[4] The need of Attention Mechanism
Mayank Pratap Singh
@Mayank Pratap Singh
![[4] The need of Attention Mechanism](/_next/image?url=%2Fimages%2Fblog%2FThe-need-of-attention%2F17.gif&w=1920&q=75)
![[1] Understanding the Limitations of Traditional Models and the Rise of Attention](https://raw.githubusercontent.com/Mayankpratapsingh022/blog-site/refs/heads/master/public/images/blog/The-need-of-attention/cover.gif)
Table of Contents
- Introduction
- History – The evolution of sequence modeling
- Why Not Use Traditional Neural Networks? – Limitations of ANNs
- Why RNNs Don’t Work for Long-Range Context – The context bottleneck
- LSTMs: A Step Forward, But Not Far Enough
- What is a Context Window?
- Attention Mechanism – A smarter way to focus on relevant information
- Bahdanau Attention – The first implementation of attention in deep learning
- The Evolution from Bahdanau to Transformers and GPT – Setting the stage for Self-Attention
- Conclusion
Introduction
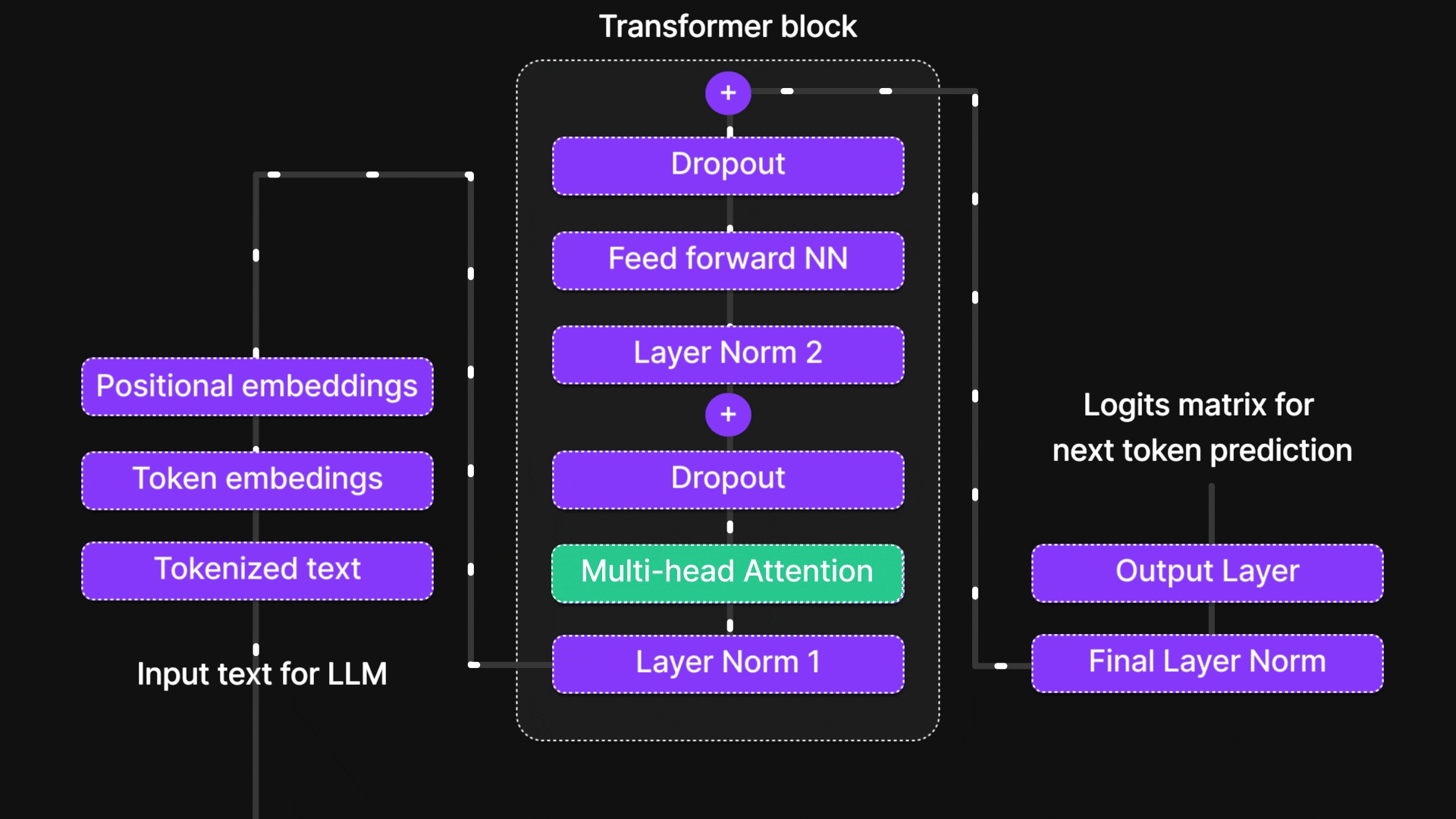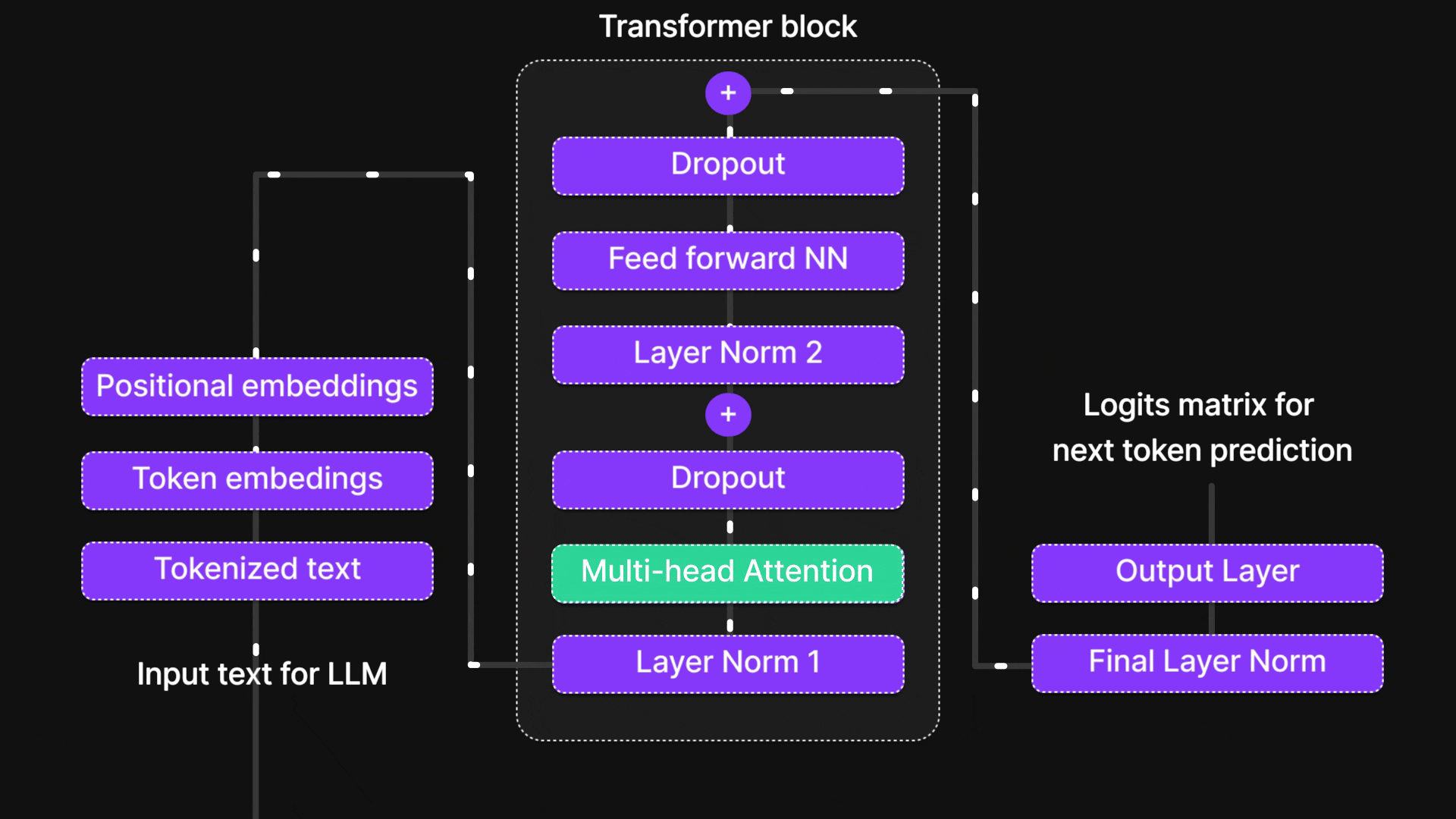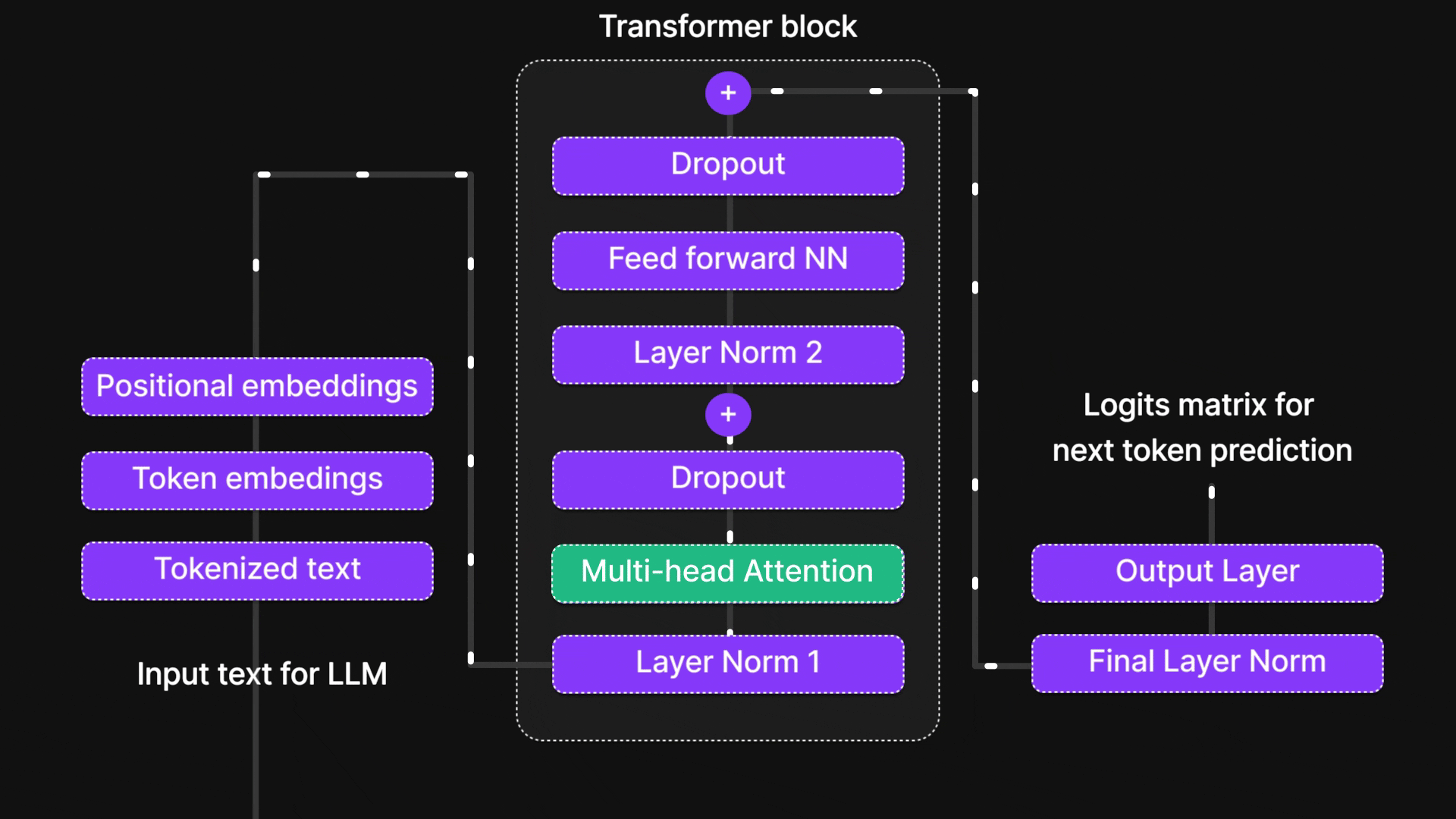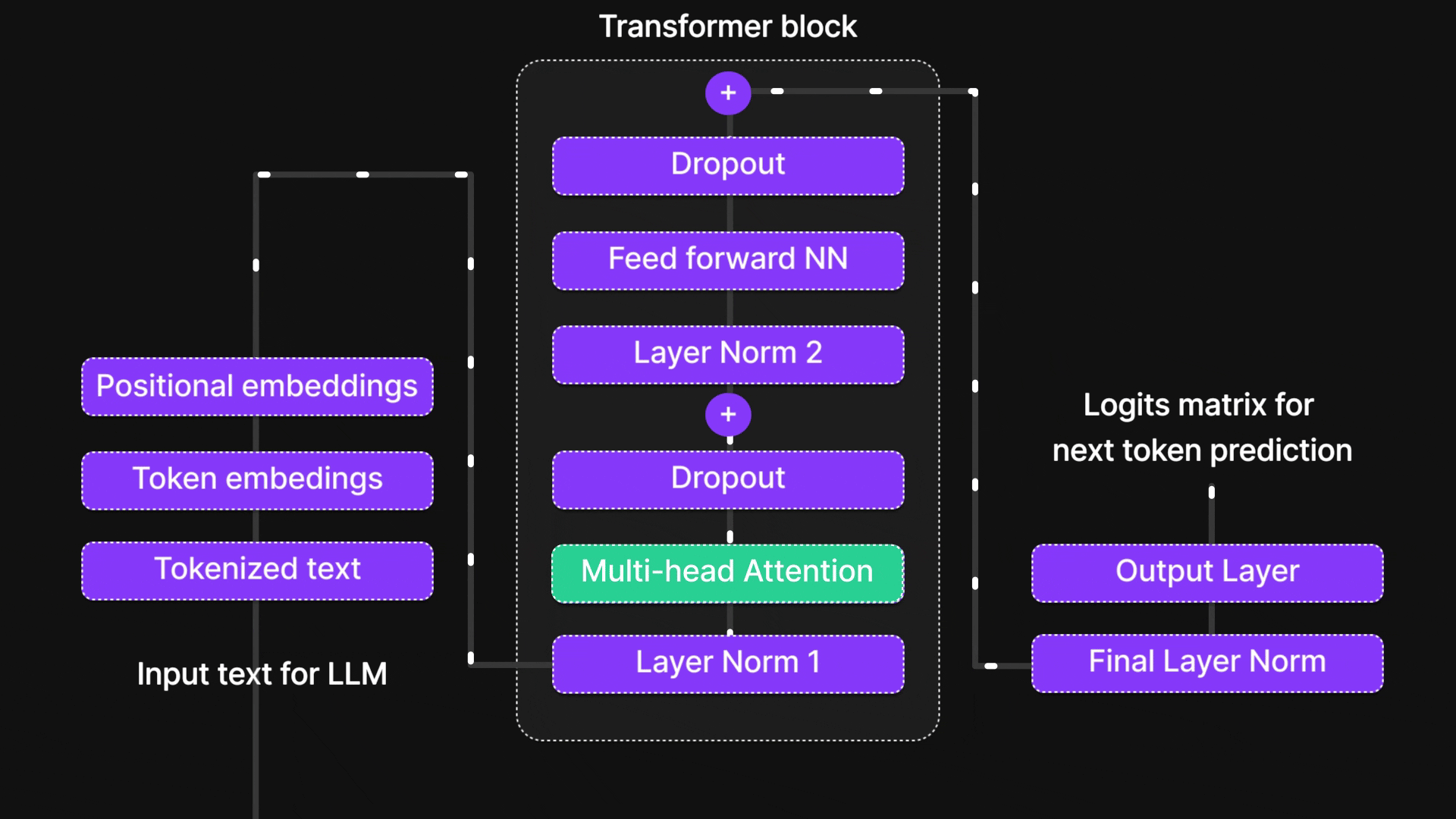 Figure 1: “Attention mechanism” is in this part of the architecture.
