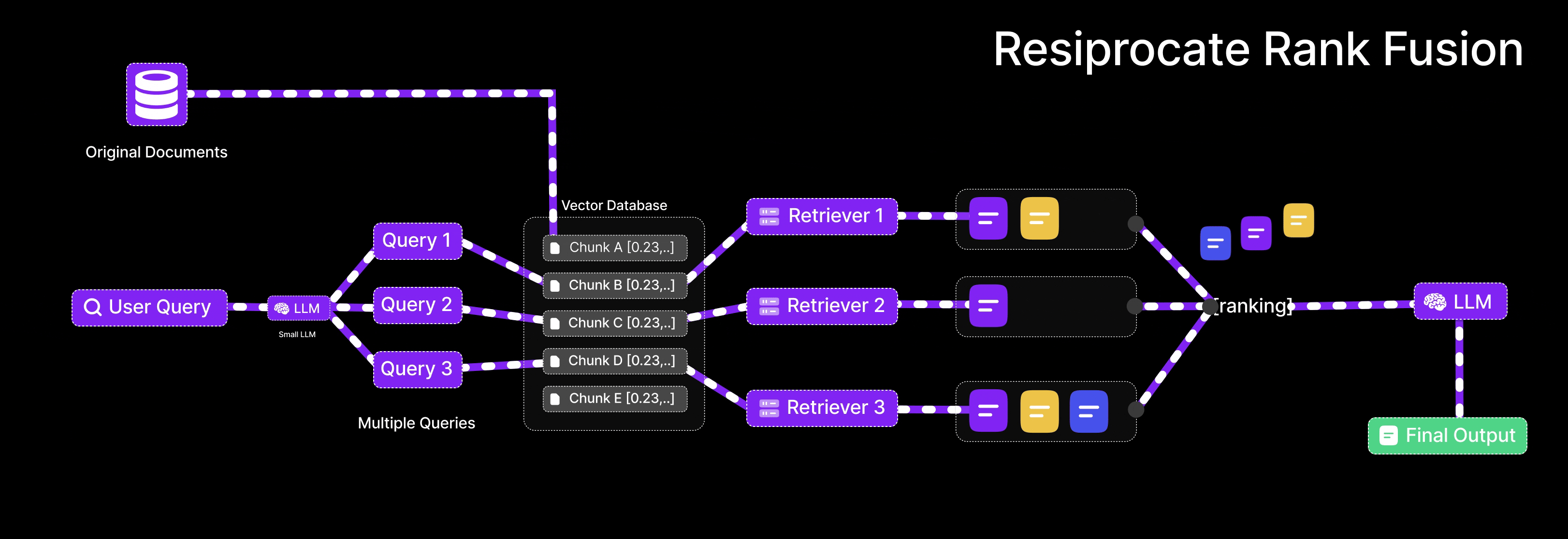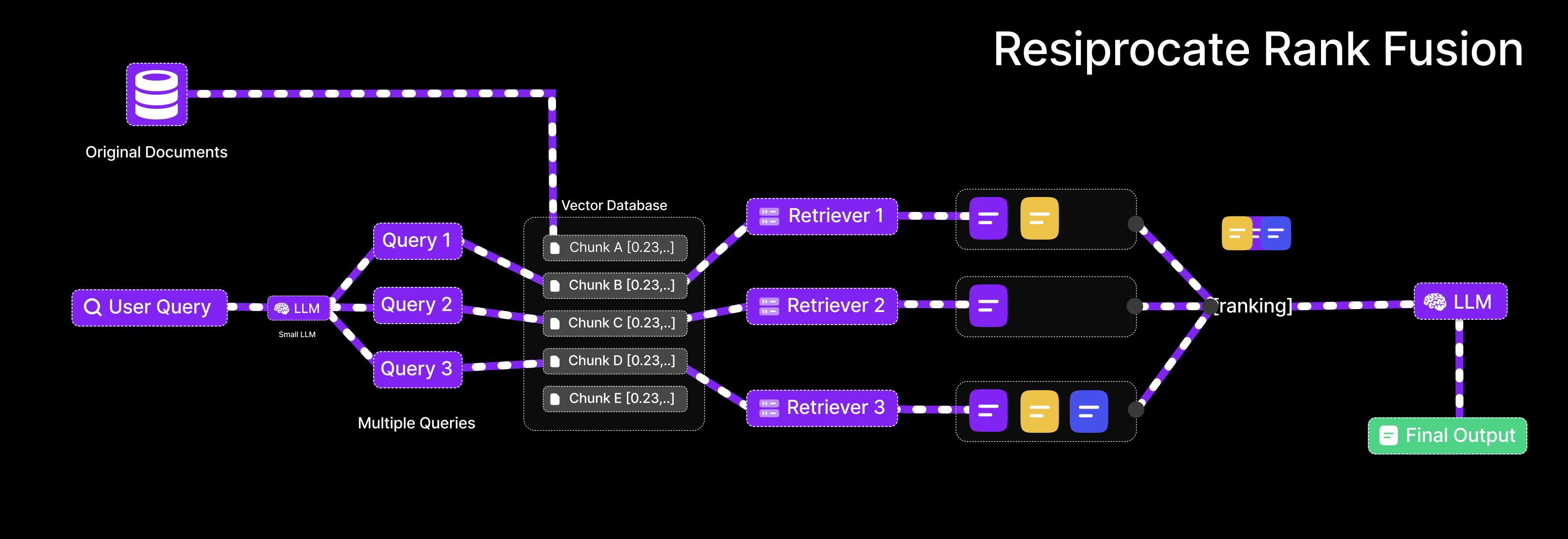
Reciprocal Rank Fusion (RRF) is an algorithm used to merge multiple ranked lists into a single, consolidated ranking. It is useful in RAG when results are retrieved from different queries or retrieval strategies
What’s the Problem that RRF is solving ?
When using multiple retrieval methods (e.g., different variations of the user’s query), each one returns a list of documents ranked by relevance. These lists may overlap partially, with some documents appearing in multiple lists and others appearing only once. The goal of RRF is to merge these lists in a way that prioritizes documents that are consistently ranked highly across multiple sources.
RRF Scoring Mechanism
-
Input:
Multiple ranked lists of documents. For example:
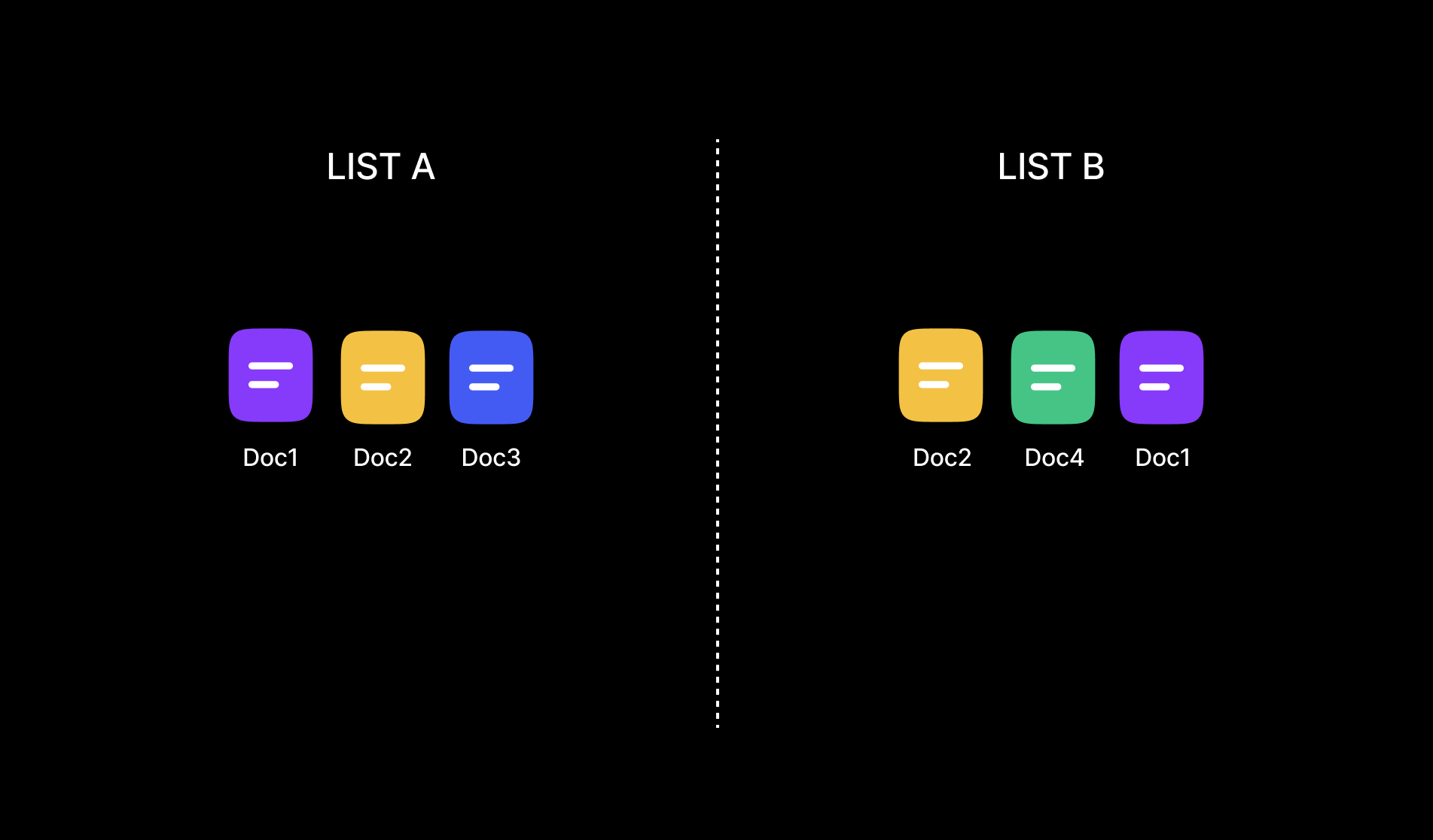
- List A (from Query A): [Doc1, Doc2, Doc3, ...]
- List B (from Query B): [Doc2, Doc4, Doc1, ...]
Scoring Formula:
For each document in each list, assign a score using the formula:
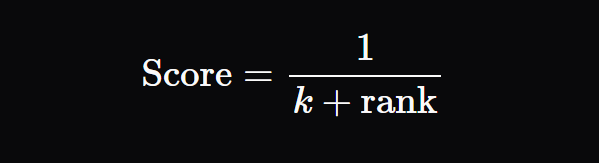
Where:
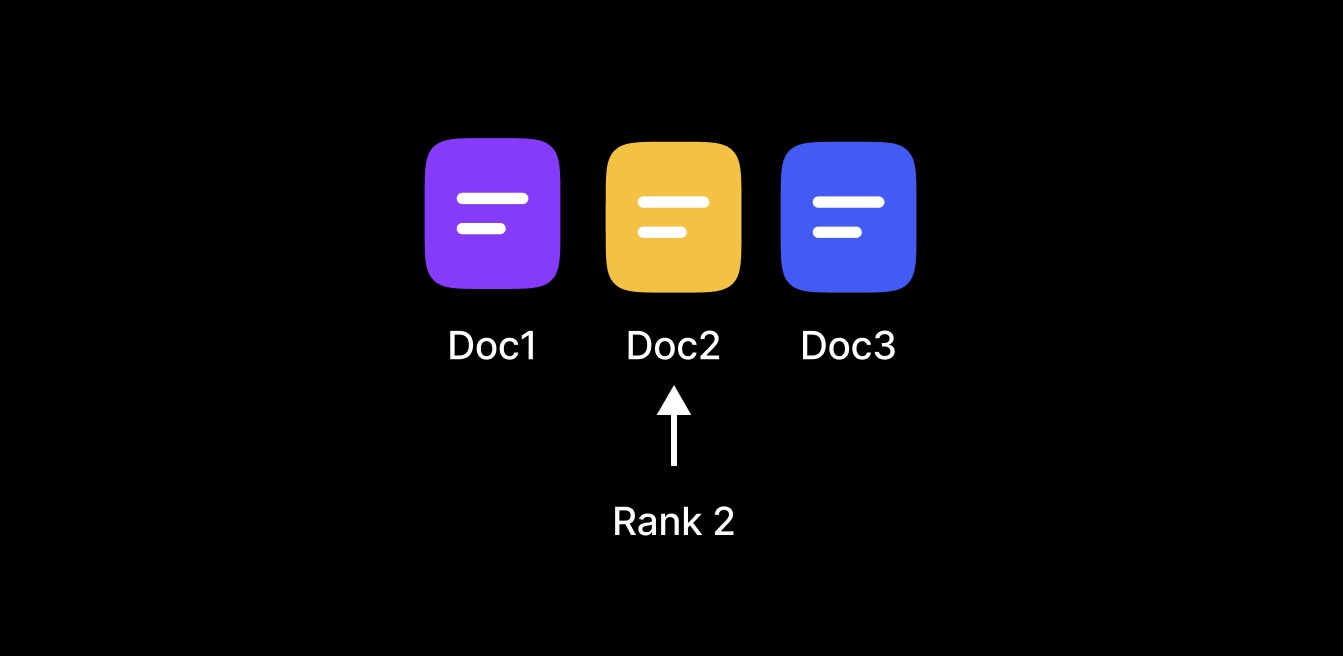
-
rankis the document’s position in the list (1-based indexing), -
kis a small constant (commonly 60) to influence of low-ranked documents.
-
Fusion:
If a document appears in multiple lists, its scores from each list are summed.
-
Final Ranking:
Sort all documents by their total score in descending order. Documents that appear in multiple lists with good ranks receive higher final scores and are promoted to the top.
Example
Let’s say you have 3 ranked lists like this:
| List A | List B | List C |
|---|---|---|
| Doc1 | Doc3 | Doc2 |
| Doc2 | Doc4 | Doc5 |
| Doc3 | Doc1 | Doc3 |
Now let’s assign scores using the RRF formula
as we know that the formula is
rankis the position in the list (1 for top, 2 for second, etc.)kis a small constant (often set to 60). To keep it simple, let’s assume k=0 just for understanding.
Now calculate scores for each document per list:
| List A | List B | List C |
|---|---|---|
| Doc1 1/1 = 1.00 | Doc3 1/1 = 1.00 | Doc2 1/1 = 1.00 |
| Doc2 1/2 = 0.50 | Doc4 1/2 = 0.50 | Doc5 1/2 = 0.50 |
| Doc3 1/3 ≈ 0.33 | Doc1 1/3 ≈ 0.33 | Doc3 1/3 ≈ 0.3 |
Next step: Combine Scores Across All Lists
For each document, calculate its score in every list using the RRF formula, then add those scores together to get the final combined score.
| Document | List A | List B | List C | Total Score |
|---|---|---|---|---|
| Doc1 | 1.00 | 0.33 | – | 1.33 |
| Doc2 | 0.50 | – | 1.00 | 1.50 |
| Doc3 | 0.33 | 1.00 | 0.33 | 1.66 |
| Doc4 | – | 0.50 | – | 0.50 |
| Doc5 | – | – | 0.50 | 0.50 |
Last Step: Final ranking
Sort documents by total score (highest first):

- Doc3 – 1.66
- Doc2 – 1.50
- Doc1 – 1.33
- Doc4 – 0.50
- Doc5 – 0.50
Doc3 appeared in all three lists and held relatively high positions, resulting in the highest overall score. Doc2 was present in two lists and ranked high in one of them, giving it a strong combined score. Doc1 ranked first in one list and lower in another, making it still valuable but slightly behind the others. In contrast, Doc4 and Doc5 appeared only once and thus received the lowest scores in the final ranking.