Figure 1: “Attention mechanism” is in this part of the architecture.
In this blog, we’re going to peel back the layers and explore that journey—from basic neural networks to Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and finally to the powerful concept of Attention.
You'll see why traditional architectures like ANNs and RNNs hit a wall, especially with long or complex inputs. We'll break down the context bottleneck problem, understand how LSTMs tried to solve it (but didn’t go far enough), and finally uncover how Bahdanau Attention—a combination of Attention and RNNs—reshaped the way machines deal with sequences.
By the end, you'll not only understand the “why” behind the attention mechanism, but you’ll be perfectly set up for the next big leap: Self-Attention and the birth of Transformers—the very foundation of today's most powerful language models.
If you're not familiar with the basics of LLM architecture and how things work under the hood, you can refer to these two blogs for a deeper understanding.
[1] Part-1
A Bird’s-Eye View of LLM Architecture
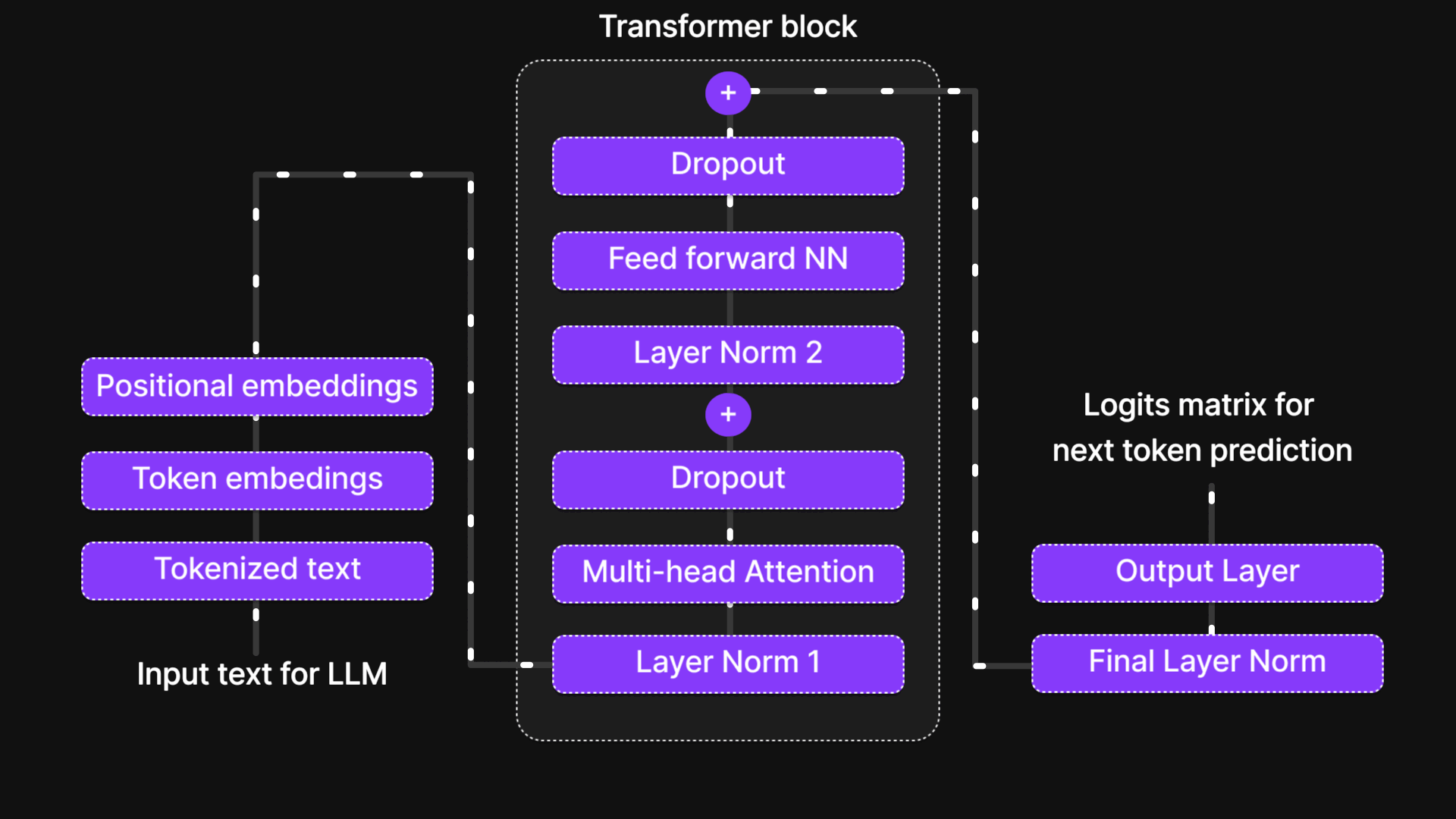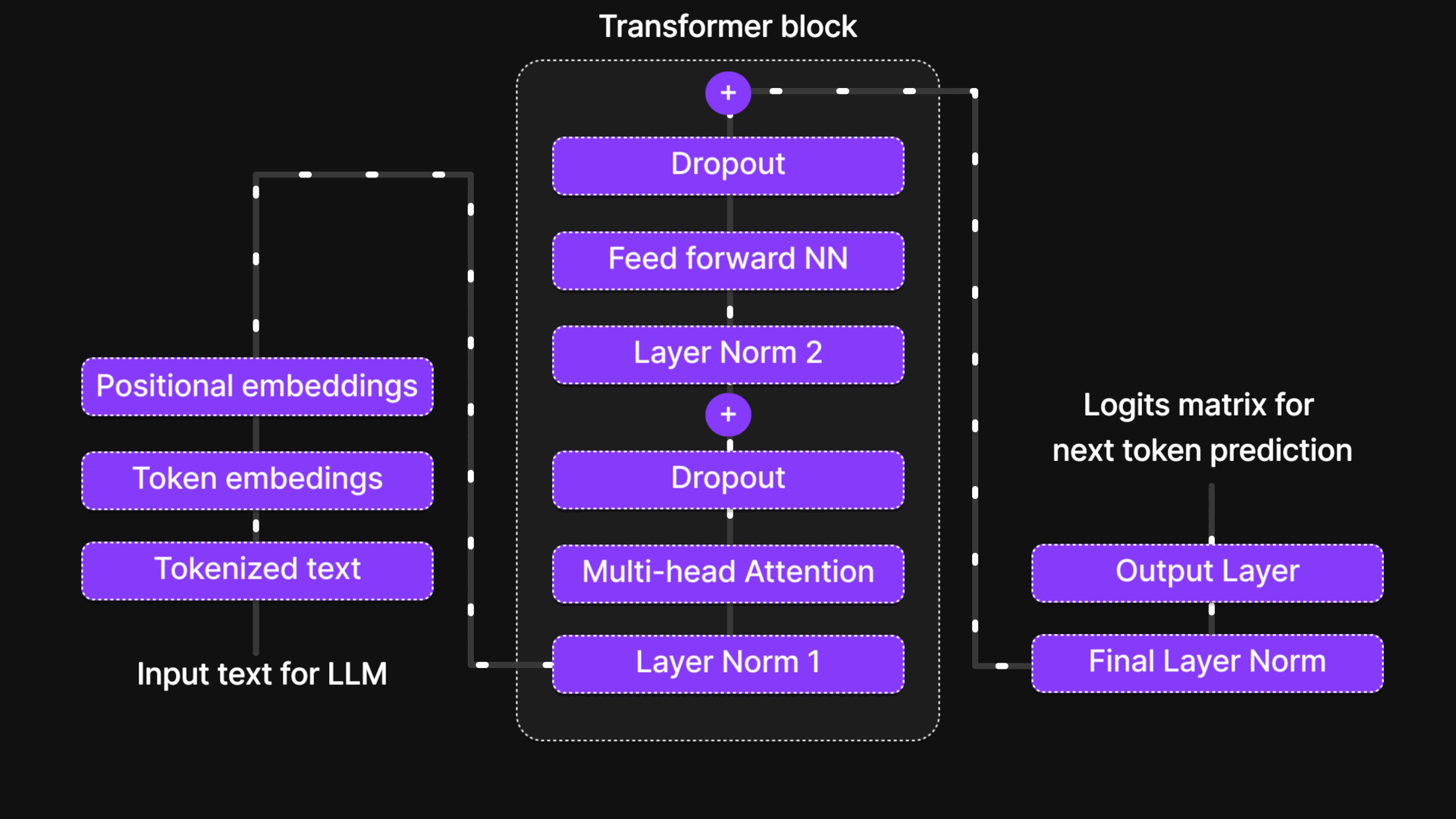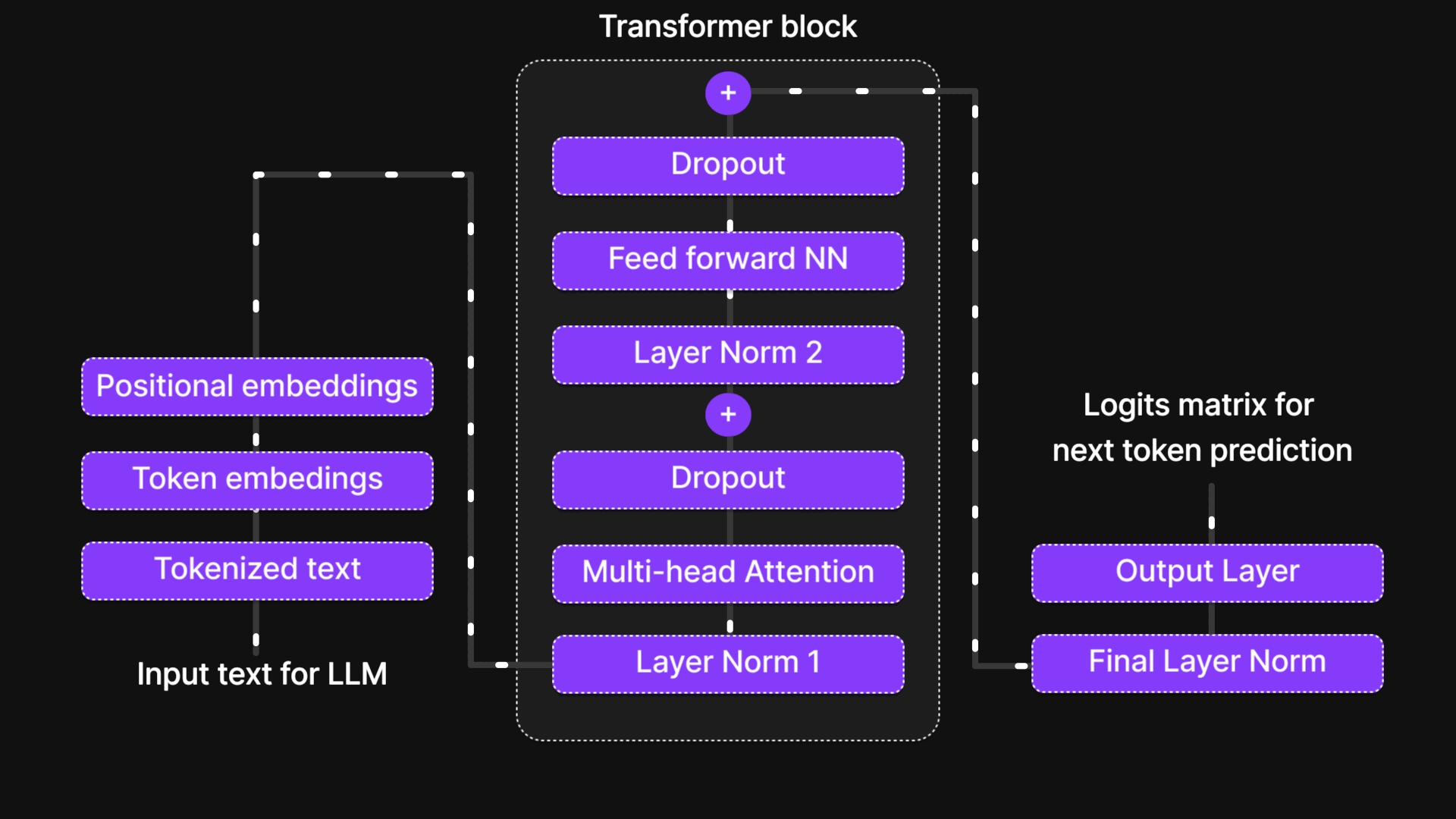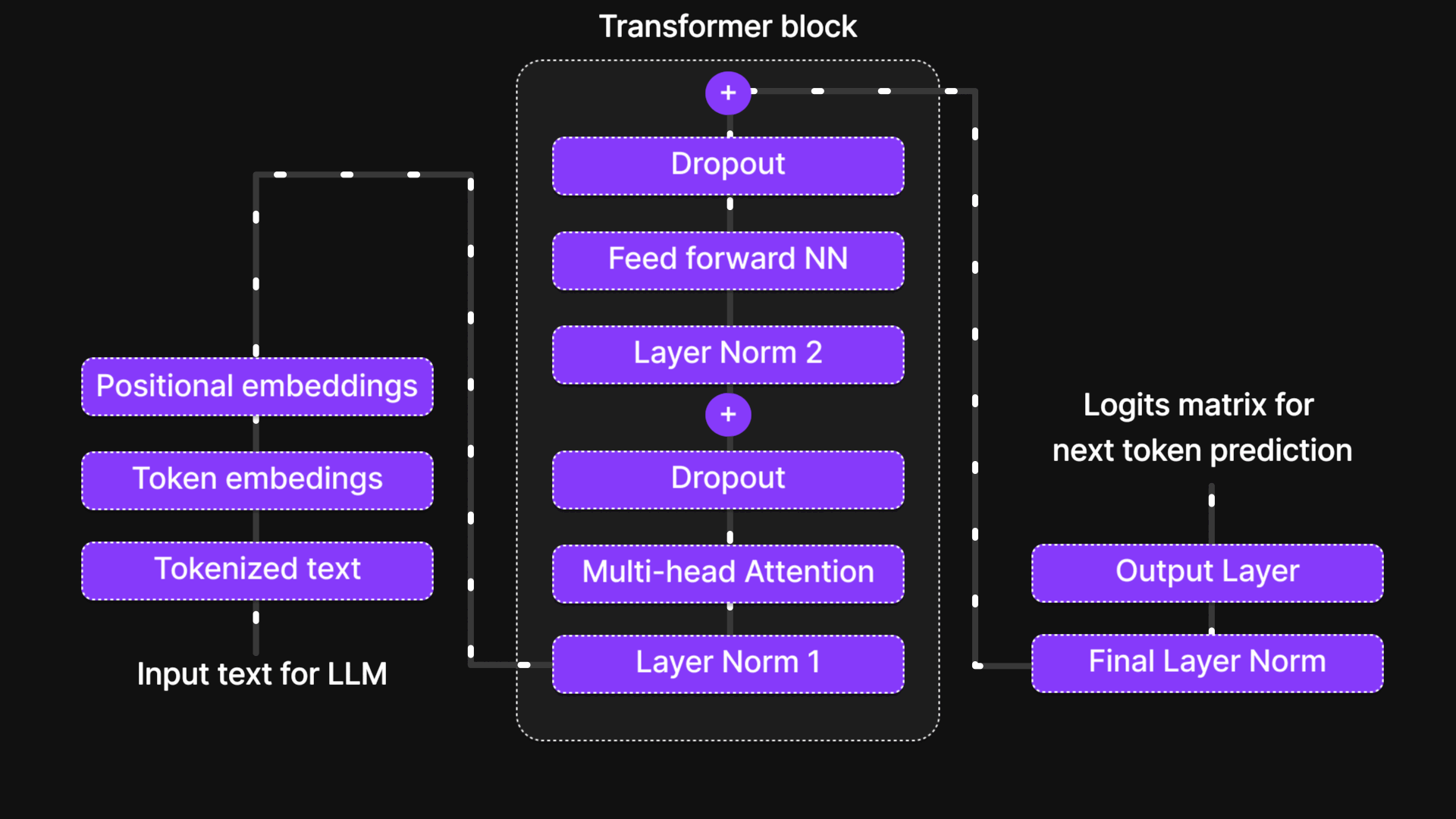
Visit "A Bird’s-Eye View of LLM Architecture" blog
[2] Part-2
Journey of a single token through the LLM Architecture

Visit "Journey of a single token through the LLM Architecture" blog
Let’s dive in and uncover how this all began.
History
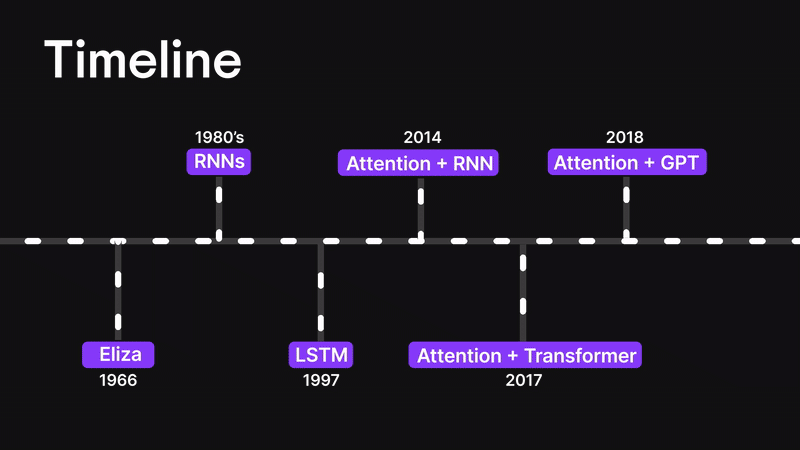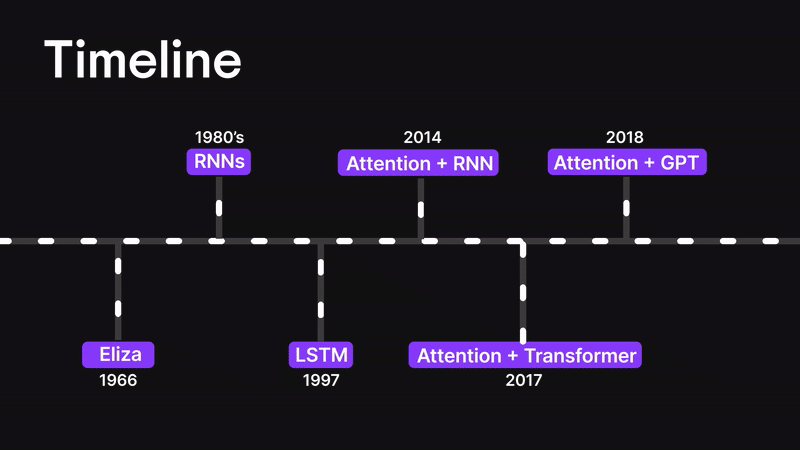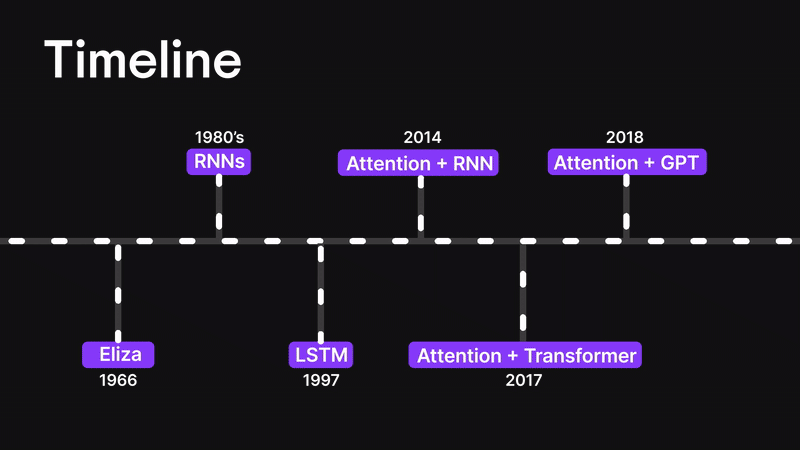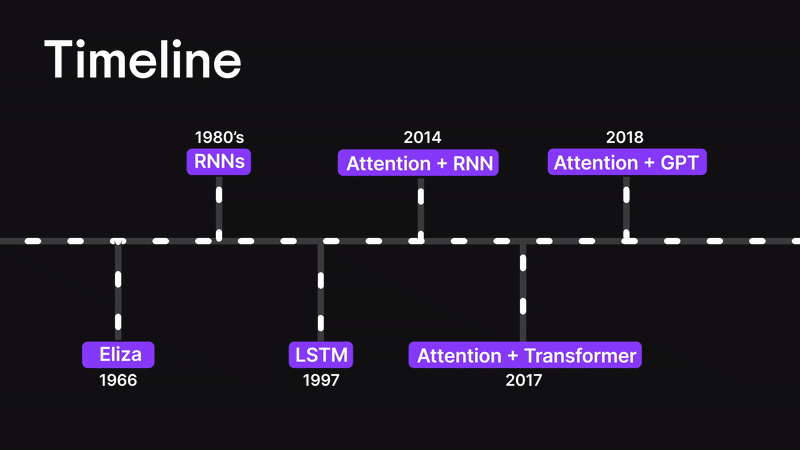 Figure 3: Timeline
Figure 3: Timeline
Before we dive into the attention mechanism, let’s rewind a little and walk through how we got here.
Why not use Traditional Neural Networks?
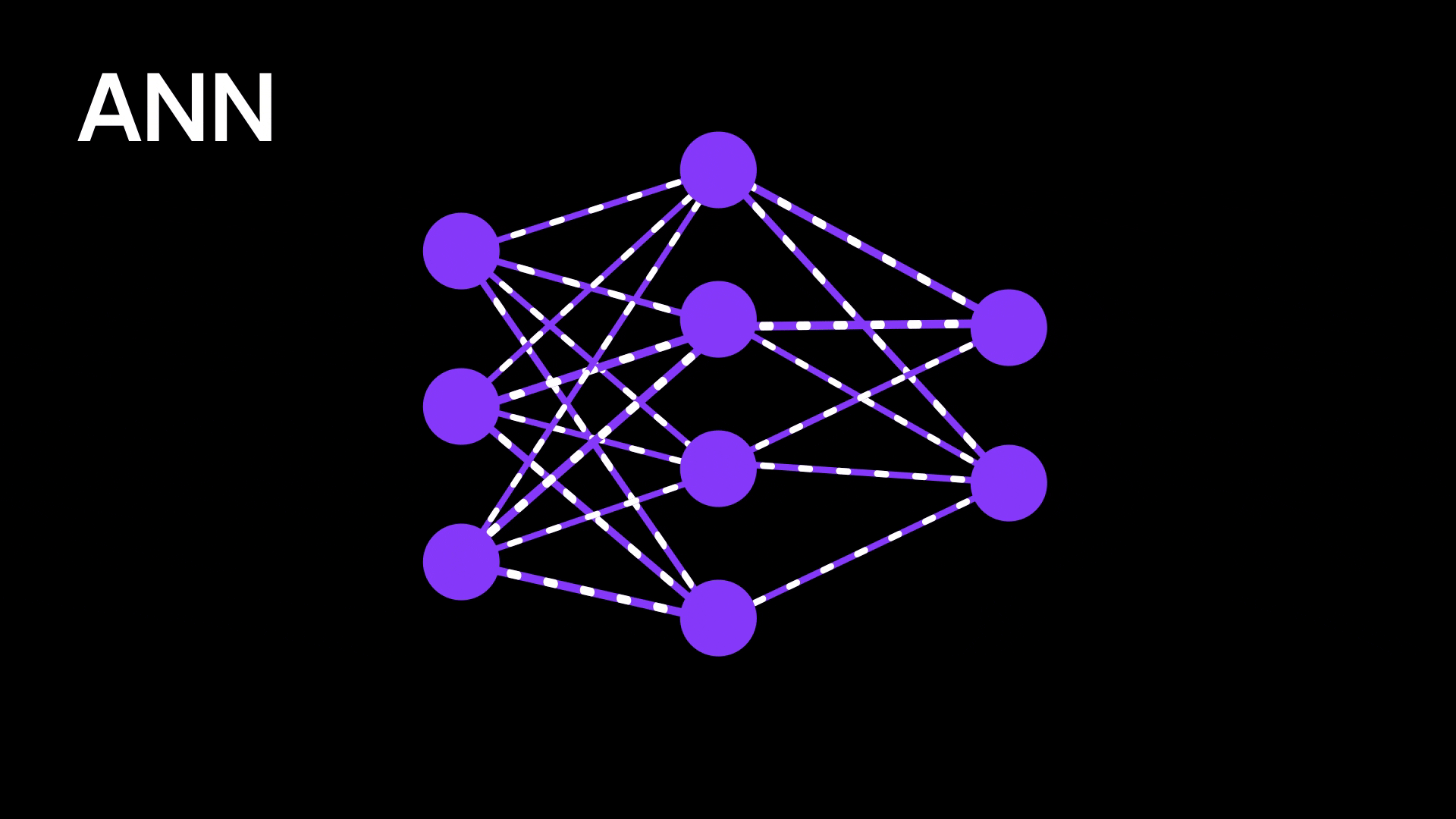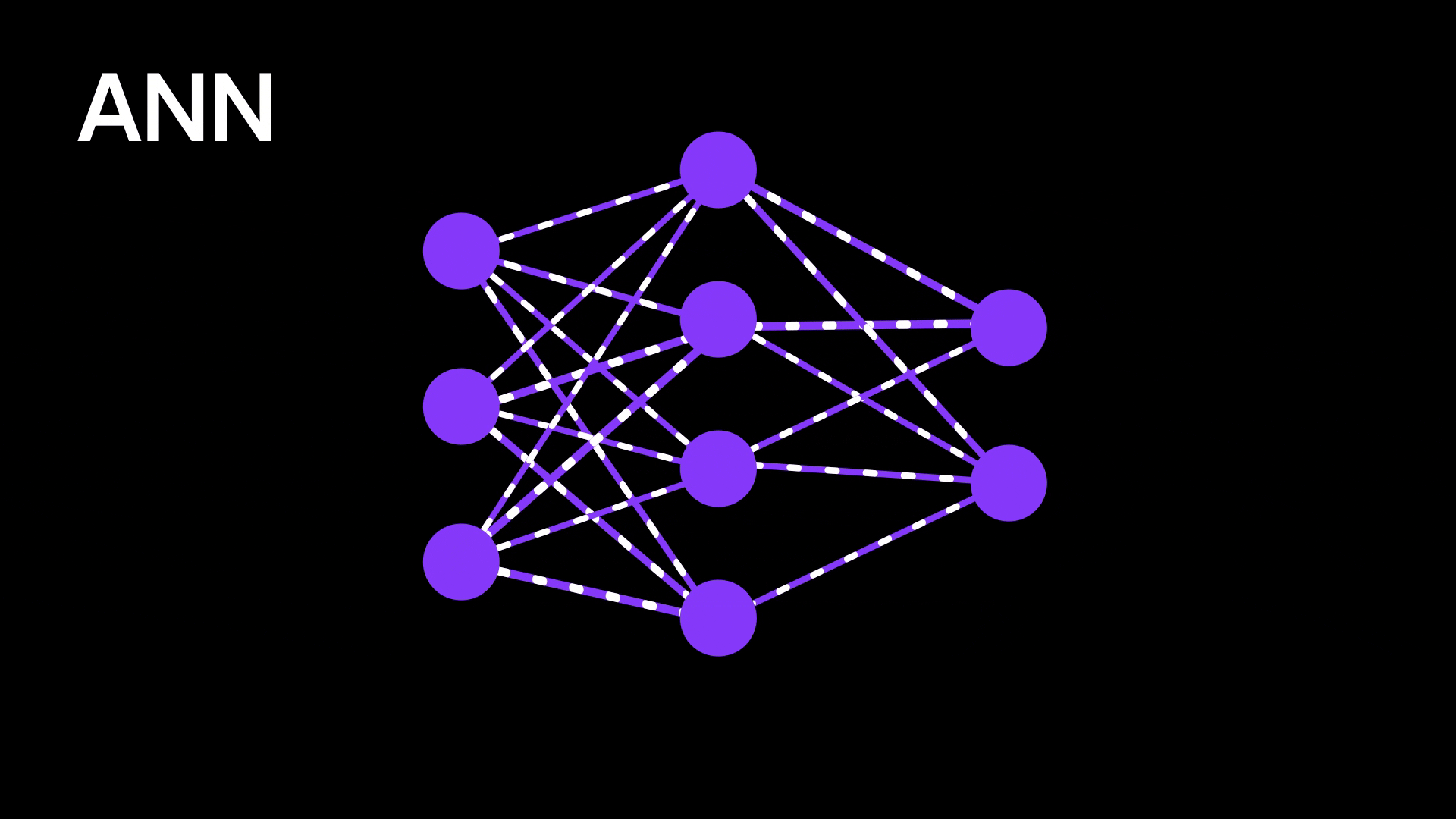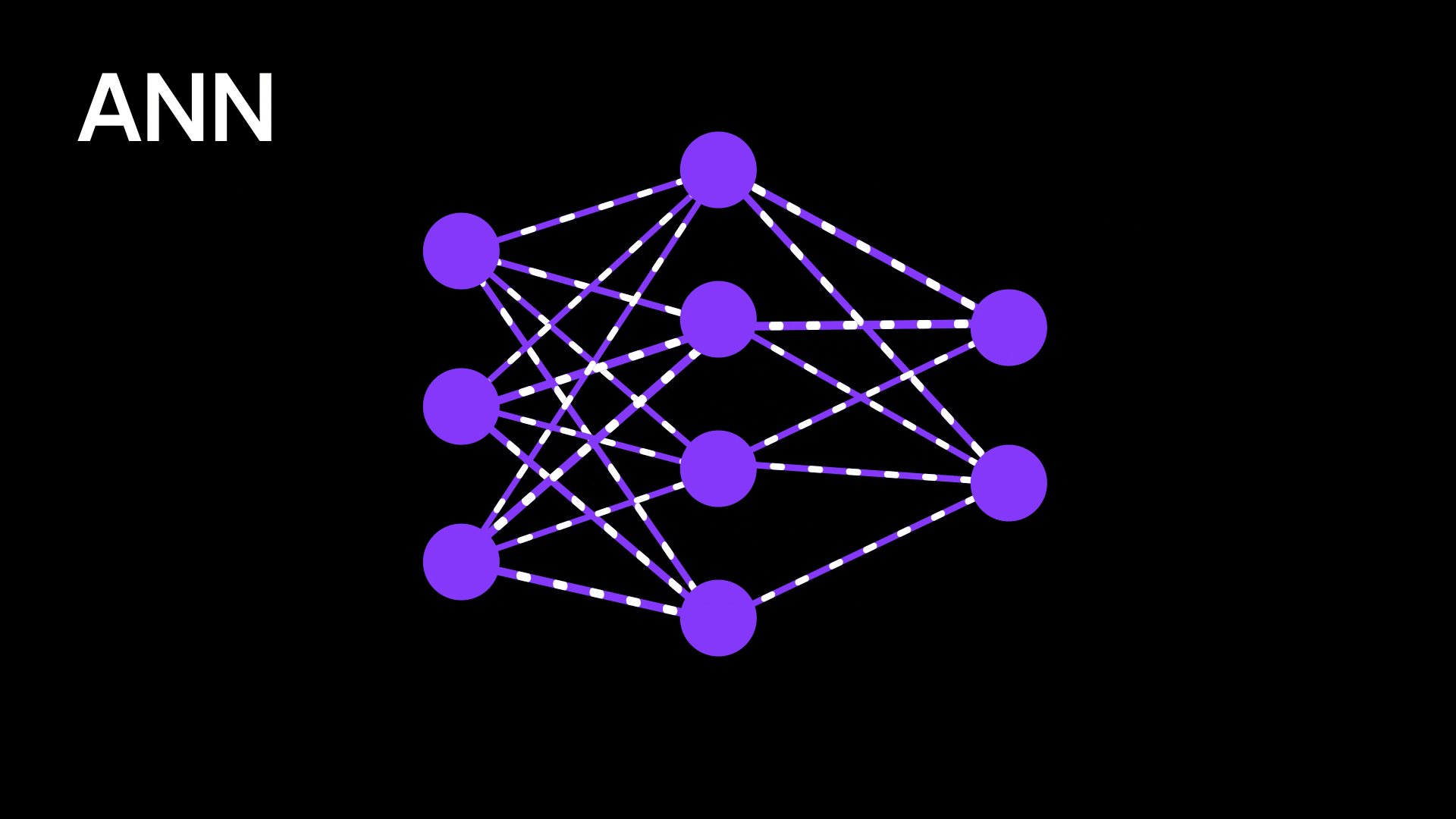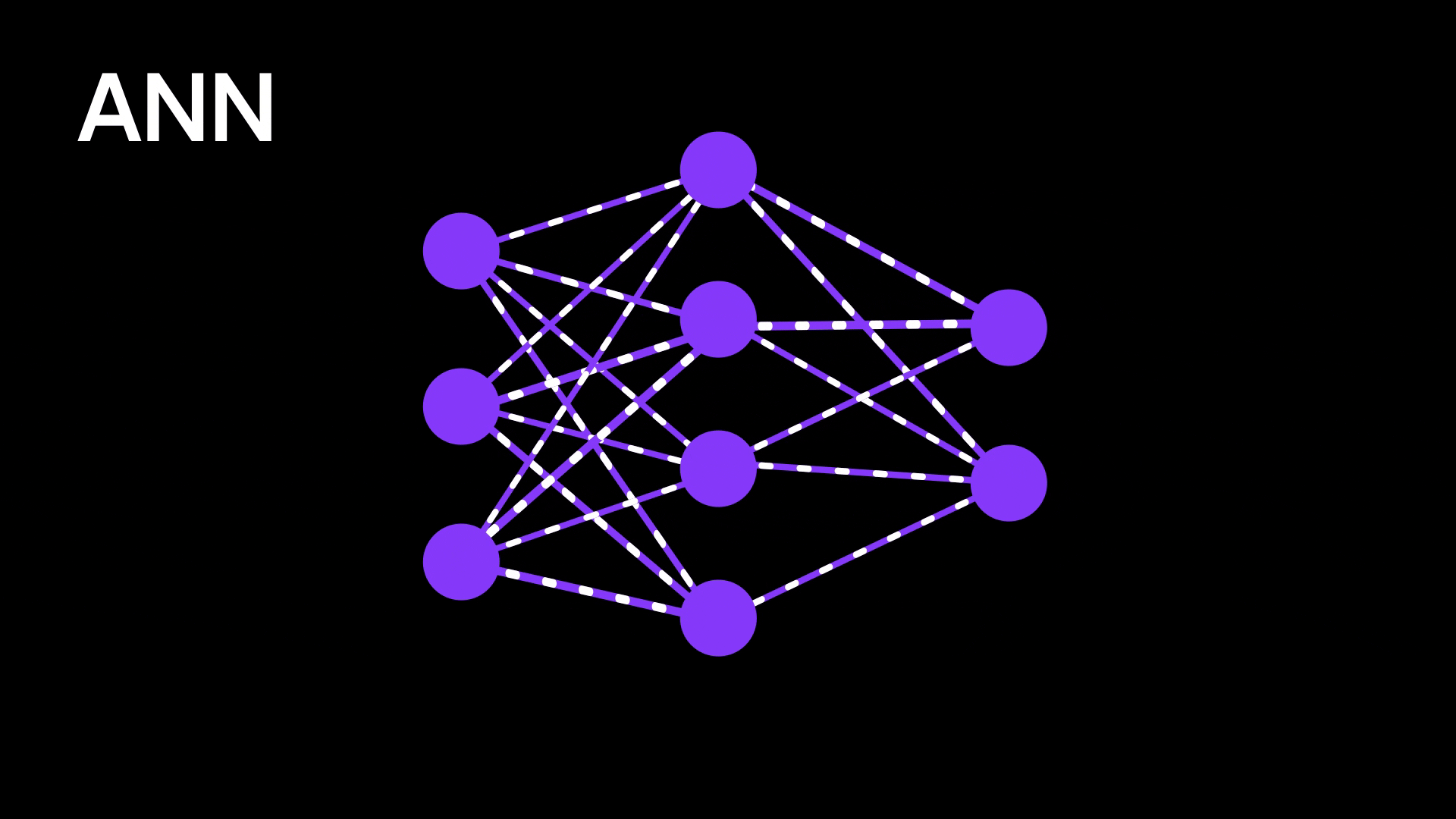 Figure 3: Artificial neural network
Figure 3: Artificial neural network
Traditional neural networks are powerful at recognizing patterns, but they lack any sense of order or sequence. They treat every input as independent, which becomes a problem when dealing with language, audio, or any kind of sequential data. For example, if you’re trying to predict the next word in a sentence, the model needs to understand the context — what came before matters. But regular neural networks have no way to remember previous inputs or capture dependencies across time.
 Figure 4: ANN lack any sense of order or sequence
Figure 4: ANN lack any sense of order or sequence
This is where Recurrent Neural Networks (RNNs) come in. Unlike standard neural nets, RNNs are designed to handle sequences by introducing a simple form of memory, allowing them to retain information from previous steps. They form the foundation of many early breakthroughs in sequence modeling.