In Summary we can say
- RRF rewards documents that appear in multiple ranked lists.
- It gives higher scores to top-ranked documents in each list.
- Documents that are consistently relevant across different searches rise to the top.
Implementation: Combining Results with RRF
Let’s implement a simple Reciprocal Rank Fusion in code. We’ll reuse the idea from the previous section: the user’s question “Why did my bank transfer fail?” could be answered by multiple query approaches. For instance, perhaps we want to combine results from two different query formulations (or from two different vector models). We’ll simulate that and then fuse the results. We’ll again use Qdrant for searching, but do it manually for illustration:
Step 1: Define Query Variants
Assume we already have a Qdrant vector store and an embedding model from earlier steps. We define two alternative query formulations:
queries = [
"Why would a bank transfer be declined? Insufficient funds scenario.",
"Reasons a bank transfer might fail due to account issues or limits."
]
Explanation:
These variations represent different phrasings of the same core user intent. They may yield different sets of relevant documents, which we aim to combine.
Step 2: Perform Similarity Search for Each Query
We run a similarity search using Qdrant for each query and collect the top-k results along with their scores.
results_lists = [] # List to hold results from each query
for q in queries:
res = vectordb.similarity_search_with_score(q, k=5) # returns (Document, similarity_score)
results_lists.append(res)
Explanation:
We store the results for each query in results_lists. Each list contains tuples of documents and their similarity scores. For RRF, we use only the rank position, not the score.
Step 3: Apply Reciprocal Rank Fusion (RRF)
We calculate a fused score for each document using the formula:
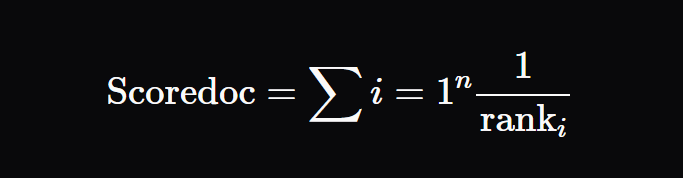
from collections import defaultdict
fused_scores = defaultdict(float)
doc_lookup = {} # To map IDs back to Document objects
for res_list in results_lists:
for rank, (doc, _) in enumerate(res_list, start=1):
doc_id = doc.metadata.get("id", doc.page_content) # Use ID or fallback to text
fused_scores[doc_id] += 1.0 / rank
doc_lookup[doc_id] = doc # Save reference to the document
For each list of results, we iterate through the documents and assign a score of 1/rank
If a document appears in multiple lists, its score accumulates, boosting its rank in the final fused list.
Step 4: Rank the Documents Based on Fused Scores
Now we sort the documents in descending order of their accumulated RRF score.
ranked_docs = sorted(fused_scores.items(), key=lambda item: item[1], reverse=True)Documents with higher total RRF scores (i.e., that appear higher and more frequently in multiple result sets) are ranked higher.
Step 5: Display the Final Ranked List
We print out the final top documents after fusion.