Why RNNs don’t work for long range context ?
 Figure 5: The architecture of RNNs
Figure 5: The architecture of RNNs
Recurrent Neural Networks (RNNs) try to understand a sentence by reading one word at a time and passing information forward, like a relay race. The final hidden state (let’s call it a memory vector) is supposed to carry the meaning of the entire sentence. But here’s the problem: everything depends on that one final memory. If the sentence is long or complex, the earlier words can get “forgotten” as the network struggles to compress all the information into a single vector. So when it comes time to translate or generate the output, the decoder is relying on a memory that might be blurry or incomplete. This is exactly why we need a better way—something that lets the model look back at all the words, not just rely on the last one.
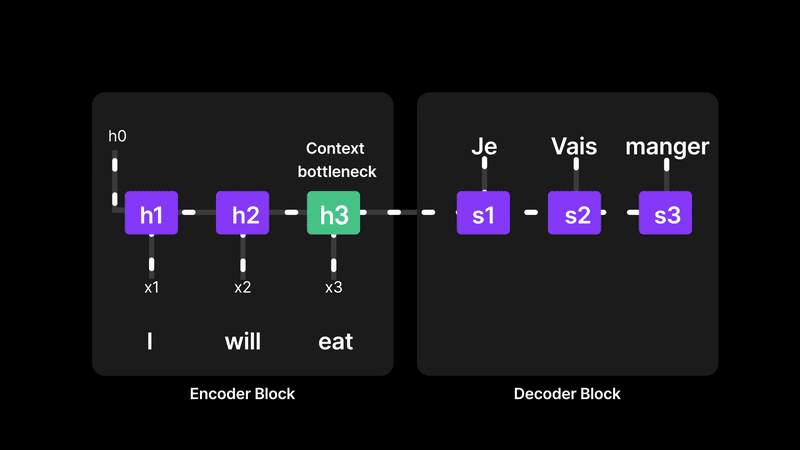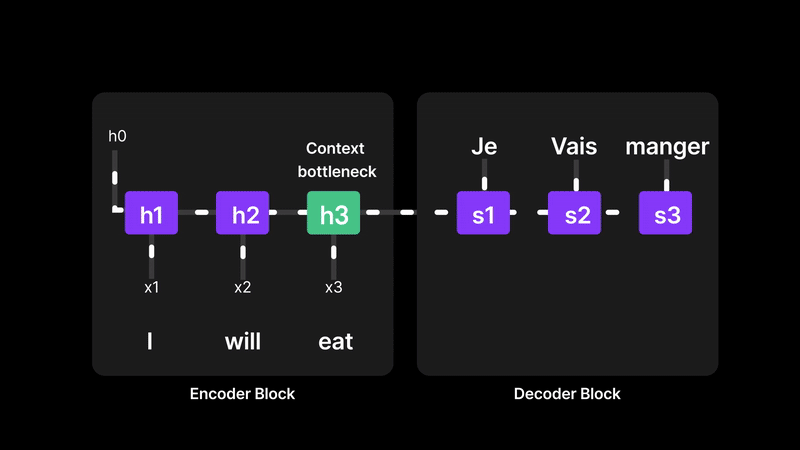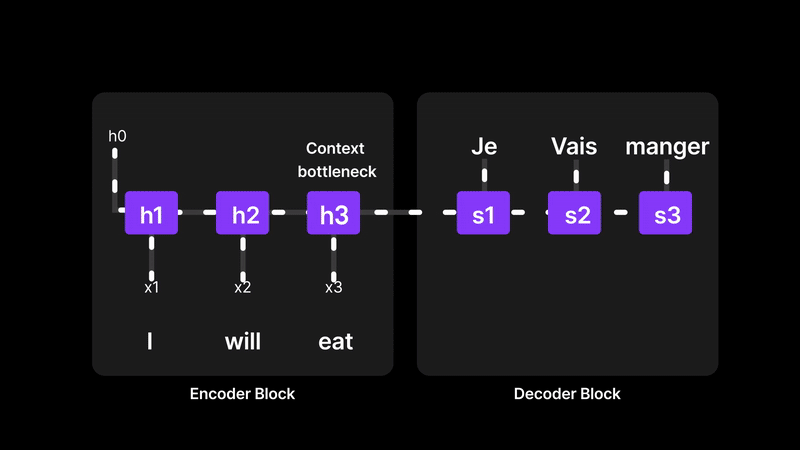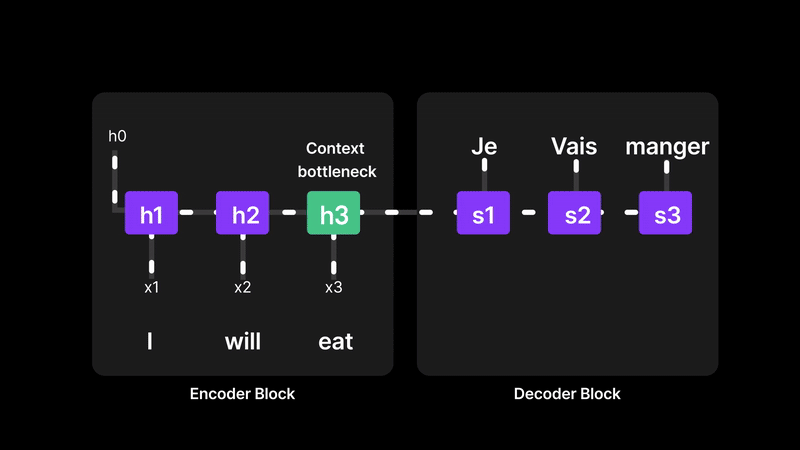 Figure 6: RNNs struggle with long-term memory due to the context bottleneck
Figure 6: RNNs struggle with long-term memory due to the context bottleneck
RNNs compress the entire input sequence into a single final hidden state, which acts as the "context" for generating the output. This creates a context bottleneck, making it hard to retain and recall information from earlier parts of long sequences. As a result, RNNs often struggle with long-range dependencies.
LSTMs: A Step Forward, But Not Far Enough
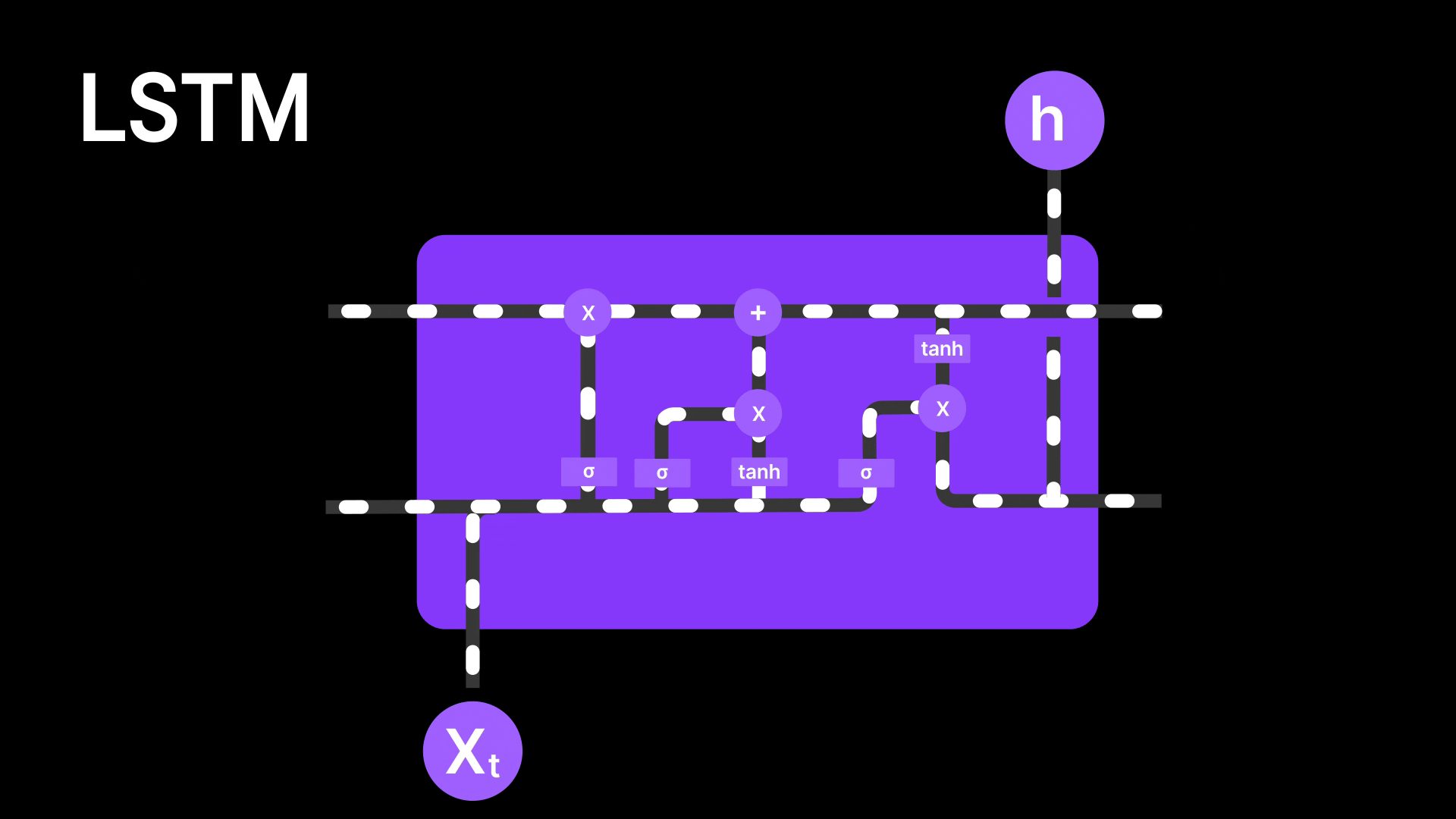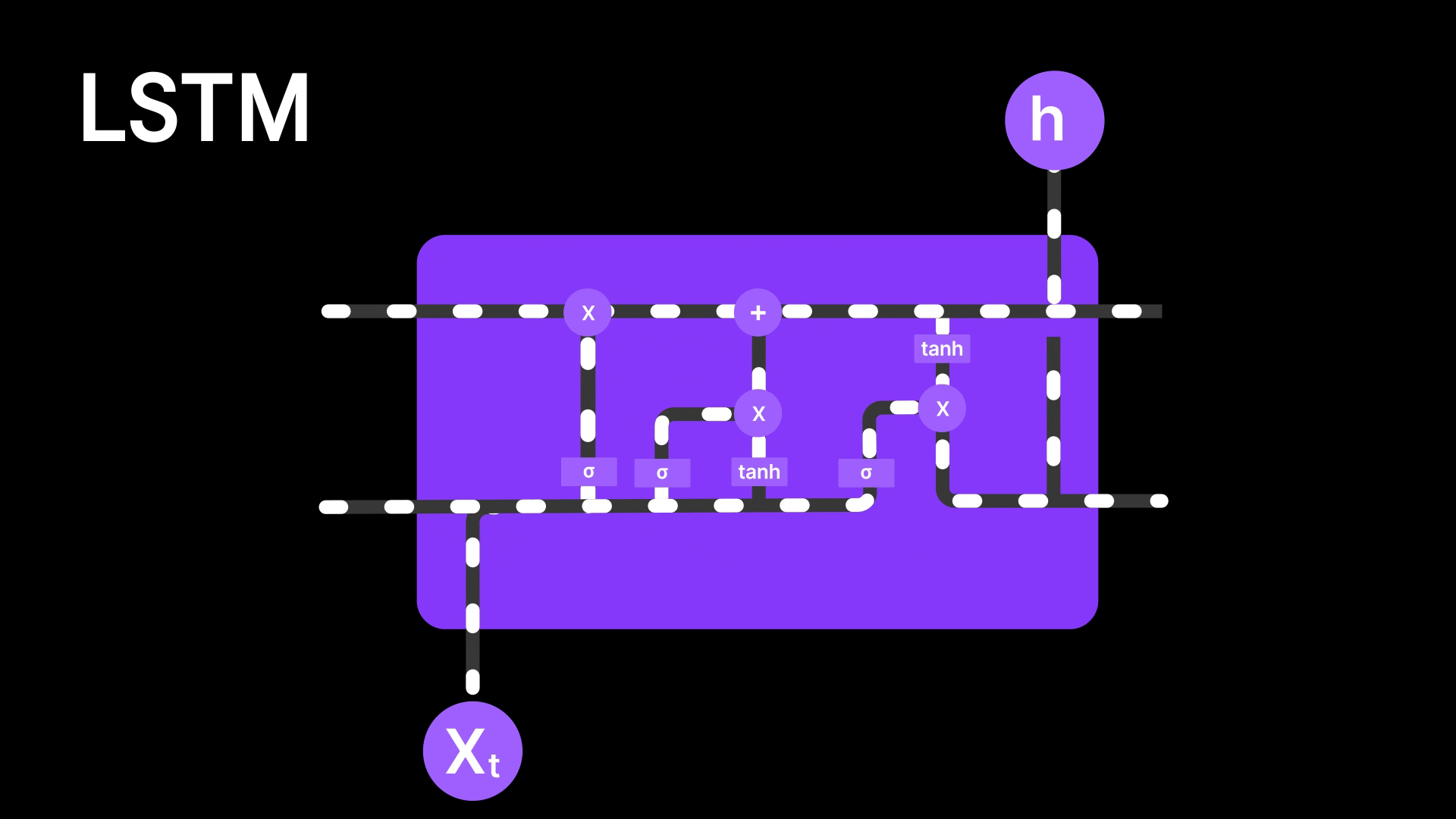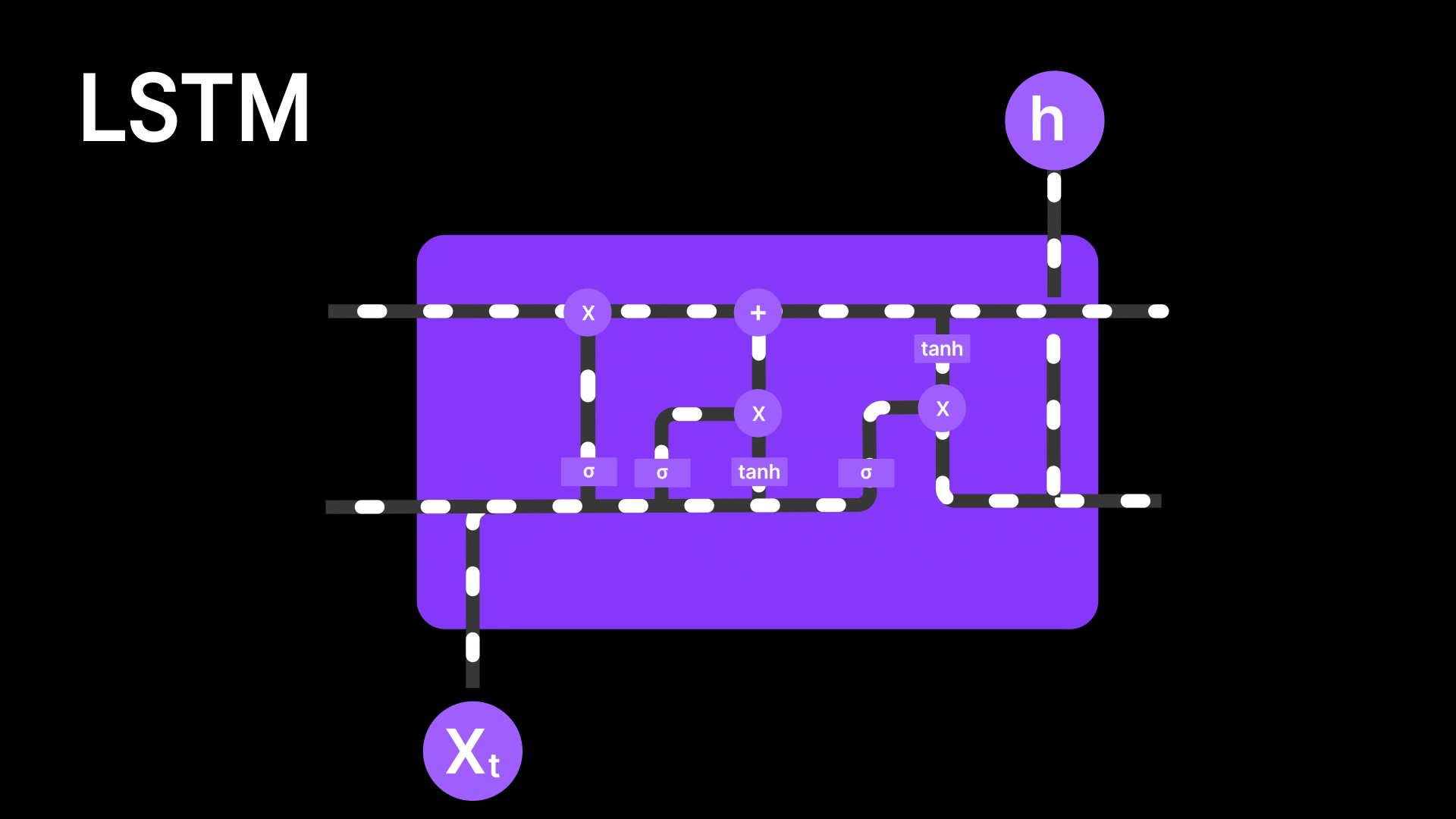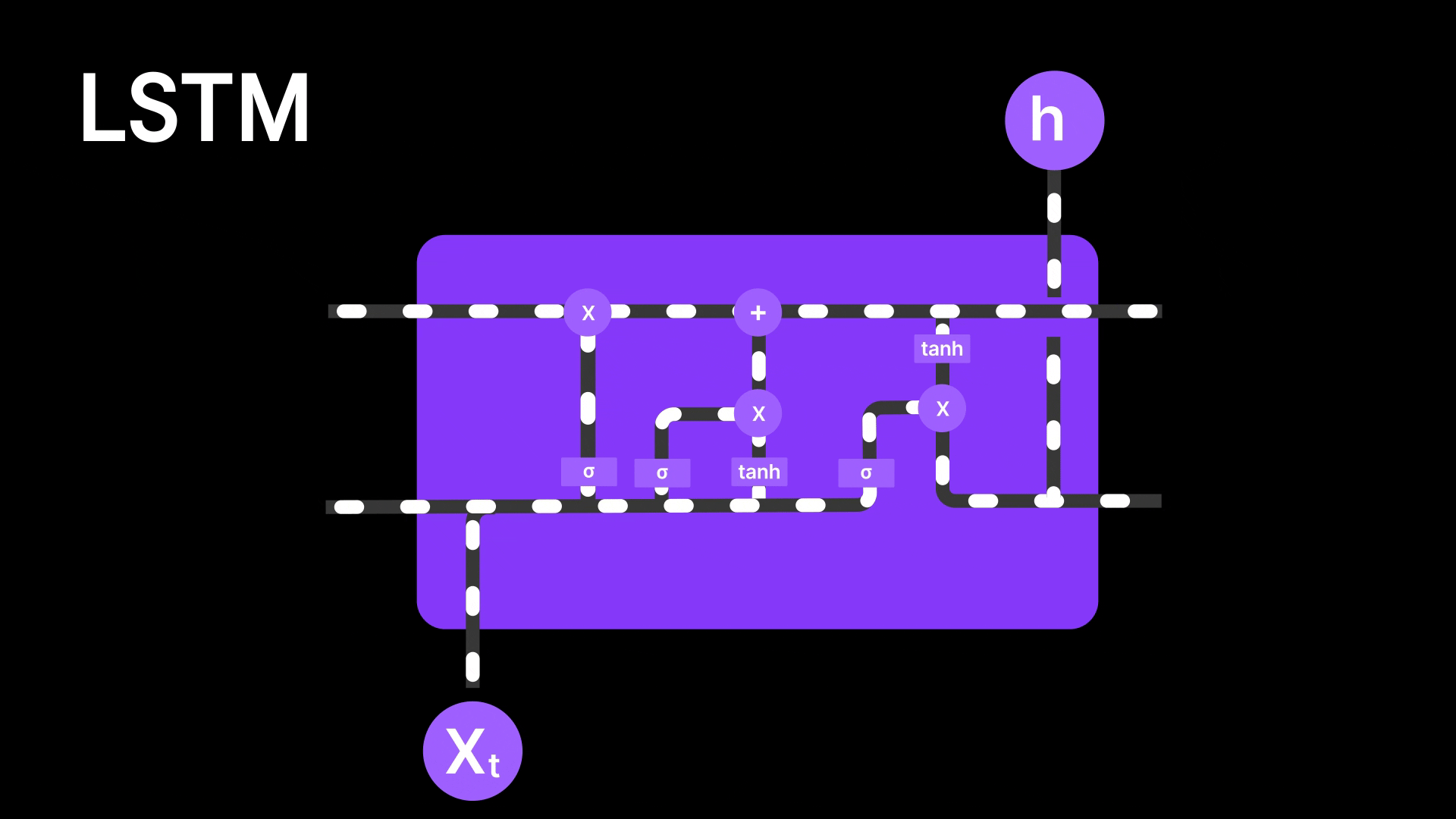 Figure 7: LSTM Architecture
Figure 7: LSTM Architecture
LSTMs are better than basic RNNs because they use a special memory called the cell state to remember information for longer periods. This helps capture both short-term and long-term patterns. But even LSTMs still pass information step by step through the sequence, meaning the earlier words still have to survive a long chain of updates to influence the final output. In long sentences or complex tasks, important details can still get diluted or lost along the way. So while LSTMs reduce the forgetting problem, they don’t completely solve it—they still struggle to focus on specific parts of the input when needed, and thus Attention Mechanism solves the problem.
What Exactly is a “Context Window”?
Before we dive into the Attention Mechanism, let’s take a moment to understand what a context window really means — it’s a key concept that sets the stage for everything that follows.
 Figure 8: Here we have a context window of 5
Figure 8: Here we have a context window of 5
A context window defines the part of the input sequence that a model can focus on at any given time. Think of it like reading a long paragraph but only paying attention to a few words at a time while blocking out the rest.
For example, when translating a sentence, your mind doesn’t process the entire paragraph at once—it selectively focuses on just a small section, translates it, and then moves forward to the next section. Everything outside this window is temporarily ignored. This is exactly how models work:
- At each step, they decide which words to focus on (inside the context window).
- They mask out everything else as irrelevant for that moment.
- Once that part is processed, they shift focus to the next section of words.
This approach helps manage complexity, but it also limits how much information can be considered at once, which is why older models like RNNs and LSTMs struggled with long sentences. The Attention Mechanism solves this by allowing the model to look at all words and dynamically adjust focus based on importance.