# Assume you already built this earlier:
# doc_lookup = {doc_id: Document}
print("Final RRF-ranked documents:")
for doc_id, total_score in ranked_docs[:5]:
doc = doc_lookup[doc_id] # Get the actual Document object
title = doc.page_content.split('.')[0] # use first sentence
print(f"- {title}... (score={total_score:.2f})")
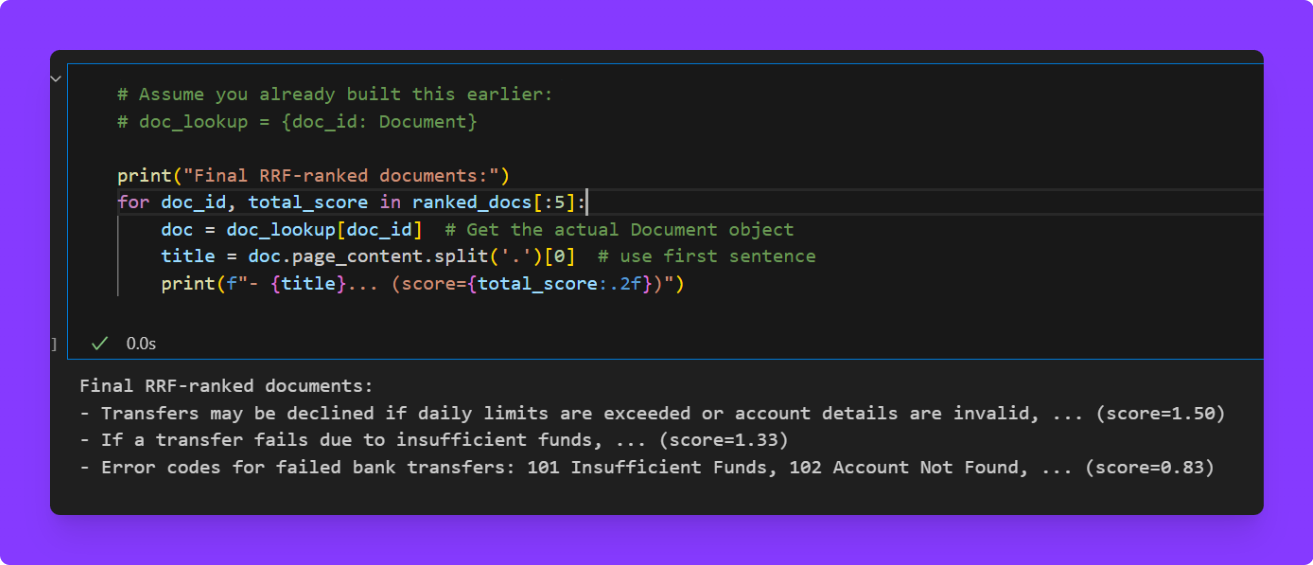
We display the top-ranked documents and their corresponding RRF scores. This helps in quickly verifying the quality and diversity of the results.
You can Check the Code of Both Parallel Query Retrieval & Reciprocal Rank Fusion from here: https://github.com/Mayankpratapsingh022/RAG_Qdrant_DB
Bringing It All Together
Advanced retrieval techniques like Multi-Query RAG and Reciprocal Rank Fusion can transform your LLM application from a one-shot guesser into a savvy information detective. By drawing analogies from simple banking tasks, we saw that: checking an account balance in multiple ways is akin to parallel queries uncovering more data, and merging duplicate bank statements is like fusing ranked results to boost reliable information. These methods inject a real-life rigor into AI retrieval – much as you would double-check important facts in day-to-day tasks, your LLM can double-check context from multiple angles and reconcile it.
By implementing Parallel Query Retrieval and RRF, We as LLM developers and ML engineers can significantly improve answer accuracy and reliability in RAG systems. The techniques are relatively easy to integrate yet powerful in effect – a rare win-win in engineering. So the next time your AI assistant seems to “miss” something, remember the lesson of the failed bank transfer: ask again in a different way, and combine what you learn. Just as you bank on multiple sources to get the full story in life, you can bank on these advanced retrieval strategies to build better, smarter AI solutions.
I'm actively sharing my learnings, projects, and insights around LLMs, Generative AI, and Machine Learning online
If you're building in this space or just curious to understand the core concepts better, let’s connect and grow together through shared learning.
Twitter/X: https://x.com/Mayank_022
Linkedin: https://www.linkedin.com/in/mayankpratapsingh022/
Portfolio: https://www.mayankpratapsingh.in/