Attention Mechanism
 Figure 9: Attention checks all the words to understand the meaning better.
Figure 9: Attention checks all the words to understand the meaning better.
This is where the attention mechanism becomes powerful. Instead of depending only on the last hidden state, attention looks at all the words in the input and decides how important each word is when predicting the next word. For example, imagine the model is translating a sentence and realizes that the first word is the most important for the current translation step. It might assign 80% importance to the first word, 10% to the second, and 10% to the third. This way, even if the input is long, the model can selectively focus on the most relevant parts of the sentence—just like how we pay more attention to certain words when trying to understand a sentence.
 Figure 10: How much importance to give to other words
Figure 10: How much importance to give to other words
In traditional RNNs, the decoder relies only on the final hidden state, which creates a context bottleneck. The Attention Mechanism solves this by allowing the model to focus on all hidden states instead of just the last one.
Instead of treating every past word equally, attention assigns importance scores (α values) to each hidden state. These scores decide how much influence each word should have when predicting the next word.
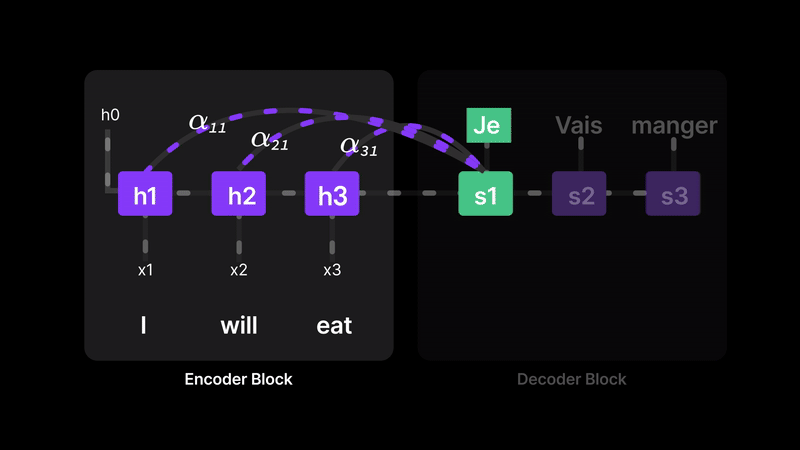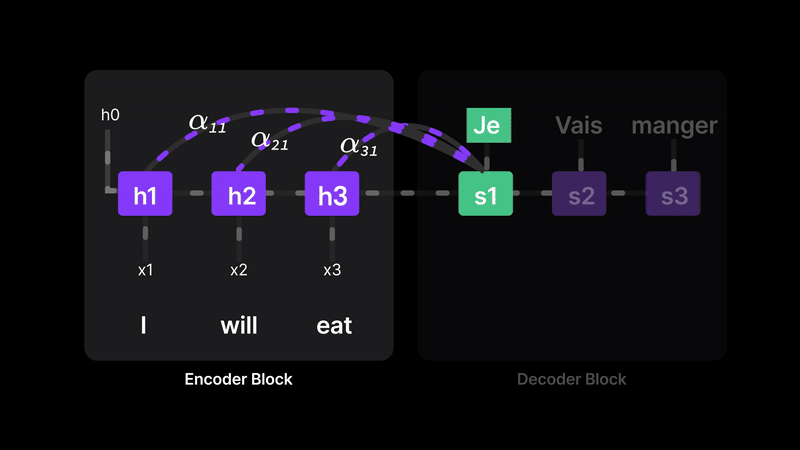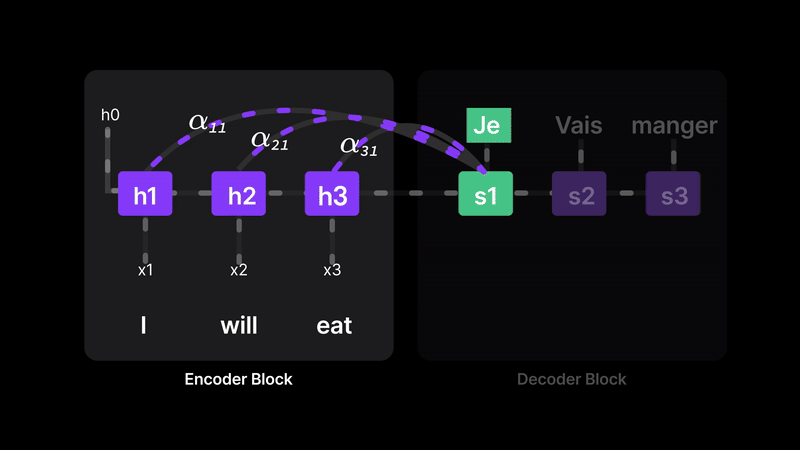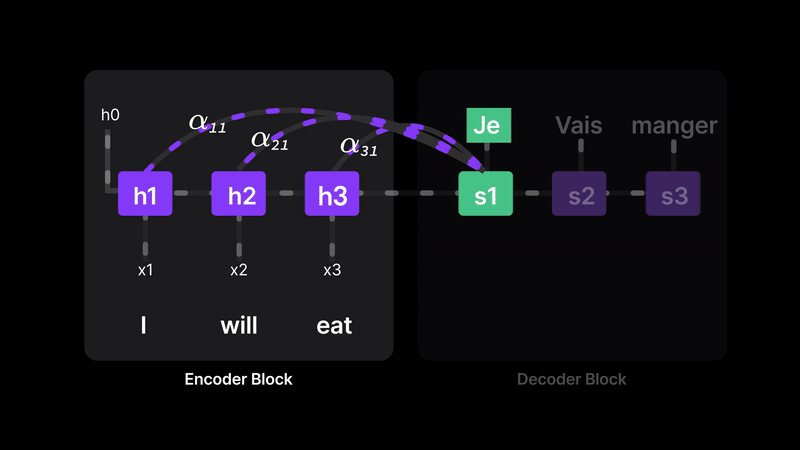 Figure 11: Attention lets the model choose which words matter most for each translation.
Figure 11: Attention lets the model choose which words matter most for each translation.
For example, when decoding the first token, we assign:
- α₁₁ = 100% (full focus on H1)
- α₂₁ = z% (some weight on H2)
- α₃₁ = 0% (ignore H3)
This means the model isn’t blindly trusting H3 anymore—it dynamically selects relevant parts of the input. Every word gets a chance to contribute, and the model learns how much attention to pay at each step.
In short, attention removes the bottleneck by letting the decoder directly access earlier words and quantify their importance, leading to more accurate and context-aware predictions.
Bahdanau Attention
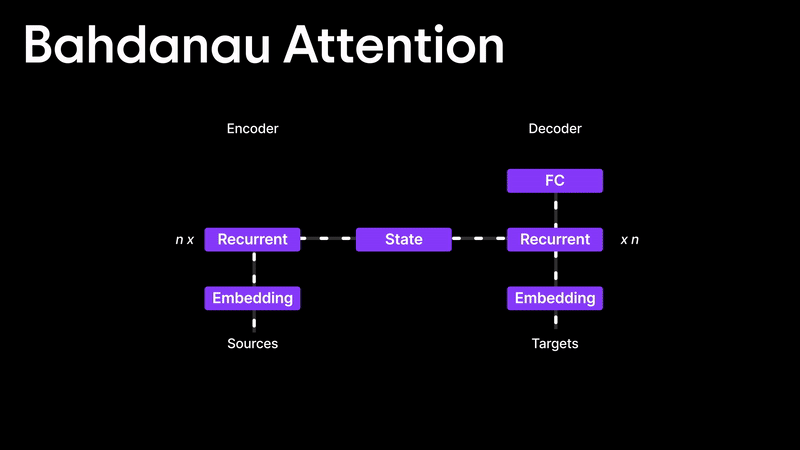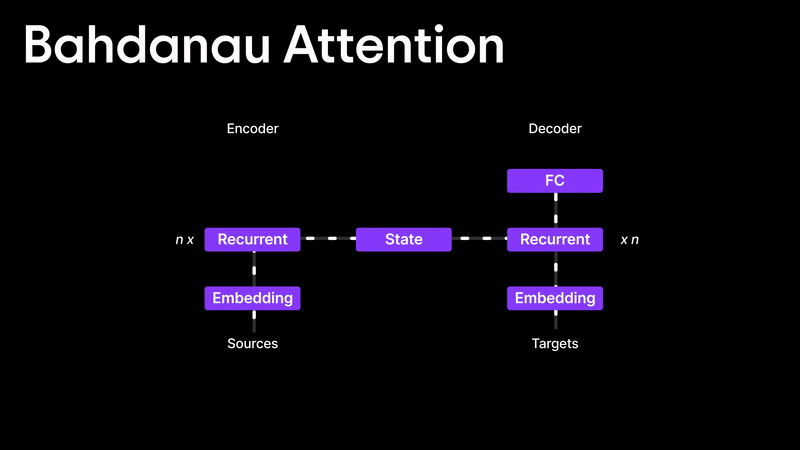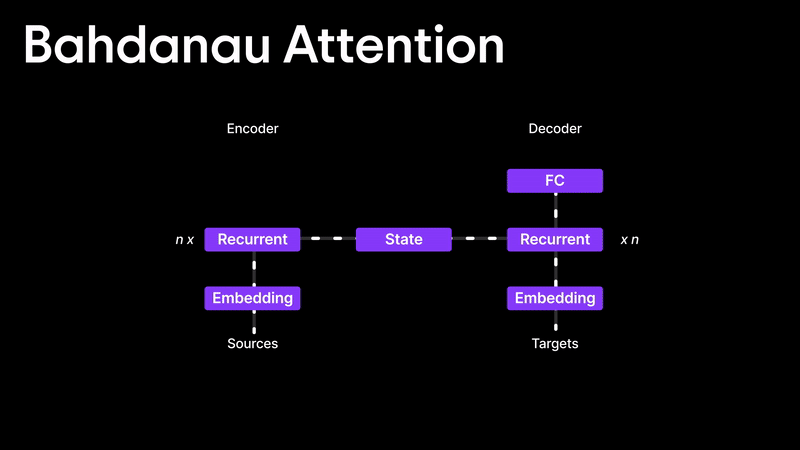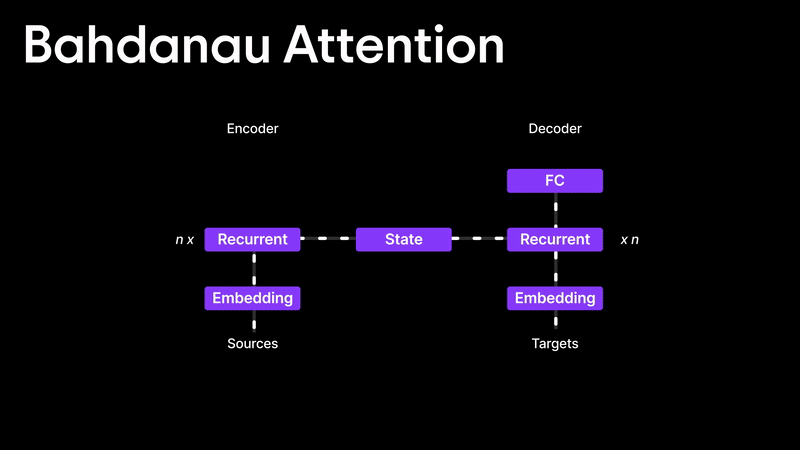
Many people think the Attention Mechanism was introduced in the famous "Attention is All You Need" paper, but that’s not true! The first real implementation of attention came from the Bahdanau Attention paper, published in 2014 and later presented at ICLR 2015.
Link of the paper: https://arxiv.org/pdf/1409.0473
So, what was the problem they were trying to solve?
 Figure 13: First Glimpse of Attention: Bahdanau Attention
Figure 13: First Glimpse of Attention: Bahdanau Attention
Before attention, translation models like RNNs and LSTMs struggled because they relied only on the final hidden state, making it difficult to handle long sentences. Bahdanau and his team introduced a way to dynamically decide how much importance to give to each hidden state instead of relying on just the last one.
They introduced attention scores (A1, A2, A3, etc.), which assign different weights to different words in the input sequence. This means:
- Instead of using only the last hidden state, the model looks at all previous hidden states.
- It then assigns different importance scores to each word, deciding which ones are more relevant for the current translation step.
- This allowed better sequence-to-sequence translation, as the model could selectively focus on important words, improving accuracy.
Bahdanau Attention was a game-changer because it proved that attention could help solve the context bottleneck and make neural machine translation far more effective.
 Figure 14: Attention Heatmap for French-to-English Sentence Translation
Figure 14: Attention Heatmap for French-to-English Sentence Translation
One of the biggest challenges in translation is that different languages don’t follow the same word order. In English, we say "European Economic Area", but in French, it translates as "zone économique européenne", where the order of words changes. Traditional models that rely on fixed word positions struggle with this, but Bahdanau Attention solves it by dynamically aligning words based on meaning rather than position.
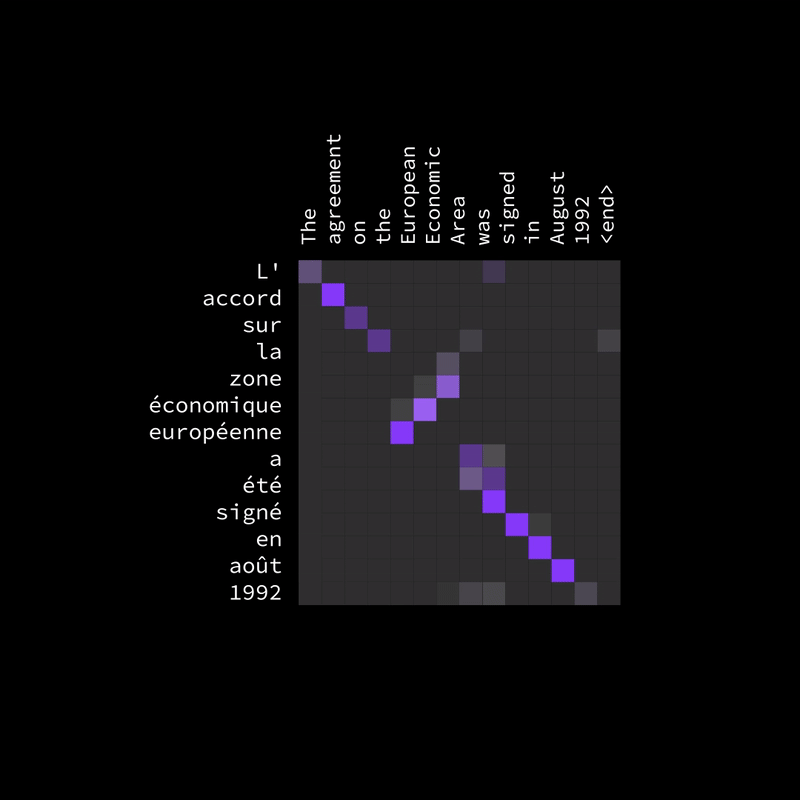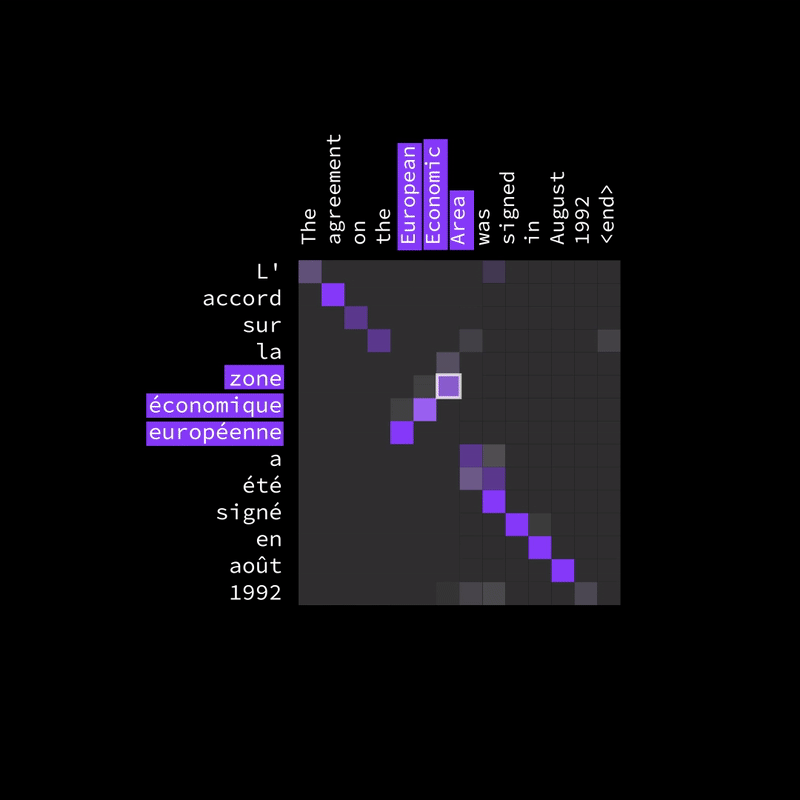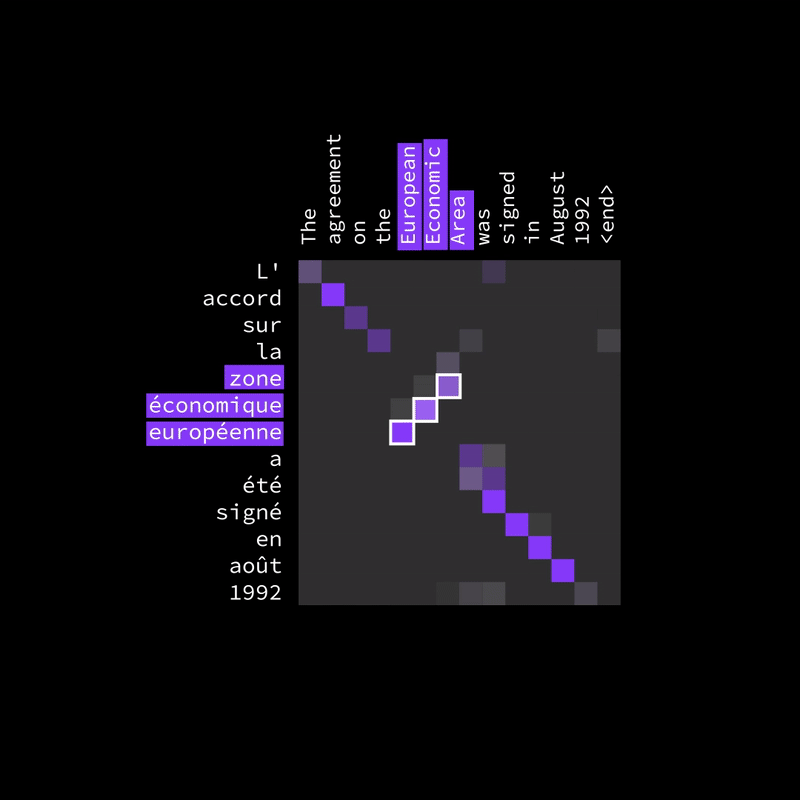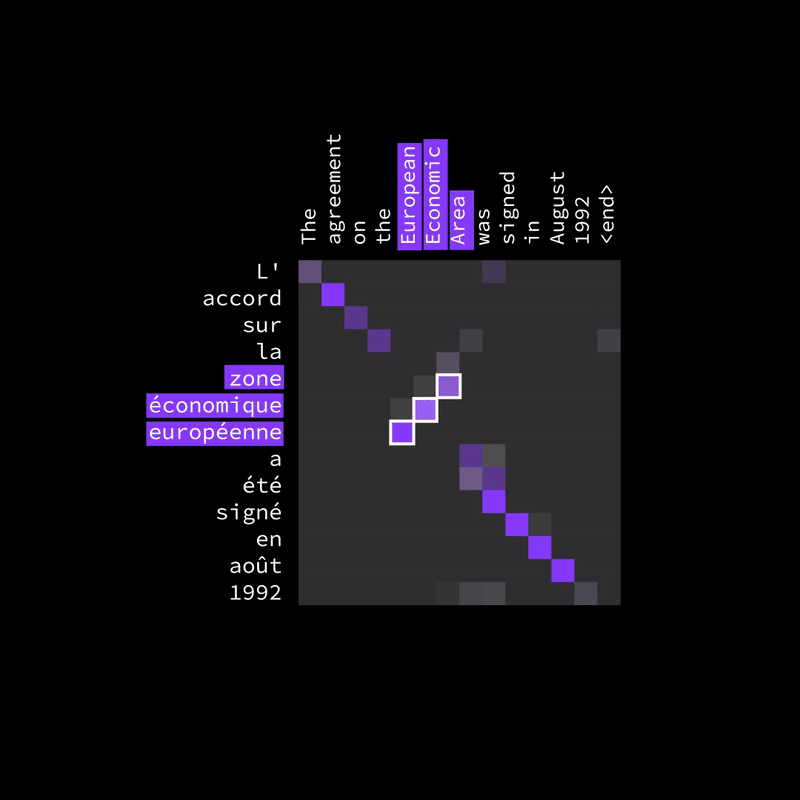 Figure 15: Different languages don’t follow the same word order.
Figure 15: Different languages don’t follow the same word order.
The attention heatmap (as shown in the image) highlights which words in the input (English) are most relevant to each translated word in the output (French). While some words align diagonally (meaning they appear in the same order), others shift off the diagonal, capturing how words rearrange naturally in translation. This flexibility allows the model to correctly map words even when their positions change, leading to more accurate and natural translations.
The Evolution of Attention: From Bahdanau to Transformers and GPT
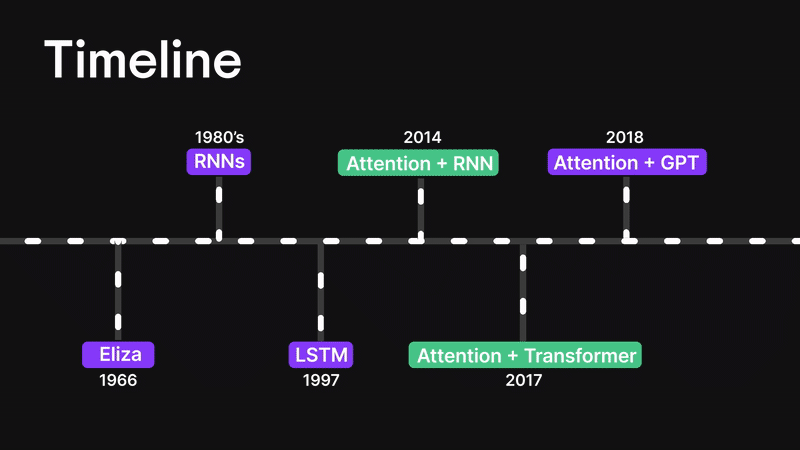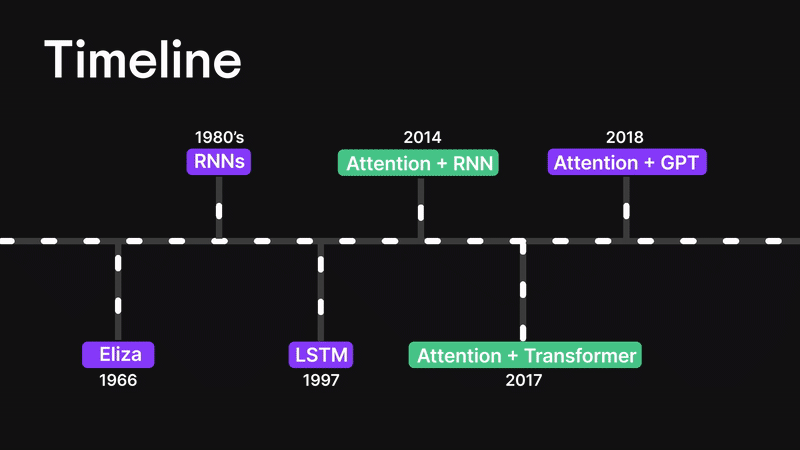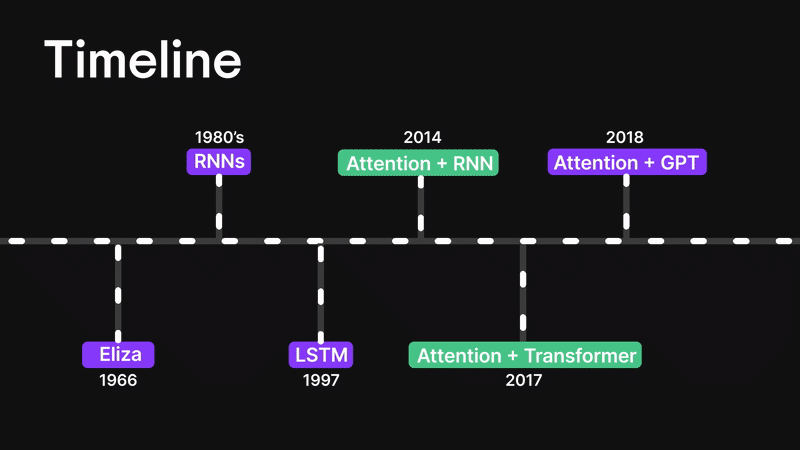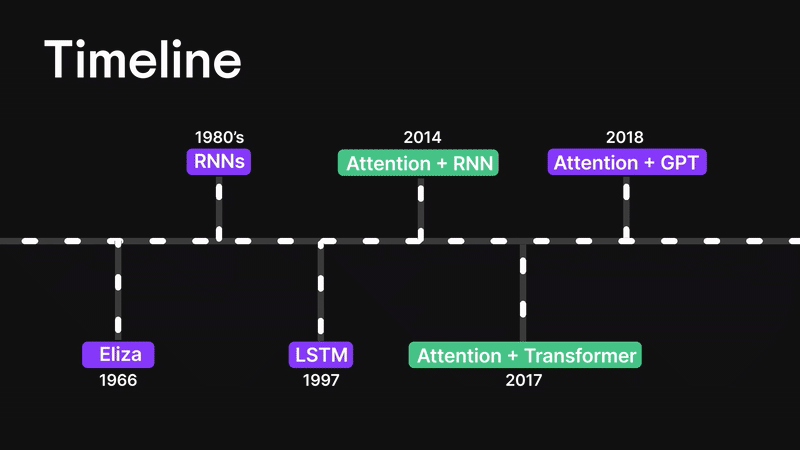 Figure 16: In 2014, Bahdanau introduced the concept of Attention combined with RNNs. Just a few years later, in 2017, the paper “Attention Is All You Need” replaced RNNs entirely—introducing Transformers powered solely by Attention.
Figure 16: In 2014, Bahdanau introduced the concept of Attention combined with RNNs. Just a few years later, in 2017, the paper “Attention Is All You Need” replaced RNNs entirely—introducing Transformers powered solely by Attention.
In the previous section, we explored Bahdanau Attention, the first major use of the attention mechanism in machine translation. But at that time (2014), attention was still used alongside RNNs—it helped improve context retention, but the model still depended on sequential processing.
Three years later, in 2017, researchers made a groundbreaking discovery: RNNs were no longer necessary for deep NLP models. Instead, they introduced the Transformer architecture in the famous "Attention is All You Need" paper. This was a huge shift because it removed RNNs entirely and used only the attention mechanism for learning long-range dependencies. So, while
Bahdanau Attention (2014) = Attention + RNNs
Transformer (2017) = Attention + Transformer Blocks (no RNNs).
Then, in 2018, GPT (Generative Pre-trained Transformer) was introduced. While the original Transformer model had both an encoder and a decoder, GPT modified this by using only the decoder—focusing purely on generating text. However, the core idea remained the same: attention is the key component that enables powerful language models.
To summarize the progression:
- 2014 (Bahdanau Attention) → Attention + RNN (helped with sequence-to-sequence translation).
- 2017 (Transformers) → RNNs removed, Attention fully integrated into the Transformer architecture.
- 2018 (GPT) → Transformer-based models evolved further, keeping only the decoder for generating text.
This journey highlights how attention became the foundation of modern NLP, eventually leading to the powerful models we use today.
What’s Next: Enter Self-Attention
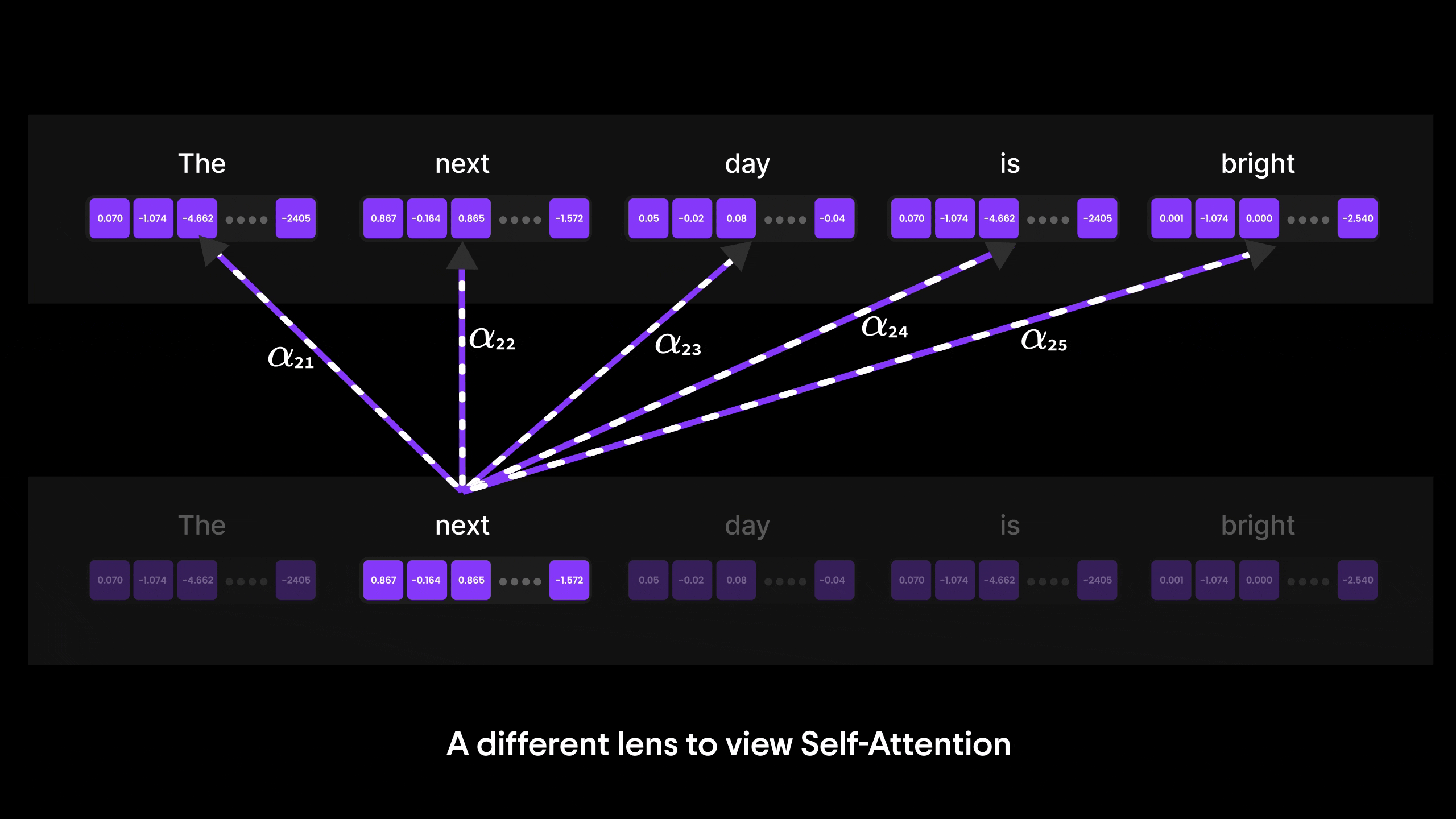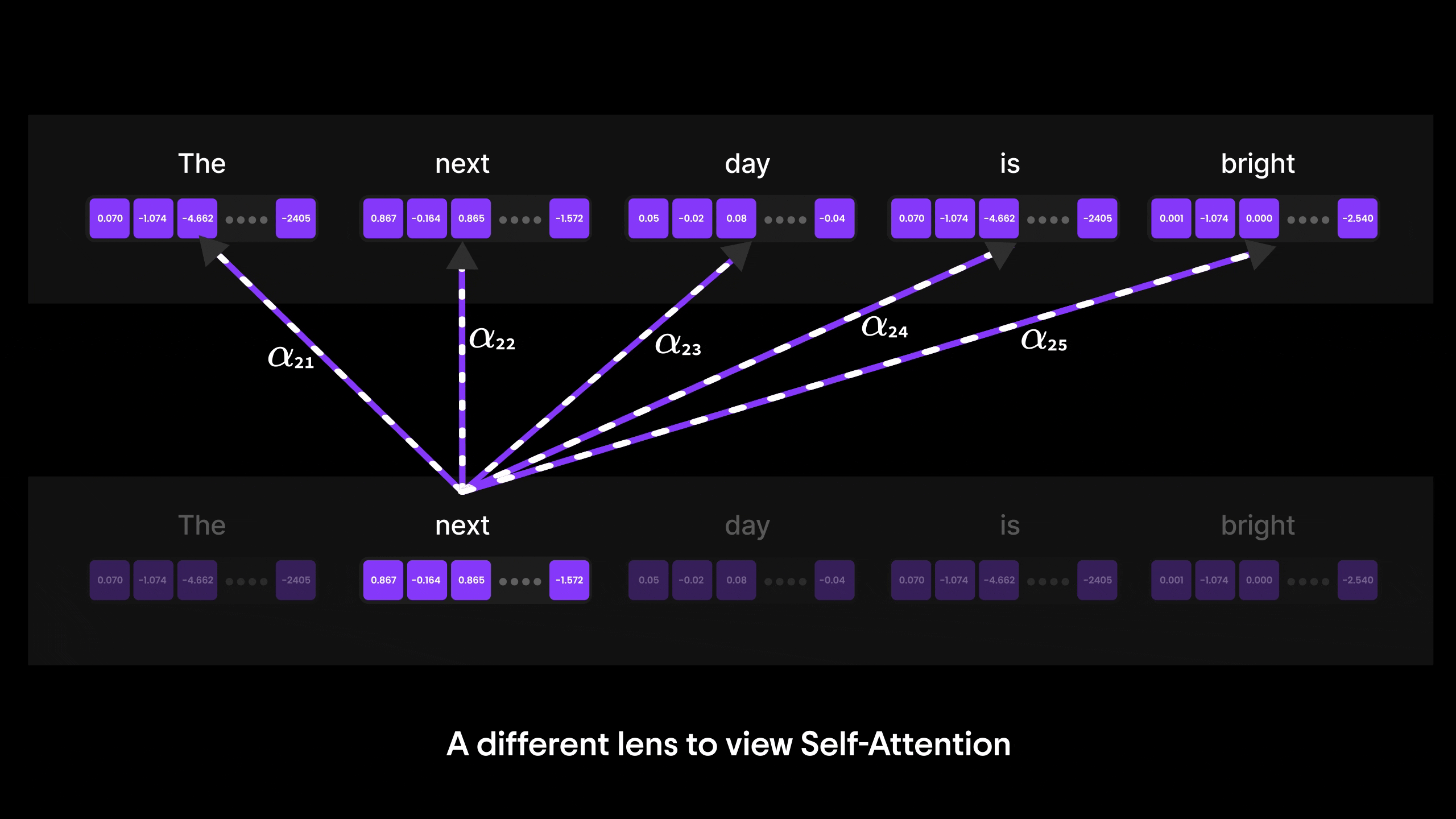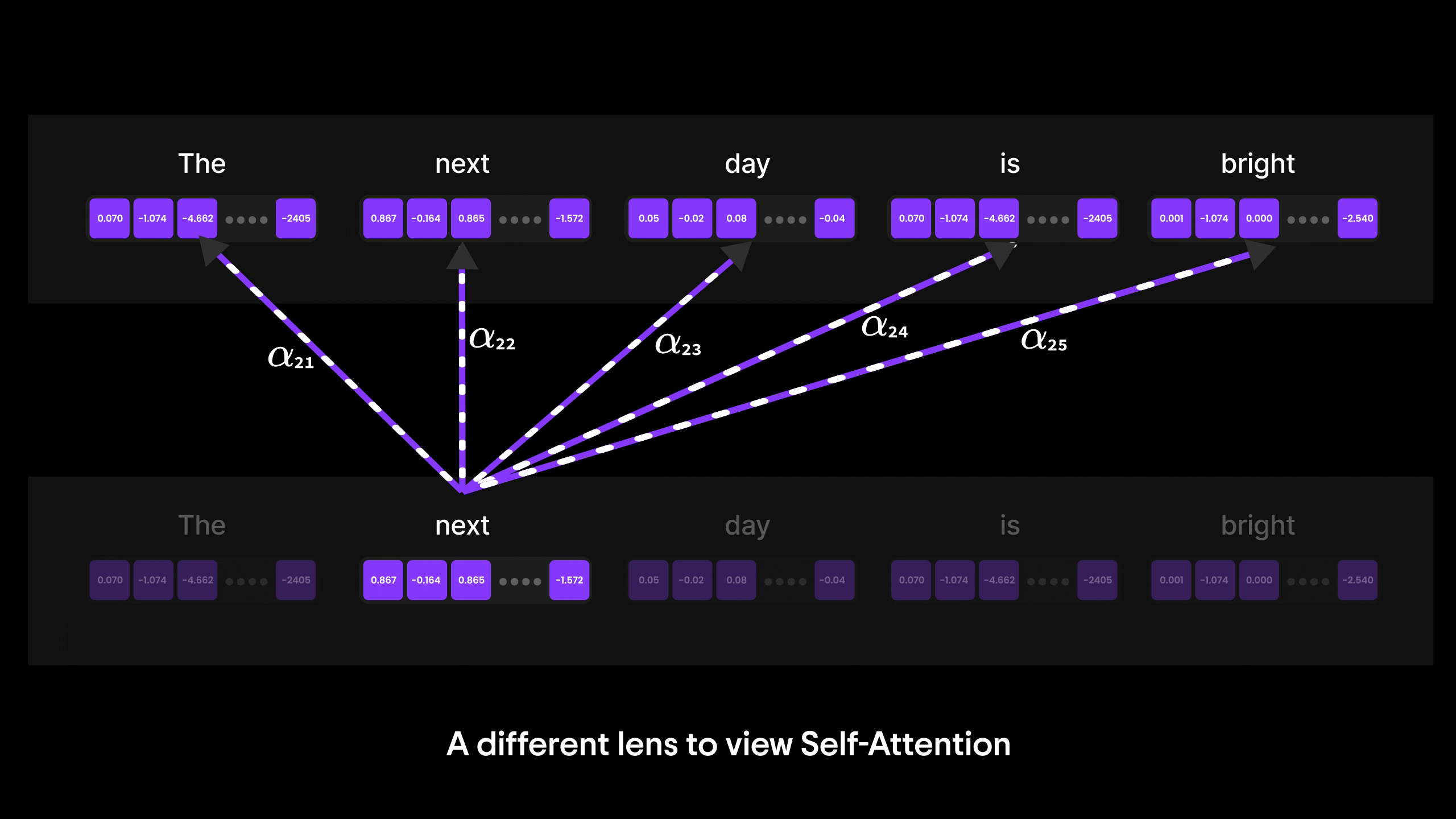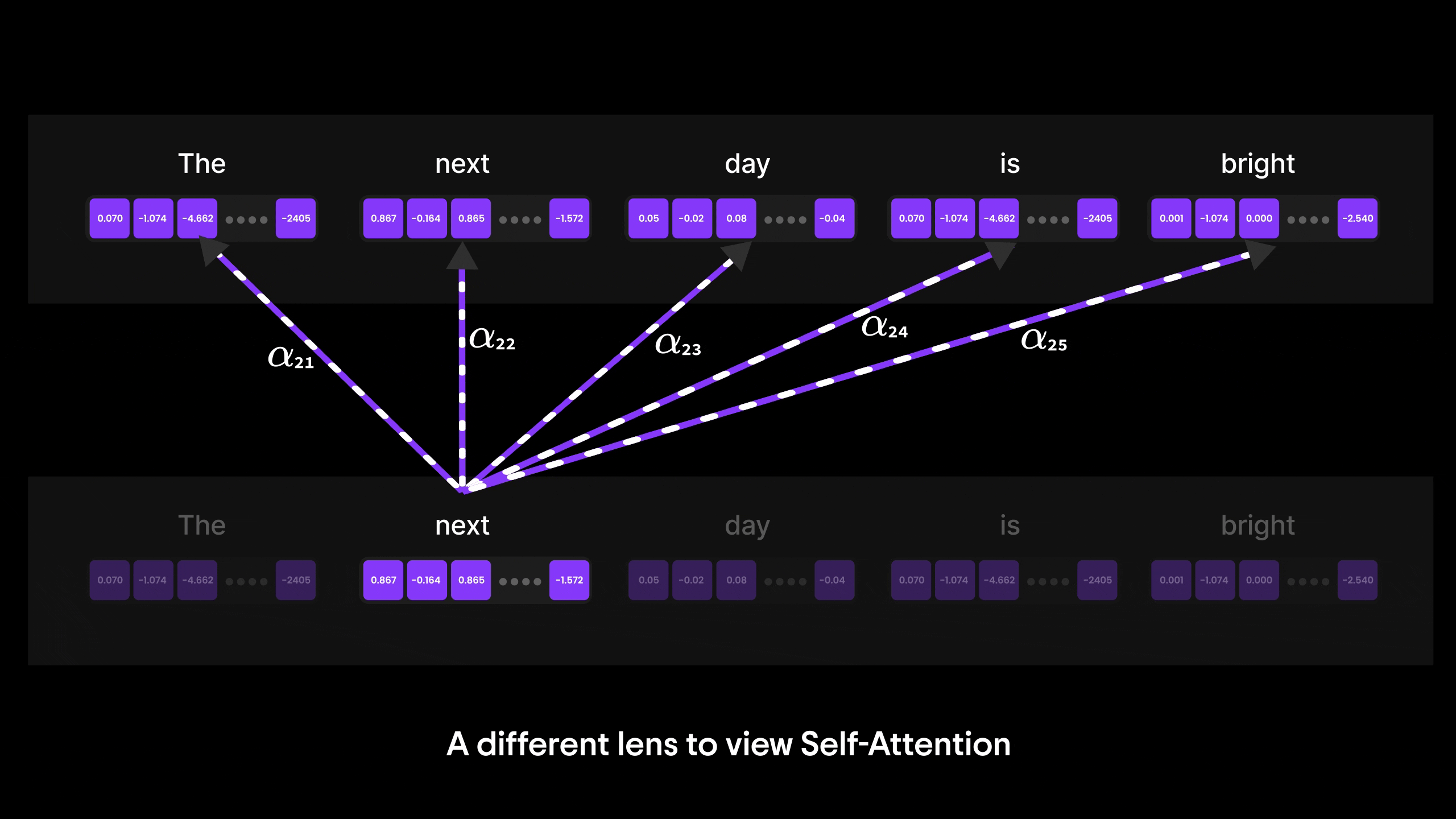 Figure 17: A deep dive into Self-Attention
Figure 17: A deep dive into Self-Attention
While Bahdanau Attention was a major breakthrough, it still relied on RNNs and their step-by-step processing, which limited parallelization and efficiency. This is where Self-Attention takes the spotlight.
In the next blog, we’ll explore how Self-Attention overcomes these limitations by allowing every word to directly attend to every other word in a sequence—regardless of position—without relying on RNNs. It’s the core innovation behind Transformers and the foundation of models like GPT.
Stay tuned as we dive into how Self-Attention works and why it transformed the future of NLP.
Conclusion
The goal of this blog was to understand why the Attention Mechanism was introduced and how it revolutionized the way we handle sequential data in natural language processing.
We began by looking at Artificial Neural Networks (ANNs) and their major limitation: they treat every input independently, lacking any awareness of order or context. This made them unsuitable for tasks like language modeling or translation, where the sequence of words deeply matters.
To address this, Recurrent Neural Networks (RNNs) were introduced. They added a sense of memory by passing information from one step to the next, helping models learn patterns over time. However, RNNs hit a wall when dealing with long sequences. They compress the entire input into a single final hidden state—leading to a context bottleneck, where earlier inputs can be easily forgotten.
LSTMs improved this by introducing a better memory mechanism (the cell state), allowing the model to remember information over longer spans. Yet, LSTMs still processed data sequentially and struggled to selectively focus on the most relevant parts of long inputs.
That’s where Bahdanau Attention made a major breakthrough. Instead of depending on a single memory vector, it enabled the model to dynamically decide which words in the input sequence were most important at each output step. This combination of Attention + RNNs significantly improved tasks like machine translation by removing the rigid bottleneck and introducing soft alignment between input and output sequences.
To sum it up:
- ANNs couldn’t handle sequences.
- RNNs introduced memory but struggled with long-range dependencies.
- LSTMs helped retain information longer but couldn’t focus selectively.
- Bahdanau Attention + RNNs solved the focus issue but still relied on step-by-step processing.
In our next blog, we’ll take a leap forward and introduce Self-Attention—the core idea behind Transformers. Self-Attention removes the need for RNNs entirely, allows parallel processing, and lets each word in a sequence attend to every other word directly. It’s the concept that powers today’s most powerful models like GPT.
I’m also building ML, MLOps and LLM projects, sharing and discussing them on LinkedIn and Twitter. If you’re someone curious about these topics, I’d love to connect with you all!
LinkedIn : mayankpratapsingh022
Twitter/X : Mayank_022
Thanks for joining the journey so far.